ISSCC 2023:14篇清華、北大入選論文詳解

近日,國際固態電路大會(ISSCC 2023)在美國舊金山舉行。ISSCC (International Solid-State Circuits Conference) 國際固態電路會議始于 1953 年,是全球學術界和工業界公認的集成電路設計領域最高級別會議,被認為是「集成電路設計領域的奧林匹克大會」。
本文引用地址:http://www.104case.com/article/202303/444275.htm2023 年 ISSCC 共錄用同行評審論文 198 篇,來自中國大學的前沿研究論文的數量不容小覷,其中 49 篇來自中國的論文中,其中 13 篇來自清華大學,6 篇來自北京大學。
清華大學
清華大學集成電路學院作為第一署名單位在 ISSCC 2023 發表了 8 篇學術論文,所涉及研究內容包括存內計算視覺芯片、量子計算芯片、多模態 Transform 芯片、異步類腦芯片、可重構存內張量計算芯片、超寬帶收發機、分頻器、振蕩器等。
存內計算視覺芯片 CV-CIM
代價匹配算法需要精確計算圖像間的相似度,已經被廣泛應用于自動駕駛,機器人,AR/VR 等領域,但由于其頻繁的數據訪存,導致其難以應用于低功耗場景中。集成電路學院魏少軍、尹首一教授團隊提出了采用存算一體范式的 CV-CIM,將計算單元與 SRAM 存儲單元完成合并,減少數據搬移。利用異或邏輯的自反性,結合律等,可重構為乘法,加法,減法,比較等多種基本算子。進一步經過數模混合存算單元的配合,實現包括 L0/L1/L2 在內的多種距離計算算法;并利用圖像相似度,動態擴充計算數據稀疏度,擴展計算噪聲容限,提升計算精度;通過增加行方向細粒度地址控制,列方向讀寫并行模式,大幅提升存算系統的利用率。考慮到模擬單元受 PVT 影響,增加 Canary BIST 單元保證計算系統魯棒性。CV-CIM 作為國際首款針對圖像匹配的存算一體芯片,在 28nm 工藝上成功實現流片,峰值能效為 1158TOPs/W,面積為 0.387mm^2。
該工作以「CV-CIM: A 28nm XOR-derived Similarity-aware Computation-In-Memory For Cost Volume Construction」為題發表在 ISSCC2023。集成電路學院博士研究生岳志恒為論文第一作者,尹首一教授為通訊作者。
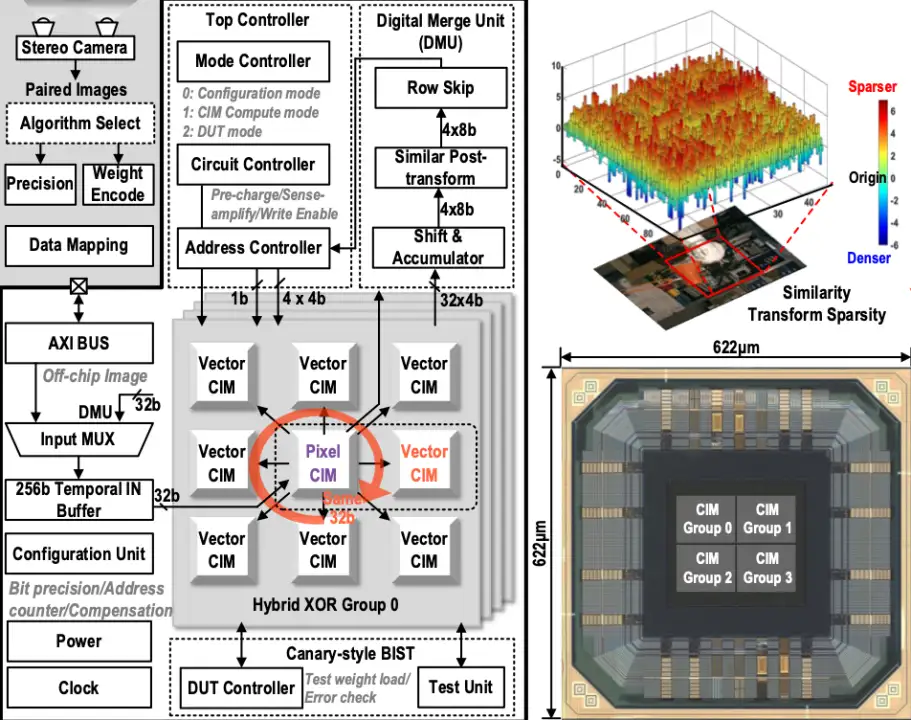
CV-CIM 架構設計優化實驗及芯片照片
超導量子計算控制芯片
