摩爾線程CEO張建中:萬卡集群是AI主戰場上的標配

「從今天起,世界徹底改變了。」這是 GPT-3 算法的發明人埃德·萊昂·克林格在 GPT-3 出現時說的一句話。
本文引用地址:http://www.104case.com/article/202407/460864.htm這是一個 AI 的時代,這是一個算力的時代。
今日,摩爾線程重磅宣布其 AI 旗艦產品夸娥(KUAE)智算集群解決方案實現重大升級,從當前的千卡級別大幅擴展至萬卡規模。
同時,摩爾線程聯合中國移動通信集團青海有限公司、中國聯通青海公司、北京德道信科集團、中國能源建設股份有限公司總承包公司、桂林華崛大數據科技有限公司,分別就三個萬卡集群項目進行了戰略簽約,多方聚力共同構建好用的國產 GPU 集群。
此外,我們從現場也看到摩爾線程的產品能力和強大的生態鏈接力。與來自清華系兩家公司無問芯穹和清程極智已經開始深度合作,無問芯穹是由清華大學電子工程系系主任汪玉教授發起的,清程極智由清華大學計算機系鄭緯民院士發起的。還有京東、360、智平方等多家國內企業,夸娥智算集群助力其在大模型訓練、大模型推理、具身智能等不同場景和領域的創新。
萬卡是最低標配
大模型自問世以來,關于其未來的走向和發展趨勢亟待時間驗證,但從當前來看,幾種演進趨勢值得關注,使得其對算力的核心需求也愈發明晰。
第一,Scaling Law 將持續奏效。需要單點規模夠大并且通用的算力才能快速跟上技術演進。第二,Transformer 架構不能實現大一統,和其他架構會持續演進并共存,形成多元化的技術生態。第三,AI、3D 和 HPC 跨技術與跨領域融合不斷加速,大模型的訓練和應用環境更加復雜多元。
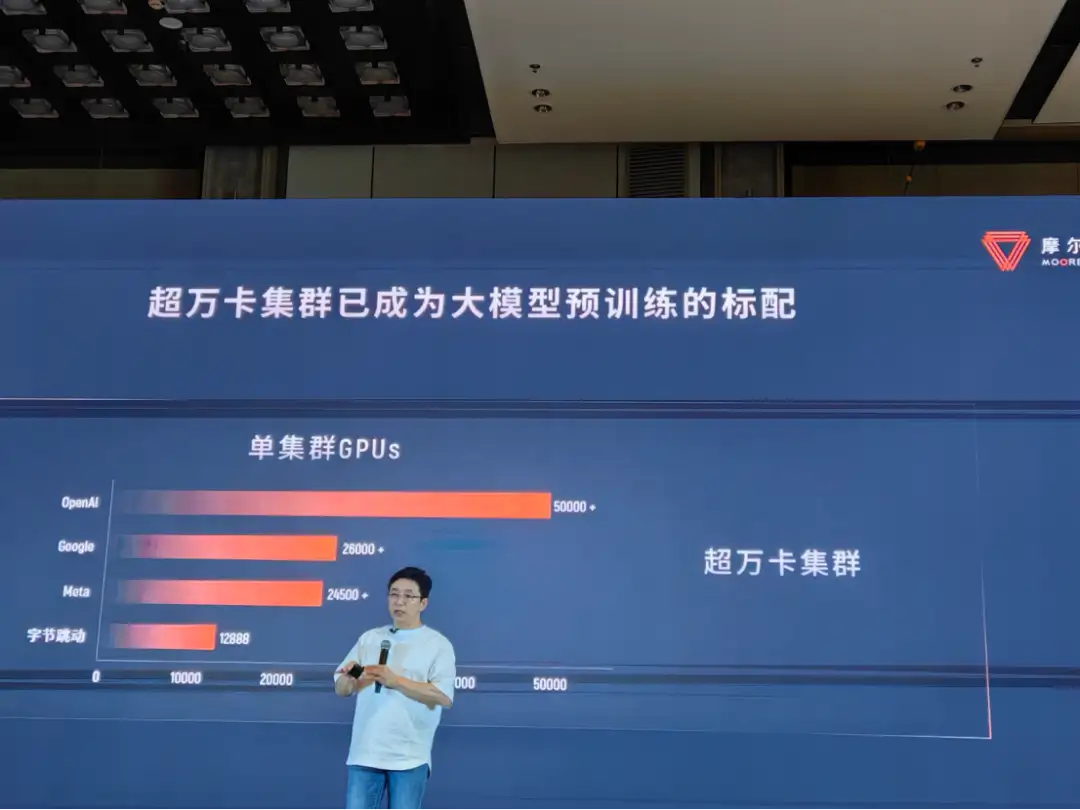
隨著計算量不斷攀升,大模型訓練亟需超級工廠,即一個「大且通用」的加速計算平臺,以縮短訓練時間。以 Llama 3 為例,在它問世之際,Meta 就公布了其基礎設施詳情:「我們在兩個定制的 24K GPU 集群上做訓練。」
摩爾線程創始人張建中提出了一個標準:「AI 主戰場,萬卡是最低標配。」
國產萬卡萬 P 萬億大模型訓練平臺
夸娥(KUAE)是摩爾線程智算中心全棧解決方案,是以全功能 GPU 為底座,軟硬一體化、完整的系統級算力解決方案,包括以夸娥計算集群為核心的基礎設施、夸娥集群管理平臺(KUAE Platform)以及夸娥大模型服務平臺(KUAE ModelStudio),旨在以一體化交付的方式解決大規模 GPU 算力的建設和運營管理問題。

