大模型價格戰開打,多芯混合能否成破局之策?

近期,國內多個大模型企業陸續下調相關產品價格。
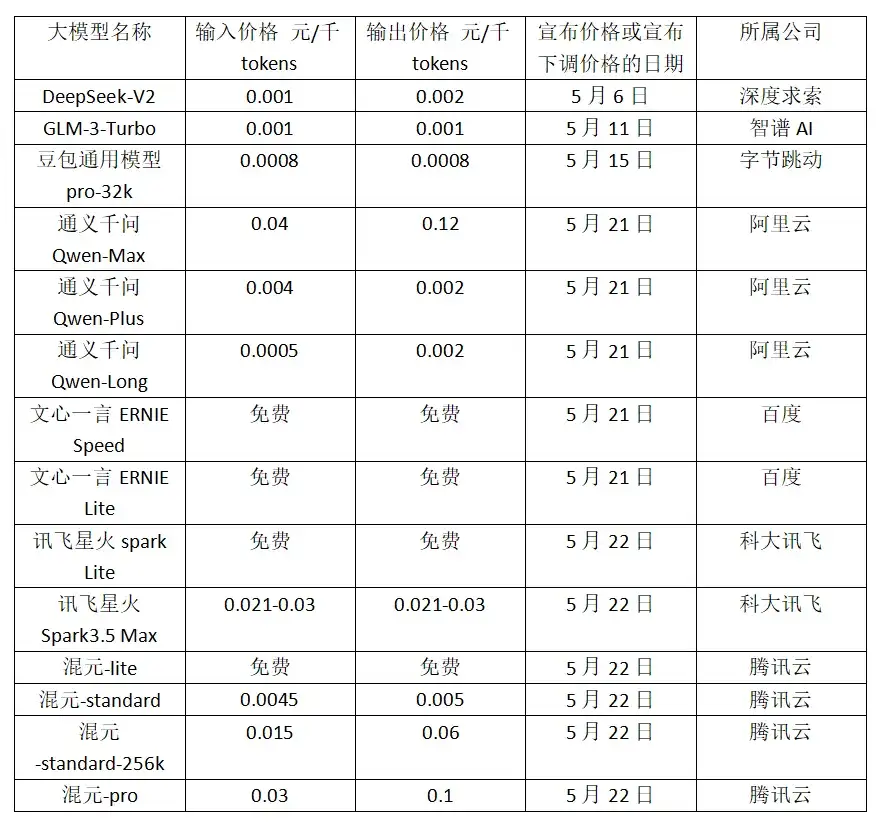
本文引用地址:http://www.104case.com/article/202406/460282.htm五月初開始,9 家發布新內容的國內大模型企業中,有 7 家宣布降價。其中包括:深度求索、智譜 AI、字節跳動、阿里云、百度、科大訊飛、騰訊云這 7 家企業,共涉及 21 款模型。甚至于有大廠打出「免費模式」的旗號。
大模型價格戰愈演愈烈
5 月 6 日,知名私募巨頭幻方量化創立的深度求索對外發布第二代 MoE 模型 DeepSeek-V2。MoE 模型即混合專家模型,將復雜任務拆解為子任務,分別交由合適的「專家」模型處理,提高準確性和推理效率。模型迭代的同時,深度求索把 API 調用的定價降到每百萬 tokens 輸入 1 元、輸出 2 元,價格僅為 GPT-4-Turbo 的近百分之一。
5 月 11 日,智譜 AI 跟進,宣布將其 GLM-3 Turbo 模型的調用價格下調 80%。從 5 元/百萬 tokens 降至 1 元/百萬 tokens。1 元可以購買 100 萬 tokens。
5 月 15 日,字節的豆包大模型正式對外開放,放出了較業內極低的價格,價格單位直接從「元」變為「厘」。豆包大模型家族包含豆包通用模型 PRO 版和 lite 版兩款通用模型,其中,豆包通用模型 pro-32k 版,推理輸入價格 0.0008 元/千 tokens,較行業價格低 99.3%。lite 版為 0.0003 元/千 tokens。
隨后在 5 月 21 日,阿里云也發布降價通知,通義 9 款主力大模型大幅降價。其中,通義千問 GPT-4 級主力模型 Qwen-Long 的 API 輸入價格直降 97% 至 0.0005 元/千 tokens,1 塊錢可以買 200 萬 tokens,相當于 5 本《新華字典》的文字量。
當日,百度甚至宣布文心大模型的兩款主力模型 ENIRE Speed、ENIRE Lite 全面免費。科大訊飛也在 22 日宣布訊飛星火 Lite 版 API 永久免費開放,訊飛星火 Pro/Max API 價格降至 0.21 元/萬 tokens。此外,22 日騰訊也公布了全新的大模型升級方案。騰訊的主力模型之一混元-lite 模型,API 輸入輸出總長度計劃從目前的 4k 升級到 256k,價格從 0.008 元/千 tokens 調整為全面免費。
在 AI 領域的激烈角逐中,大模型正逐步走向價格戰的漩渦。那么,推動這一變革的深層原因是什么?而它又將如何深遠地影響整個行業生態?
