TRI:預訓練的大型行為模型加速機器人學習


兩臺協作機器人使用從微調的大型行為模型(LBMs)中獲得的自主評估部署來執行長時程行為,例如安裝自行車轉盤。| 來源:豐田研究院
豐田研究院(TRI)本周發布了其關于大型行為模型(LBMs)的研究結果,這些模型可用于訓練通用機器人。該研究顯示,單個 LBM 可以學習數百個任務,并利用先驗知識以 80%更少的訓練數據獲取新技能。
LBMs 在大型、多樣化的操作數據集上進行預訓練。盡管它們越來越受歡迎,但機器人社區對 LBMs 實際上能提供什么仍然知之甚少。TRI 的工作旨在通過這項研究揭示算法和數據集設計方面的最新進展。
總體而言,TRI 表示其發現大體上支持了近期 LBM 風格機器人基礎模型的熱度激增,并補充了大規模在多樣化機器人數據上進行預訓練是通往更強大機器人的可行路徑的證據,盡管存在一些需要注意的方面。
通用型機器人承諾一個未來,即家用機器人可以提供日常協助。然而,我們尚未達到任何機器人都能處理普通家庭任務的階段。TRI 表示,LBMs,即輸入機器人傳感器數據并輸出動作的具身 AI 系統,可能會改變這一點。
2024 年,TRI 因其快速機器人教學 LBMs 的工作贏得了機器人創新獎 。
TRI 研究發現的概述
TRI 在近 1700 小時的機器人數據上訓練了一系列基于擴散的 LBMs,并進行了 1800 次真實世界的評估部署和超過 47000 次模擬部署,以嚴格研究它們的性能。它發現 LBMs:
相對于從頭開始制定的策略,能夠持續提升性能
在需要抵抗各種環境因素的挑戰性環境中,能夠以3-5倍更少的數據量學習新任務
隨著預訓練數據的增加,性能穩步提升