量子計算系統還有很遙遠的距離。超低溫 CMOS 芯片技術是解決這一瓶頸的有效途徑之一。集成電路學院王志華、池保勇團隊在前期大量 CMOS 元器件超低溫特性建模研究的基礎上,設計出目前具有最低功耗水平和最小芯片面積的雙通道量子比特控制芯片。該芯片基于極化調制技術,在 3.5K 超低溫環境下可以產生超導量子比特控制所需的 XY 通道任意包絡脈沖信號和 Z 通道偏置信號,同時集成了片上本振、時鐘、存儲等電路,在國際上首次把單個量子比特控制能耗降低至 13.7mW。較 IBM、PSTECH 等最新研究,能耗水平降低 40% 以上。測試表明,該芯片可以在超低溫環境下對超導量子比特實現有效控制。
該工作以「A Polar-Modulation Based Cryogenic Qubit State Controller in 28nm Bulk CMOS」為題發表在 ISSCC2023。該芯片是國內首個公開報道的集成化量子比特控制芯片,具有集成度高、功耗低、面積小等顯著特點,對于推進量子計算系統自主可控的集成化、小型化有關鍵支撐作用。論文第一作者為集成電路學院畢業生郭衍束博士,姜漢鈞副教授、李鐵夫副研究員為該項研究工作的主要負責人。
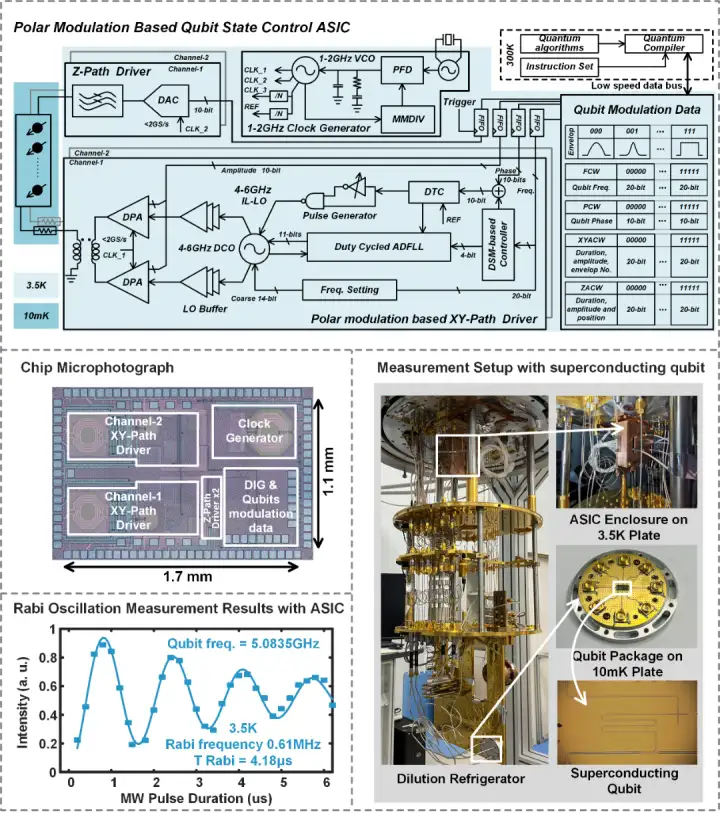
低溫 CMOS 量子比特控制芯片結構及測試
多模態 Transform 芯片
多模態 Transformer 是當下最流行的處理多種模態信號(視覺、文字、語音等)的 AI 模型之一,已廣泛應用于視頻問答、多語言圖像檢索等任務中。這類模型巨大的計算量、頻繁的數據訪問、獨特的跨模態注意力機制對 AI 芯片設計造成諸多挑戰。集成電路學院魏少軍、尹首一教授團隊提出國際首款基于可重構數字存算一體架構的多模態 Transformer AI 芯片 MulTCIM。研究團隊充分利用跨模態注意力機制中的計算冗余性,設計出綜合利用 attention-token-bit 三個層次混合稀疏性的存算一體架構:1)使用注意力局部性調度器優化 attention 稀疏,提高存算單元利用率;2)采用模態自適應存算一體網絡優化 token 稀疏,減少跨模態切換時的等待時間;3)利用位寬均衡存算一體單元優化 bit 稀疏,降低存算一體單元的計算延遲。MulTCIM 芯片使用 TSMC 28nm 工藝成功流片,在典型多模態 Transformer 模型 ViLBERT 上僅產生 2.24μJ/Token 的能耗,相比于 ISSCC2022 上發表的 Transformer 芯片可獲得 5.91 倍的能效提升。
該工作以「MulTCIM: A 28nm 2.24μJ/Token Attention-Token-Bit Hybrid Sparse Digital CIM-based Accelerator for Multimodal Transformers」為題發表在 ISSCC2023。集成電路學院畢業生涂鋒斌博士為論文第一作者,尹首一教授為論文通訊作者。