降價的本質為何?
價格戰有利于巨頭搶占市場
當前的行業價格戰,可以看做是「百模大戰」帶來的一個衍生結果。大模型狂熱之時,幾乎每隔一天就有一個大模型「蹦出來」。截至 2023 年 11 月 30 日,國內已經有至少 200 家大模型廠商推出了各自的大模型。
當下的大模型競爭早已超過了技術的范疇,更多是一種生態層面的比拼,具體表現在有多少應用、有多少插件、有多少開發者以及用戶等。
要知道,當前的大模型市場,空間相當有限,大部分的大模型 APP 都已經開始面臨用戶增長乏力的困境,包括備受矚目的 OpenAI。因此降價便是這些大廠獲得更多市場的方式之一。
此外,從價格角度來看,一些初創公司的價格本身就較低。因此,針對當下的科技巨頭紛紛降價,那些 AI 創業公司大都沒有選擇跟進。一些參與 AI 大模型投資的投資人表示,「這波降價對一些創業公司 TO B 模式影響較大。」因為過去很多公司,之所以選擇跟初創公司合作,主要就是看重初創公司的 API 比大廠要便宜,但現在基本上沒有任何比大廠便宜的可能性了,這意味著創業公司的 B 端商業化模式不復存在了。
對于這些初創公司來說,倘若找不到新的出路,或許就會面臨生死考驗。
入門級、輕量級的文本大模型的能力差距不顯著
半導體產業縱橫觀察發現,在這波降價潮中降價的模型主要為入門級、輕量級的文本大模型,而高性能及圖像識別、語音識別等垂類的多模態模型并沒有調整價格。
而這些入門級、輕量級的文本大模型技術和能力等各方面已經趨同,各廠商之間的技術壁壘并不顯著,因此價格競爭成為了它們之間主要的競爭手段。
根據上海人工智能實驗室發布的大模型開源開放評測體系司南(OpenCompass2.0)顯示,復雜推理相關能力是大模型普遍面臨的難題,國內大模型相比于 GPT-4 還存在差距,這是大模型在金融、工業等要求可靠的場景落地需要的關鍵能力。不過,在中文場景下國內最新的大模型已展現出獨特優勢,尤其在語言、知識維度上接近 GPT-4 Turbo 的水平。
大模型的邊際收益正在持續走低
Gary Marcus 博士在「Evidence that LLMs are reaching a point of diminishing returns—and what that might mean」《LLMs 正達到收益遞減的證據——及其可能意味著什么》一文中提到,從 GPT-2 到 GPT-4 甚至 GPT-4 Turbo 的性能變化,已經出現了性能遞減的跡象。
Gary Marcus 博士表示:「自 GPT-4 發布以來,多個模型在 GPT-4 水平性能上都有著巨大的收斂,然而并沒有明顯領先的模型。」
在收益遞減的背景下,意味著處理相同的任務,開發者的實際成本是在上升的。在 AI 創新商業化前景還不明朗的市場環境下,為了保住現有用戶,大模型廠商必須給出有吸引力的對策。包括提供更小的模型,比如谷歌推出的 Gemini 1.5 Flash。另一個手段就是直接降價。
投入高昂,多芯混合或有助力
人工智能的核心是算力,算力需求主要分為兩部分,包括訓練算力和推理算力。
目前來說對訓練算力需求非常高,根據去年的一則數據顯示,ChatGPT 的公開數據顯示它的整個訓練算力消耗非常大,達到了 3640PF-days。換算成英偉達 A100 芯片,它單卡算力相當于 0.6P 的算力,理想情況下總共需要大概 6000 張,在考慮互聯損失的情況下,需要一萬張 A100 作為算力基礎。在 A100 芯片 10 萬人民幣/張的情況下,算力的硬件投資規模達到 10 億人民幣。推理算力主要是英偉達 T4 卡,推理成本大約相當于訓練成本的三分之一。
除了算力的成本,還有隨之而來的存儲、推理、運維、應用等一系列成本。??