基于對 AI 算力需求的深刻洞察和前瞻性布局,摩爾線程夸娥智算集群可實現從千卡至萬卡集群的無縫擴展,旨在滿足大模型時代對于算力「規模夠大+計算通用+生態兼容」的核心需求,通過整合超大規模的 GPU 萬卡集群、極致的計算效率優化以及高度穩定的運行環境,以萬卡智算集群的新超級工程,重新定義國產集群計算能力的新標準。
夸娥萬卡智算解決方案具備多個核心特性:
超大算力,萬卡萬 P。浮點運算能力達到 10Exa-Flops,大幅提升單集群計算性能,能夠為萬億參數級別大模型訓練提供堅實算力基礎。
超高穩定,月級長穩訓練。在集群穩定性方面,摩爾線程夸娥萬卡集群平均無故障運行時間超過 15 天,最長可實現大模型穩定訓練 30 天以上,周均訓練有效率在 99% 以上,遠超行業平均水平。
極致優化,超高 MFU:實現大模型的高效率訓練,MFU 最高可達到 60%。在系統軟件層面,基于極致的計算和通訊效率優化等技術手段,大幅提升集群的執行效率和性能表現。
全能通用,生態友好:可加速 LLM、MoE、多模態、Mamba 等不同架構、不同模態的大模型。s 同時,基于高效易用的 MUSA 編程語言、完整兼容 CUDA 能力和自動化遷移工具 Musify,加速新模型「Day0」級遷移,實現生態適配「Instant On」,助力客戶業務快速上線。
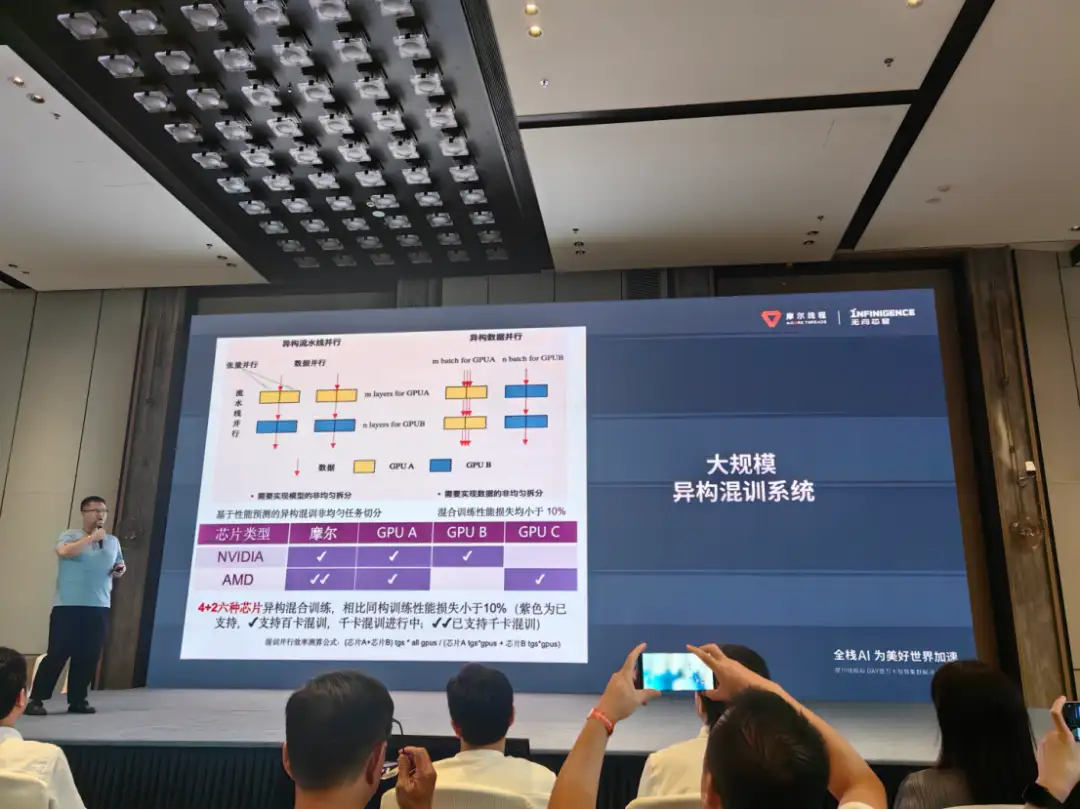
構建萬卡集群并非一萬張 GPU 卡的簡單堆疊,而是一項高度復雜的超級系統工程。它涉及到超大規模的組網互聯、高效率的集群計算、長期穩定性和高可用性等諸多技術難題。
張建中也感嘆到:「萬卡集成的難度比登喜馬拉雅山還難。」
共建大模型應用生態
根據《2023~2024 年中國人工智能計算力發展評估報告》,中國智能算力規模正處于高速增長狀態。預計到 2027 年,中國智能算力規模將達 1117.4EFLOPS,2022~2027 年期間的年復合增長率為 33.9%。
萬卡集群的建設需要產業界的齊心協力,為實現大模型創新應用的快速落地,讓國產算力「為用而建」。
在今日的發布會線程,摩爾線程攜手中國移動通信集團青海有限公司、中國聯通青海公司、北京德道信科集團、中國能源建設股份有限公司總承包公司、桂林華崛大數據科技有限公司,分別就青海零碳產業園萬卡集群項目、青海高原夸娥萬卡集群項目、廣西東盟萬卡集群項目進行了戰略簽約。