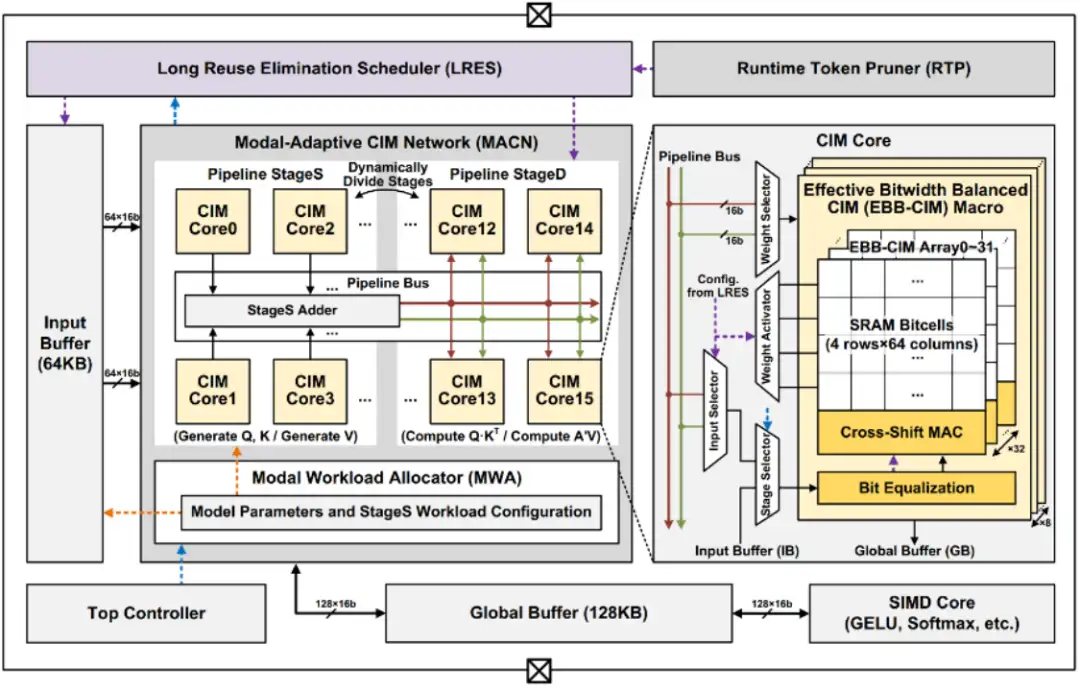
面向多模態 Transformer 模型的 MulTCIM 芯片架構圖

MulTCIM 芯片及硬件指標
片上學習異步類腦芯片
異步電路是設計大規模類腦芯片的重要技術,但由于缺乏成熟 EDA 工具的支持,異步電路設計存在較大挑戰。集成電路學院王志華、池保勇團隊研發出國內首款具備片上學習能力的異步類腦芯片 ANP-I,ANP-I 芯片采用全異步電路技術,設計了能實現手勢識別、關鍵詞檢測、圖像分類等多類型任務的片上學習類腦芯片。該芯片實現了三層全連接網絡,片上集成了 522 個神經元,517K 個突觸,每個突觸的權重精度為 8/10-bit。ANP-I 芯片具有極低功耗的片上學習能力,針對不同的任務,芯片從隨機權重開始進行訓練,在保證 92% 以上準確率的前提下,每個樣本的學習能耗低于 100nJ。該性能使得邊緣端智能芯片同時具備識別和學習能力成為可能,可應用于萬物智聯的邊緣端多模態信息的智能處理。傳統應用于邊緣計算的智能芯片,由于片上學習的能耗代價過高,往往只支持識別過程。ANP-I 芯片低能耗的片上學習能力可以很好的解決該問題,使得具有片上學習能力的邊緣端智能芯片得到廣泛的運用。例如在基于肌電臂環的手勢識別展示中,通過片上學習,ANP-I 芯片能學習到不同使用者特有的肌電信號特征,并且消除肌電臂環電極偏移帶來的影響,極大程度提高基于肌電臂環的手勢識別準確率以及實用程度。
以上工作以「ANP-I: A 28nm 1.5pJ/SOP Asynchronous Spiking Neural Network Processor Enabling Sub-0.1μJ/Sample On-Chip Learning for Edge-AI Applications」為題發表在 ISSCC2023。集成電路學院博士研究生張吉霖為論文第一作者,陳虹研究員為通訊作者。
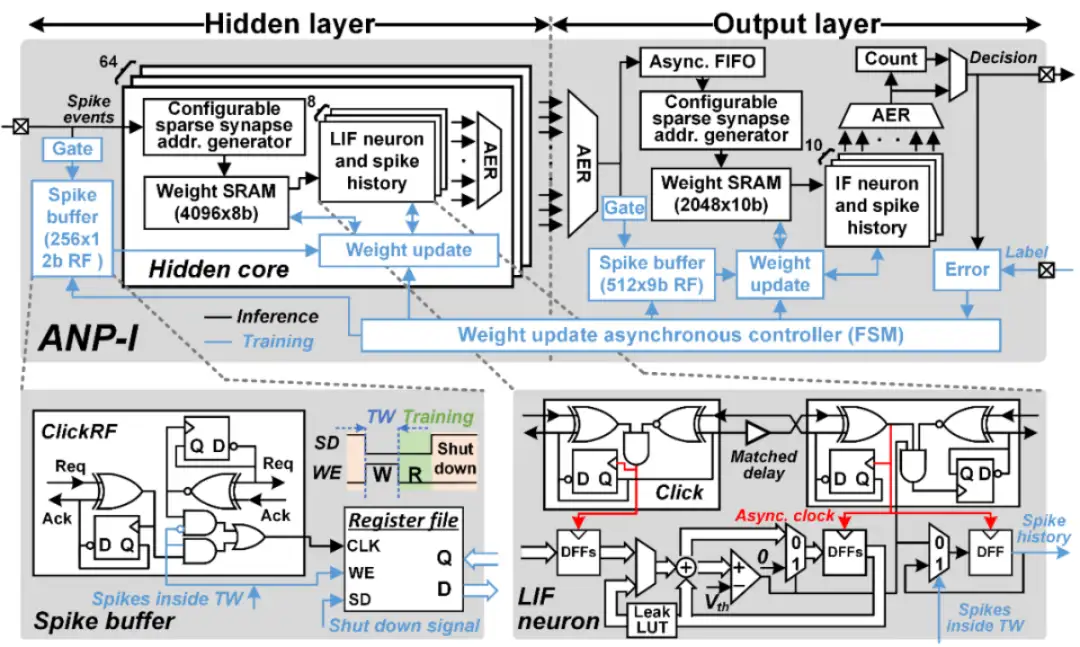
片上學習異步類腦芯片硬件架構
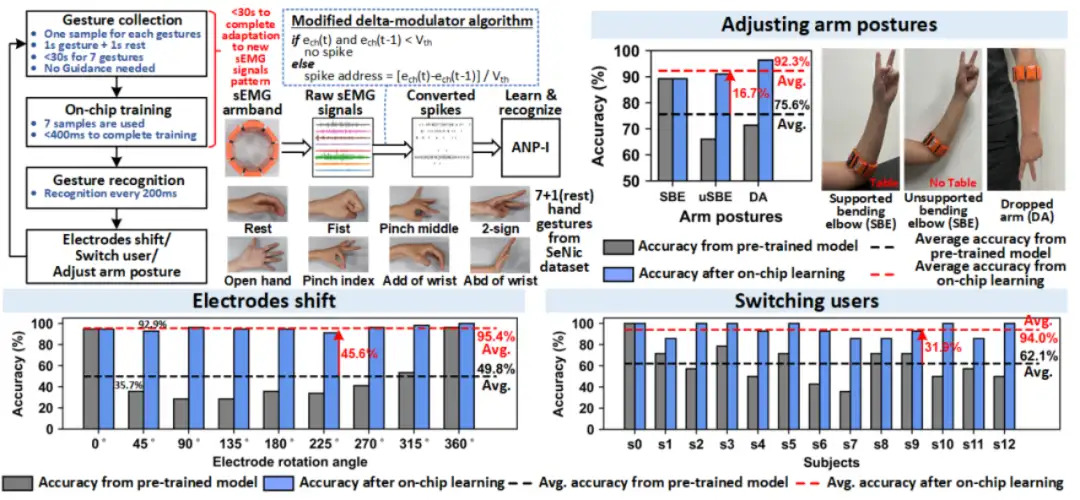
片上學習異步類腦芯片在基于肌電臂環的手勢識別上的應用
可重構存內張量計算芯片 TensorCIM
Beyond-NN 計算是面向通用智能場景的新型計算類型。不同于傳統的處理圖像、語音等規則數據結構的神經網絡,Beyond-NN 計算需要處理真實世界中的非規則數據結構,例如社交網絡、知識圖譜、推薦系統等。針對 Beyond-NN 在算力、訪存、功能三方面的技術挑戰,集成電路學院魏少軍、尹首一教授團隊提出國際首款基于可重構數字存算一體架構的多芯粒張量處理器 TensorCIM:1)TensorCIM 采用多芯粒系統對算力和存儲容量進行擴展,在降低制造成本的同時,為不同規模的 Beyond-NN 場景提供可擴展的系統解決方案。