那么如何解決絕大多數企業當下最關心的「降本增效」問題?除了對模型的優化,硬件層面的創新思路亦不容忽視。近期,業界不少專家和技術人員開始聚焦于多芯混合的概念,嘗試通過這一策略來為企業帶來更高的性能和更低的成本。
那么到底什么是多芯混合?它又如何在 AI 大模型算力緊缺的當下提供更優的解決方案。
多芯混合主要涉及在硬件設計或應用中,結合使用不同類型、不同功能或不同制程架構的芯片,以形成一個混合的計算系統或解決方案。上文提到當前基礎大模型訓練所需要的最大 AI 算力集群規模,已經從單一集群千卡逐步提升至萬卡量級。同時,很多智算中心已經部署的 GPU 集群,通常是十幾臺至數百臺服務器不等,難以滿足未來行業大模型訓練的需求。
所以,在已有 AI 算力集群的基礎上,構建由昆侖芯、昇騰等不同芯片混合組成的單一集群,為大模型訓練提供更大 AI 算力,成為了一個自然的選擇。
多芯混合有哪些優勢?
第一,通過將計算任務分配到多個 GPU 上,可以顯著加速模型的訓練速度。多 GPU 并行訓練還可以減少單 GPU 訓練中由于計算瓶頸導致的時間浪費,從而提高了訓練效率。
第二,多 GPU 訓練可以同時處理更多的數據,從而提高了內存利用率。
第三,這種混合集群的構建能夠有效降低成本。畢竟,與英偉達的 A100/H100 系列 GPU 相比,其他品牌的 GPU 價格更為親民。
然而,若此方案真如我們想象中那般易于實施,那么它早已被業界的諸多巨頭所采納。具體看看,這一方案的實施都存在哪些難點?
多芯混合要解決哪些問題?
為了建設一個能夠高效訓練大模型的集群,需要在卡間和機間建立高效的互聯互通,將大模型訓練任務按照合適的并行策略拆分到 GPU 卡中,最后通過各種優化方法,加速 GPU 對算子的計算效率,完成大模型訓練。
然而,不同芯片之間很難互聯互通,因為英偉達 GPU、昆侖芯、昇騰 910B 的物理連接方式,并行策略以及 AI 加速套件上都不一樣。
首先,在互聯互通上,單臺服務器內的 8 塊 GPU 卡通過 NVLink 連接。不同服務器之間的 GPU 卡通過 RDMA 網絡連接。
過去,我們看到了很多有關英偉達 GPU 和 CUDA 護城河的介紹。誠然,經過多年的投入,他們已經建立起了難以逾越的優勢。但除此以外,如上所述,英偉達還有很多隱形護城河,NVLink 就是其中的一個,一個為 GPU 到 GPU 互聯提供高速連接的技術。
在摩爾定律逐漸失效,但對算力要求越來越高的當下,這種互聯顯得尤為必要。
英偉達官網表示,NVLink 是全球首創的高速 GPU 互連技術,為多 GPU 系統提供另一種選擇,與傳統的 PCI-E 解決方案相比,速度方面擁有顯著提升。使用 NVLink 連接兩張英偉達 GPU,即可彈性調整存儲器與效能,滿足專業視覺運算最高工作負載的需求。
而昆侖芯服務器內部通過 XPU Link 進行連接,服務器之間通過標準的 RDMA 網卡進行連接,卡和卡之間使用 XCCL 通信庫進行相互通信。昇騰 910B 服務器內部通過 HCCS 進行連接,服務器之間通過華為自研的內置 RDMA 進行連接,卡和卡之間使用 HCCL 通信庫進行相互通信。
其次,在并行策略上,英偉達 GPU 和昆侖芯采用單機 8 卡的部署方式,昇騰 910B 則是機內 16 卡分為 2 個 8 卡通信組。這意味著在 AI 框架下形成不同的集群拓撲,需要有針對性地制定分布式并行策略。
最后,在 AI 加速套件上,由于昆侖芯、昇騰等芯片在計算能力,顯存大小,I/O 吞吐,通信庫等均存在差異,故需要面向具體芯片進行特定優化。最后的結果,就是每一種芯片,有一個各自對應的算子庫,以及相應的加速策略。
哪些廠商開始試水?