即使只有幾百小時多樣化的數據,并且每個行為只有幾百個演示,性能也顯著提升,TRI 表示。預訓練在比預期更早的規模上提供了持續的性能提升。目前還沒有一個值得注意的機器人數據量,但收益在達到那個規模之前就已經顯現——這對于實現數據獲取和自舉性能的良性循環是一個有希望的跡象,TRI 聲稱。
TRI 的評估套件包括幾個新穎且極具挑戰性的長時程真實世界任務;在這種設置下微調和評估,LBM 預訓練提高了性能,盡管這些行為與預訓練任務高度不同。
在 TRI 的 LBMs 的架構和數據中
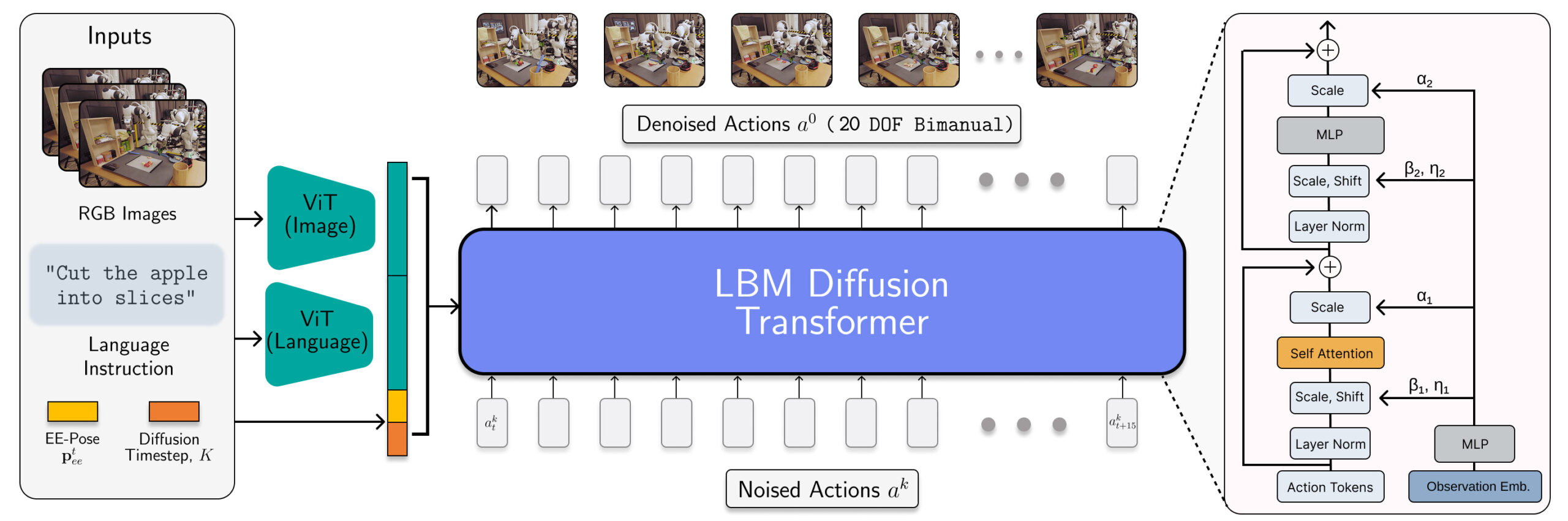
LBM 架構被實例化為一個擴散 Transformer,用于預測機器人動作。| 來源:豐田研究院
TRI 的 LBMs 是具有多模態 ViT 視覺語言編碼器和基于 AdaLN 條件編碼觀測值的 Transformer 去噪頭的多任務擴散策略。這些模型消耗手腕和場景相機、機器人本體感覺和語言提示,并預測 16 個時間步長(1.6 秒)的動作片段。
研究人員在 468 小時內部部收集的雙臂機器人遙操作數據、45 小時模擬收集的遙操作數據、32 小時通用操作界面(UMI)數據以及從 Open X-Embodiment 數據集精心策劃的約 1150 小時互聯網數據上訓練了 LBMs。
雖然模擬數據的比例很小,但將其包含在 TRI 的預訓練混合中,確保它可以評估相同的 LBM 檢查點,無論是在模擬還是真實環境中。
TRI 的評估方法
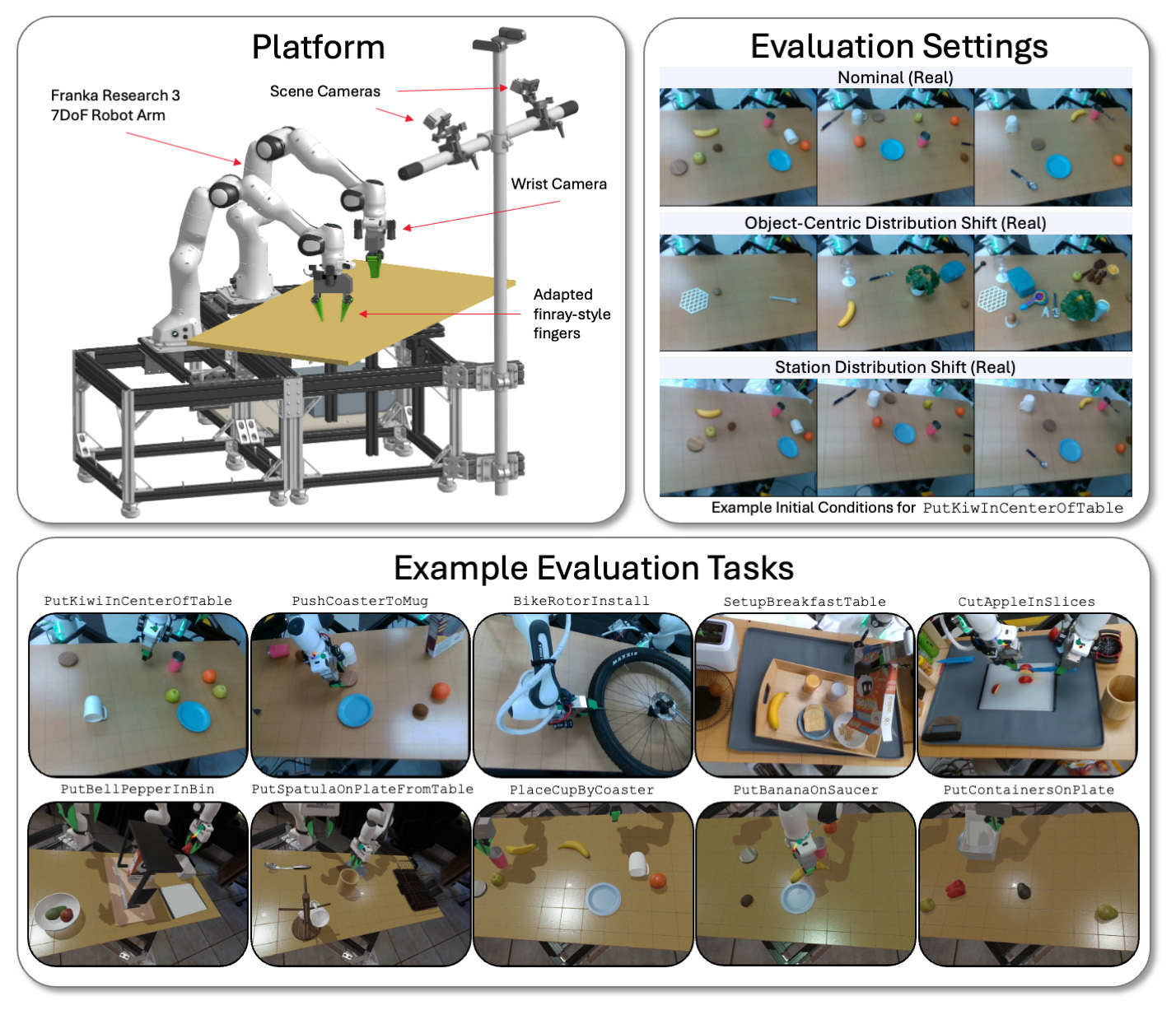
TRI 在模擬和現實世界中,使用雙臂平臺在各種任務和環境條件下評估其 LBM 模型。 | 來源:豐田研究院
TRI 在使用 Franka Panda FR3 機械臂和最多六個攝像頭的物理和 Drake 模擬雙臂工作站上評估其大型行為模型(LBMs)——每只手腕最多兩個攝像頭,以及兩個靜態場景攝像頭。