2)TensorCIM 通過數字存算一體架構大幅減少數據搬運,并支持高精度的浮點計算以保證準確度。3)TensorCIM 將可重構技術與數字存算一體相結合,實現稀疏張量聚集和稀疏神經網絡計算兩種模式的動態切換,保持極高的計算資源利用率。TensorCIM 芯片使用 TSMC 28nm 工藝成功流片,在圖神經網絡、推薦系統等典型 Beyond-NN 應用上驗證,取得 3.7nJ/Gather 的稀疏張量聚集效率和 8.3TFLOPS/W 的稀疏 FP32 張量代數能效,相比同期浮點存算一體 AI 芯片能效提升 5.6 倍。
該工作以「TensorCIM: A 28nm 3.7nJ/Gather and 8.3TFLOPS/W FP32 Digital-CIM Tensor Processor for MCM-CIM-Based Beyond-NN Acceleration」為題發表在 ISSCC2023。集成電路學院畢業生涂鋒斌博士為論文第一作者,尹首一教授為論文通訊作者。
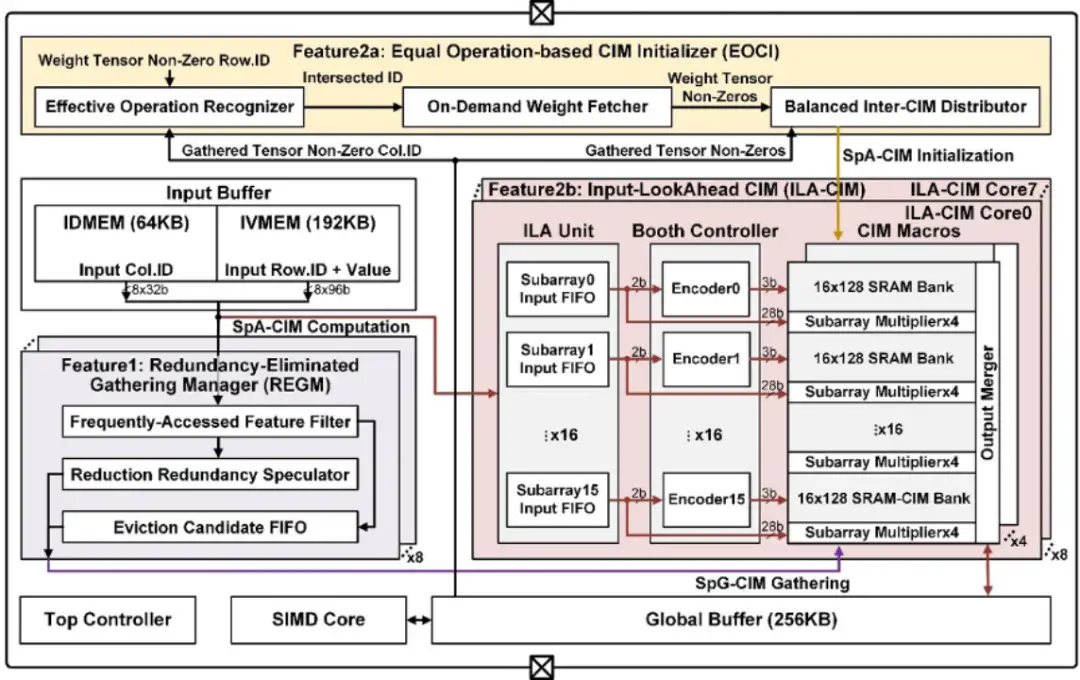
面向 Beyond-NN 計算的 TensorCIM 芯片(單芯粒)架構圖
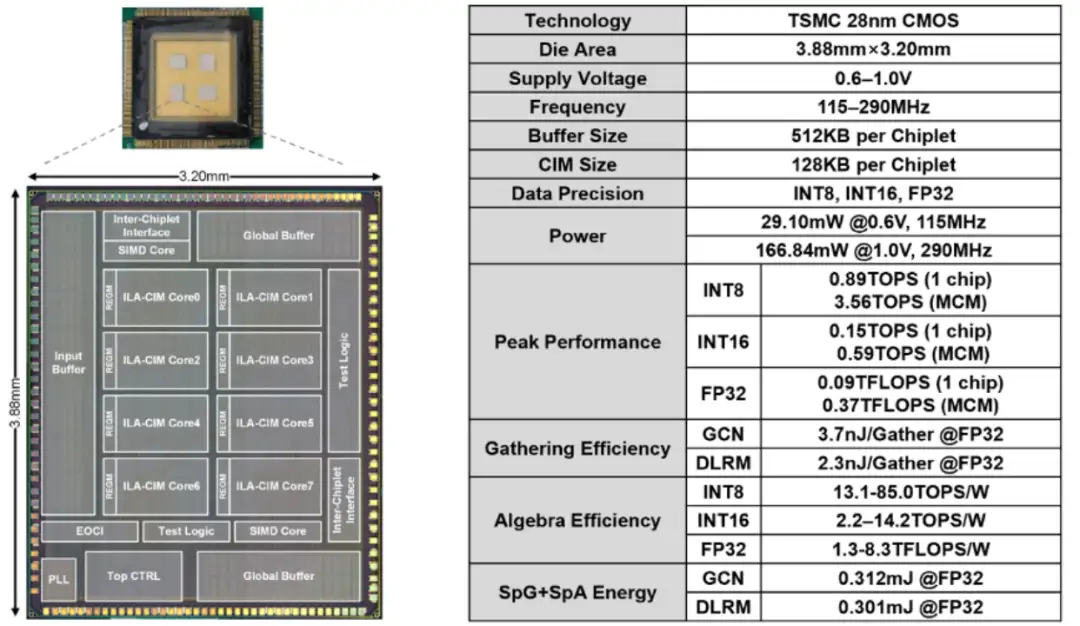
TensorCIM 芯片及硬件指標
脈沖超寬帶收發機芯片
脈沖超寬帶 (IR-UWB) 技術通過發送極窄脈沖序列實現低功耗信息傳輸和厘米級測距精度,逐漸成為短距通信的主流技術之一。但是,傳統的脈沖超寬帶收發機存在兩大技術挑戰:首先,極窄的脈沖寬度使得收發機在基帶同步時面臨困難。其次,脈沖超寬帶接收機在系統功耗和解調性能之間存在著折中關系。針對以上問題,研究團隊提出了一種全新的脈沖超寬帶收發機架構,該收發機采用了兩項關鍵技術。其一是雙脈沖開關鍵控 (Twin-OOK) 的調制方法,該調制方法不僅有效解決了收發機基帶同步的問題,而且通過跳頻技術提高了發射信號的頻譜利用效率。其二是正交不確定中頻的接收機構架,該構架顯著提升了脈沖超寬帶接收機的抗窄帶干擾性能和測距精度。采用 65nm CMOS 工藝實現的脈沖超寬帶收發機具有-71dBm 的靈敏度、0.96 厘米的測距精度,同時能夠容忍最大-22.4dBm 來自 6GHz 頻率的窄帶干擾信號。
該工作以「A Quadrature Uncertain-IF IR-UWB Transceiver with Twin-OOK Modulation"為題發表在 ISSCC2023。集成電路學院博士研究生汪博聞為論文第一作者,李宇根教授為通訊作者。