值得注意的是,近日,AMD、博通、思科、谷歌、惠普企業 (HPE)、英特爾、Meta 和微軟等領先科技公司組成的聯盟宣布成立超級加速器鏈路 (UALink) 促進會。該計劃旨在制定一項開放的行業標準,以促進數據中心 AI 系統的高速、低延遲通信。
面對日益增長的 AI 工作負載,這些科技巨頭均迫切需要超高性能互連。
百度也在打造多芯混合訓練 AI 集群。百度百舸的多芯混合訓練方案,屏蔽了底層復雜的異構環境,將各類芯片融合成為了一個大集群,可以實現存量不同算力的統一,整合發揮這些算力的最大效能,支持更大模型訓練任務。同時,支持新增資源的快速融入,滿足未來業務增長的需要。該方案不僅通過百度智能云的公有云提供服務,同時還可以通過 ABC Stack 專有云進行交付。
此前,百度集團執行副總裁、百度智能云事業群總裁沈抖表示,在「一云多芯」方面,百度百舸兼容昆侖芯、昇騰、海光 DCU、英偉達、英特爾等國內外主流 AI 芯片,支持同一智算集群中混合使用不同廠商芯片,最大程度上屏蔽硬件之間差異,幫助企業擺脫單一芯片依賴,打造更有性價比、更安全、更具彈性的供應鏈體系。在多芯混合訓練任務中,百舸能夠將單芯片利用率、芯片間通信效率、集群整體效能發揮到極致,百卡規模性能損失不超過 3%,千卡規模性能損失不超過 5%,均為國內最高水平。
近日,FlagScale 開源大模型并行訓練框架全面升級。智源團隊與天數智芯團隊合作,實現了「英偉達芯片+其它 AI 芯片」集群上單一大模型任務的異構混合訓練,并在 70B 大模型上驗證了不同架構芯片上進行異構混合訓練的有效性。同時,為了加速多種 AI 芯片在大模型訓練場景的使用,智源積極探索高效靈活的芯片適配方案,通過與硬件廠商的深入合作,FlagScale 已在 6 家不同廠商的多款 AI 芯片上適配 Aquila2 系列大模型的大規模訓練。
由于不同廠商的卡間互聯協議不同,為了實現「英偉達芯片+其它 AI 芯片」高速互聯,智源團隊與天數智芯協作,優化天數智芯的 iXCCL 通信庫,使其在通信原語操作上以及 API 接口上兼容英偉達 NCCL,然后將框架編譯鏈接到同一 iXCCL 通信庫上,從而在用戶和 AI 框架無感知的情況下實現異構算力芯片間高效通信,進而實現不同架構芯片混合訓練。同時,雙方還協作優化了流水線并行的分配方式,并針對不同芯片算力、內存帶寬、內存容量的差異來為不同芯片配置不同的流水線并行策略,以使得訓練過程中能充分發揮不同芯片的性能,最終率先實現了通用 GPU 異構大模型高效訓練方案。
國產 GPU 廠商的機遇
多芯混合技術允許將不同架構、不同功能的芯片集成在一個系統中,這為國產廠商提供了技術創新的機會。通過整合和優化不同芯片的性能,可以開發出更高效、更靈活的解決方案。
多芯混合技術為國產廠商帶來了綜合性的發展機遇。這一技術不僅推動了技術創新,滿足了市場對高性能、低功耗芯片的日益增長需求,還促進了產業鏈上下游的協同合作,加強了產業整體競爭力。同時,國家政策的支持也為國產廠商在多芯混合技術領域的發展提供了有力保障。國產廠商應抓住這一機遇,加大研發力度,推動多芯混合技術的突破與應用,以提升國產芯片的技術水平和市場競爭力。





評論