今年 5 月,摩爾線程與無問芯穹正式完成基于國產全功能 GPU 千卡集群的 3B 規模大模型實訓。該模型名為「MT-infini-3B」。MT-infini-3B 模型訓練總用時 13.2 天,經過精度調試,實現全程穩定訓練不中斷,集群訓練穩定性達到 100%,千卡訓練和單機相比擴展效率超過 90%。在行業內率先開啟了國產大語言模型與國產 GPU 千卡智算集群深度合作的新范式。
清程極智與摩爾線程合作的過程中,發現其硬件架構、指令集、編譯器、MUSA 軟件棧等設計非常優秀,極具潛力。清程極智將與摩爾線程強強聯合,攜手打造世界水平的大模型基礎設施。

此外,摩爾線程還與360、京東云、智平方等多家國內企業合作。
結語
隨著今年「AI+」首次被寫入兩會工作報告,AI 算力成為新質生產力的重要引擎。
智算中心不應只是硬件的堆積,更是對軟硬一體化的 GPU 智算系統整合能力的考驗,GPU 分布式計算系統的適配、算力集群的管理和高效推理引擎的應用等,都是提高算力中心可用性的重要因素。
四年多的潛心發展,摩爾線程在 AI GPU 方面具備了強勁的實力,構建起了一張包括芯片、板卡、服務器、集群和軟件棧的全棧 AI 產品版圖,并且已經多點實現落地。
正如摩爾線程創始人兼 CEO 張建中所言:「當前,我們正處在生成式人工智能的黃金時代,技術交織催動智能涌現,GPU 成為加速新技術浪潮來臨的創新引擎。夸娥萬卡智算集群作為摩爾線程全棧 AI 戰略的一塊重要拼圖,可為各行各業數智化轉型提供澎湃算力,不僅有力彰顯了摩爾線程在技術創新和工程實踐上的實力,更將成為推動 AI 產業發展的新起點。」

評論