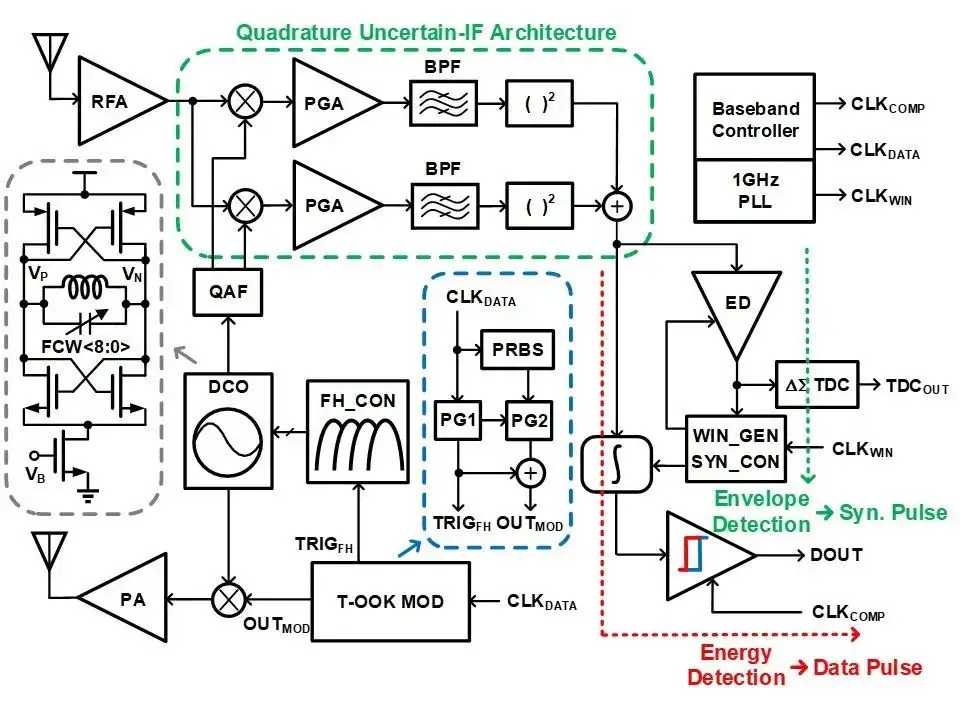
基于 Twin-OOK 調制的正交不確定中頻 IR-UWB 收發機架構
IR-UWB 收發機芯片顯微照片
超低雜散真分數輸出分頻芯片
現代片上系統(SoC)集成了幾個獨立的片上時鐘發生器,以滿足不同模塊的差異化設計需求,如微處理器、存儲器、I/O 接口和電源管理等。傳統方案通常在 SoC 中使用多個鎖相環(PLL)來提供各種頻率輸出,然而,這種方法導致相當大的硅面積、功率、成本和整體系統復雜性。真分數輸出分頻器(FOD)由多模分頻器(MMD)、數字時間轉換器(DTC)和數字控制器組成,已被證明是產生多個獨立時鐘的有效方法。然而,DTC 特性對 PVT 敏感,任何增益失配/積分非線性(INL)都會產生較大的雜散,從而降低頻譜純度和時鐘抖動。在 PLL 中廣泛應用的傳統 DTC 增益校準算法需要反饋路徑來反映 DTC 增益失配,這禁止其在具有開環結構的 FOD 中使用。集成電路學院王志華、池保勇團隊提出了一種具有輔助 PLL(aux-PLL)的 FOD,具備后臺 0/1/2 階 DTC INL 非線形校準能力。輔助 PLL 用作頻域濾波器,自然跟蹤輸入時鐘的載波頻率。因此,不需要先驗知識和前景校準。由于所提出的基于輔助 PLL 的 0/1/2 階 DTC INL 校準算法,所提出的真分數輸出分頻器 FOD 實現了低于-80dBc 的最壞情況雜散性能。
該工作以「A 10-to-300MHz Fractional Output Divider with -80dBc Worst-Case Fractional Spurs Using Auxiliary PLL-Based Background 0/1st/2nd-Order DTC INL Calibration」為題發表在 ISSCC2023。集成電路學院博士研究生楊宇蒙為論文第一作者,鄧偉副教授為通訊作者。
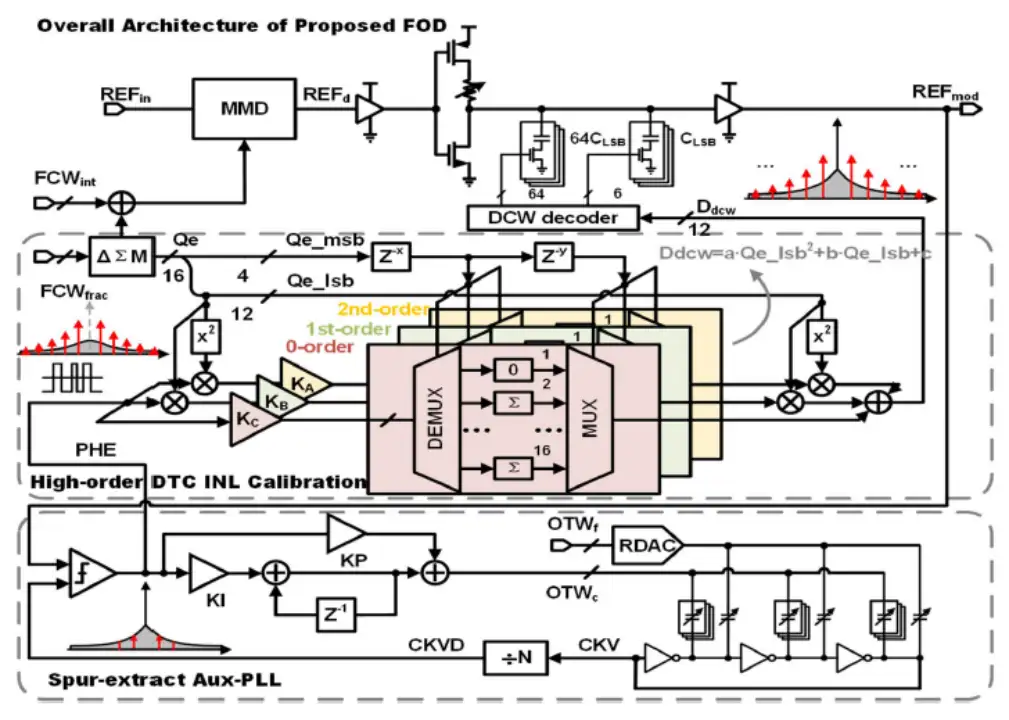
具備后臺自適應補償的超低雜散真分數輸出分頻芯片的總體架構
雙核增強 F 類振蕩器芯片
當前的 5G 和未來的 6G 高速移動互聯網時代對移動和便攜式設備中的本地振蕩器(LO)的功耗、硅面積和相位噪聲規范提出了更嚴格的要求,特別是在電池供電的移動電話、筆記本電腦和用于移動基站的無人機(UAV)中。在過去的幾十年中,大量研究聚焦于提高 RF 和毫米波振蕩器的功率效率,同時保持所需的相位噪聲特性。集成電路學院王志華、池保勇團隊提出了一種具有共模噪聲自消除和隔離技術的 11.5-14.3GHz 雙核 Class-F VCO。在不占用額外面積的情況下,VDD 和 GND 的注入噪聲同時被固有地消除,并且從漏極到柵極的噪聲路徑被隔離。測量結果表明,所提出的共模噪聲自消除和隔離 VCO 在與 11.8GHz 載波偏移 1MHz 時達到-119.2dBc/Hz 相位噪聲,換算為 192.8dBc/Hz 的 FoM,該性能在已報道的工作頻率范圍相近的 VCO 研究中極具競爭力。