TRI 在已見任務(存在于預訓練數據中)和未見任務(TRI 用于微調其預訓練模型的任務)上評估模型。TRI 的評估套件包括 16 個在預訓練期間模擬的已見任務、3 個真實世界的已見任務、5 個之前未見的長時程模擬任務和 5 個復雜的之前未見的長時程真實世界任務。
每個模型都通過每個真實世界任務50次運行和每個模擬任務200次運行進行測試。這使我們的分析具有高度統計學意義,預訓練模型在29個任務上進行了4200次運行評估。
TRI 表示它仔細控制初始條件,以確保在現實世界和模擬中保持一致。它還在現實世界中進行盲法 A/B 風格的測試,并通過順序假設檢驗框架計算統計顯著性。
許多研究人員觀察到的效應只有在比標準更大的樣本量和仔細的統計測試中才能測量,而這種統計測試在實證機器人學中并不標準。由于實驗變化的噪聲很容易掩蓋所測量的效應,許多機器人學論文可能是在測量由于統計能力不足而產生的統計噪聲。
TRI 從研究中得出的主要結論
團隊的主要結論之一是,微調性能隨著預訓練數據的增加而平穩提高。在我們考察的數據規模下,TRI 沒有發現性能斷點或明顯的拐點;人工智能的擴展在機器人領域依然有效。
TRI 在非微調的預訓練大型行為模型上經歷了混合結果。令人鼓舞的是,它發現單個網絡能夠同時學習許多任務,但它沒有觀察到從頭開始的單任務訓練在沒有微調的情況下始終具有優勢。TRI 預計這部分是由于其模型的語言引導能力。
在內部測試中,TRI 表示已經看到一些有希望的早期跡象,表明更大的 VLA 原型克服了部分這種困難,但需要更多的工作來嚴格檢驗這種效果在高語言能力模型中的表現。
在注意事項方面,TRI 表示微小的設計選擇,如數據歸一化,可以對性能產生重大影響,往往超過架構或算法的變更。重要的是要仔細隔離這些設計選擇,以避免混淆性能變化的來源。










評論