該工作以「A 11.5-to-14.3GHz 192.8dBc/Hz FoM at 1MHz offset Dual-core Enhanced Class-F VCO with Common-Mode-Noise Self-Cancellation and Isolation Technique」為題發表在 ISSCC2023。集成電路學院博士研究生吳奇修為論文第一作者,鄧偉副教授為通訊作者。
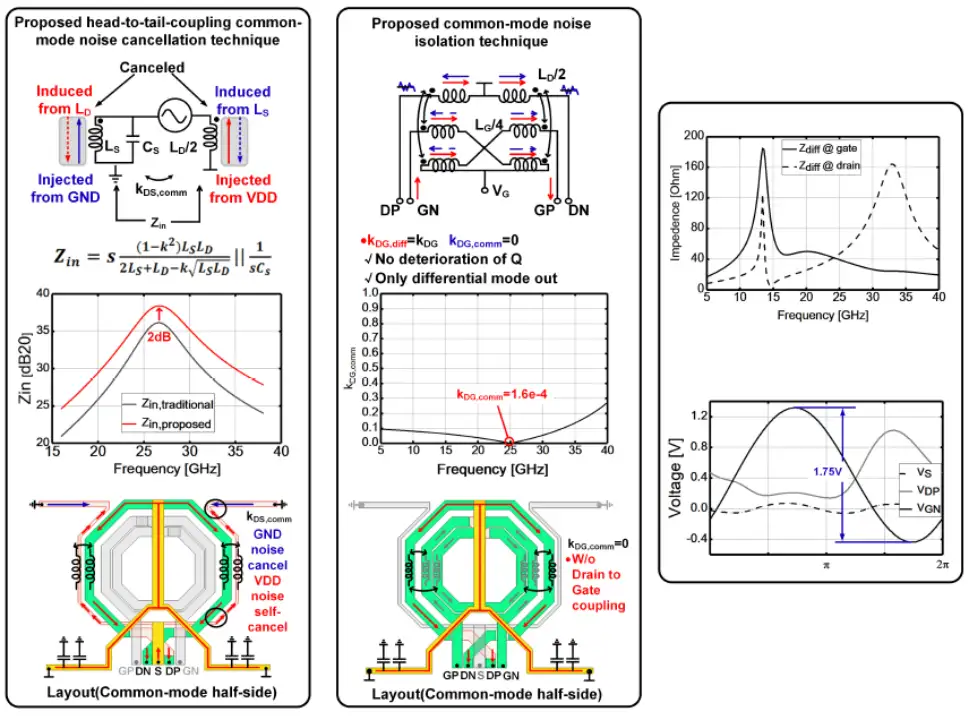
振蕩器芯片共模噪聲消除和隔離方案
北京大學
在本屆 ISSCC 上,北京大學集成電路學院/集成電路高精尖創新中心共有 6 篇論文入選,研究成果覆蓋「存算一體 AI 芯片、模擬與數字混合芯片、時鐘芯片、高速互連芯片」等領域,涉及大會全部 12 大領域中的 4 個領域,論文數在國際高校里排名第 5,在國際高校和企業里排名第 9。
存算一體 AI 芯片
面向邊緣 AI 場景,針對傳統存內計算芯片冗余數據處理產生功耗浪費的問題,課題組提出了基于差值求和計算方式的模擬存內計算拓撲,利用邊緣 AI 場景中輸入特征值逐漸且偶然變化的特點,自適應的消除冗余數據處理產生的功耗,顯著提升了神經網絡計算能效。該創新通過處理輸入變化量而非輸入絕對值的方式,最大限度消除了不變數據處理所浪費的功耗,提升了計算效率。
北京大學黃如院士-葉樂教授團隊,提出了差值輸入技術和差值矩陣乘法技術,通過將輸入特征值由絕對量變為變化量的方式,降低了存內計算陣列計算功耗,并實現自適應的輸出分布集中;此外,還提出了低位優先模數轉換器,通過減少較小數據模數轉化次數的方式,在不損失計算精度的情況下,顯著降低了模擬存內計算中的模數轉換功耗。
基于上述創新技術,研制了差值求和模擬存內計算芯片,在 8-bit 輸入/8-bit 權重/全精度輸出的情況下,實現了 21.38 TOPS/W 的峰值能效,1.44 TOPS/mm2 的峰值單位面積算力;在綜合評估指標(=能量效率×面積效率)下,達到了 26.72 TOPS/W×TOPS/mm2,是世界最好的存內計算芯片的 1.25 倍。該創新具有高能效、高算力、高通用性三大特性,可應用于邊緣端 AI 計算場景,如:圖像識別、語音識別、安防監控等。該創新有望與圖像傳感器相結合,實現針對邊緣端 AI 的感存算一體高效智能處理。
該工作以《面向邊緣 AI 處理的基于差值求和方式的 21.38 TOPS/W 的 SRAM 存內計算芯片》(A 22nm Delta-Sigma Computing-In-Memory (ΔΣCIM) SRAM Macro with Near-Zero-Mean Outputs and LSB-First ADCs Achieving 21.38 TOPS/W for 8b-MAC Edge AI Processing)為題,發表于今年 ISSCC,文章第一作者北京大學集成電路學院博士生陳沛毓進行宣講,北京大學集成電路學院博士生武蒙為共同一作,文章的通訊作者是馬宇飛研究員和葉樂教授。
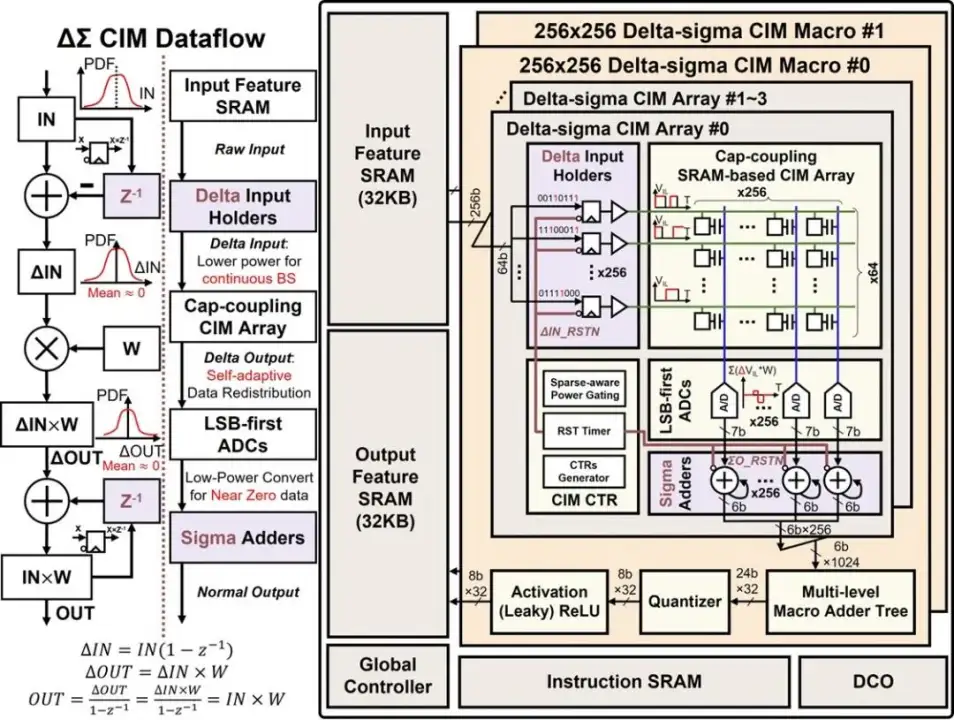
(a) 差值求和存內計算芯片數據流與架構圖
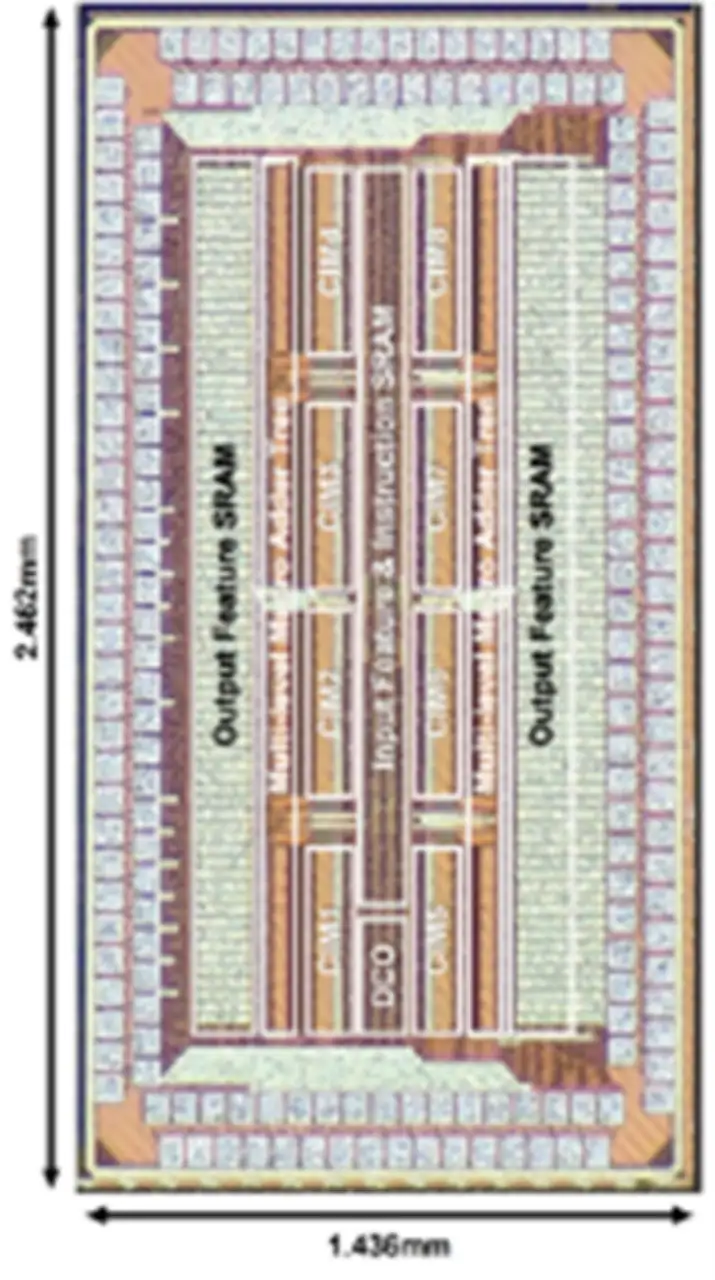
(b)存內計算芯片顯微照片
高能效電容型感知芯片
該工作面向物聯網傳感器應用,針對不斷上升的高速高精度電容數字轉換器需求,實現了一款高性能電容傳感器,解決了傳統高精度電容傳感器的架構不利于高速轉換的問題,突破了傳統電容采樣過程中采樣熱噪聲造成的性能瓶頸。
針對以上問題,北京大學黃如院士-葉樂教授團隊,從架構和電路兩個層面提出解決方案。架構層面,本工作創新性地將流水線型逐次逼近型寄存器轉換架構引入電容傳感器領域,突破傳統架構面臨的轉換精度、能效和轉換速度之間的折衷關系。電路層面,該工作首次提出了可應用于電容傳感中的 kT/C 采樣噪聲消除技術,解決了小電容傳感中的精度上限問題,突破了采樣熱噪聲的精度瓶頸。此外,還首次提出了基于不完全建立的相關電平抬升技術,縮短了傳統增益提升技術的粗放大階段,減少了額外功耗,并將等效開環增益大幅提升,提供了極高的增益穩定性,提高了級間放大器的能量效率和精度。在提高轉換速率的同時,實現了高精度(1fFrms 噪聲水平)電容傳感器的能量效率世界紀錄,相較現有工作將能效提升了一倍。
基于上述架構和電路層面的創新,課題組研制了一款基于 22nm CMOS 工藝的緊湊型高能效電容傳感器芯片,該電路在 22nm 工藝下實現了對 0-5.16pF 電容值測量,精度達到了 37.12aF,在所有高精度(1fFrms 噪聲水平)電容傳感器中具有最高的能效(7.9fJ/conv.-step),且達到了 71.3dB 的信噪比,相較前人的工作將能效提升了一倍。該電路具有高能效、高精度、小面積、高轉換速度等特點,可廣泛應用于面向電容傳感的各類物聯網傳感器和前端應用中,并且為電容傳感芯片的小型化提供了全新的解決方案。
該工作以《基于采樣熱噪聲消除和非完全建立相關電平抬升技術的 7.9fJ/Conversion-Step,37.12aFrms 噪聲的流水線逐次逼近型寄存器架構電容-數字轉換器芯片》(A 7.9 fJ/Conversion-Step and 37.12 aFrms Pipelined-SAR Capacitance-to-Digital Converter with kT/C noise cancellation and Incomplete-Settling based Correlated Level Shifting) 為題,發表于今年 ISSCC 的模擬傳感器前端領域(Session23 Analog Sensor Interface)分會場,由文章第一作者北京大學集成電路學院博士生高繼航進行宣講,文章的通訊作者是沈林曉研究員和葉樂教授。
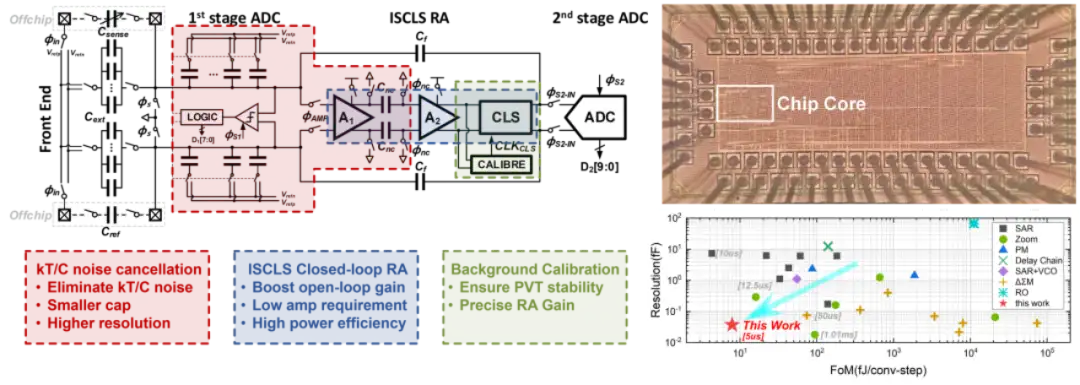
(a) 電容傳感器架構圖和創新技術 (b) 電容傳感器芯片顯微照片和性能對比圖
極低功耗振蕩器芯片
該工作面向智能物聯網 AIoT 芯片應用,針對需要周期喚醒的 AIoT 芯片,設計并實現了一款超低功耗晶體振蕩器電路,并實現了綜合條件下國際領先的低功耗與計時精度。
北京大學黃如院士-葉樂教授團隊,提出了基于 Gm-C 的電流注入時間控制電路與振幅檢測電路:該技術創新性地利用了 Gm-C 這一基礎模擬電路模塊,解決了電荷注入式晶體振蕩器的電流注入時間與大小控制的挑戰,使得基于此技術的 32kHz 實時時鐘(RTC)電路能夠在實現高精度計時的同時,在應用環境溫度范圍內僅消耗最多不到 2nW 的功耗;與此同時,由于模擬電路功耗主要取決于其偏置電流,在內置電流源的情況下,該電路較已發表的同類工作相比,實現了功耗對溫度最低的敏感性。
基于上述創新理念與技術,課題組研制了一款基于 22nm CMOS 工藝的超低功耗 32kHz 晶體振蕩器芯片。該電路在使用 ECS-2X6X 音叉型 32kHz 晶體下,在 25?C 室溫下的平均功耗僅為 0.954nW,取得了已發表過的基于 32kHz 電流注入晶體振蕩器中功耗最低的世界紀錄。其在 80?C 下的功耗僅為 1.90nW,為低功耗晶體振蕩器中的世界紀錄。該晶體振蕩器在長時工作下表現出了低至 6ppb 的 Allan 誤差(Allan Deviation),取得了單電源晶體振蕩器電路的長時穩定性世界紀錄。該電路可廣泛應用于面向環境應用的 IoT 芯片中,作為其中低功耗高精度實時時鐘模塊的核心。
該工作以《一款 22nm CMOS 工藝下利用基于 Gm-C 的電流注入控制電路實現的 0.954nW 32kHz 晶體振蕩器》(A 0.954nW 32kHz Crystal Oscillator in 22nm CMOS with Gm-C-Based Current Injection Control)為題,發表于今年 ISSCC,文章的第一作者是北京大學集成電路學院博士后張奕涵,文章的通訊作者為葉樂教授。
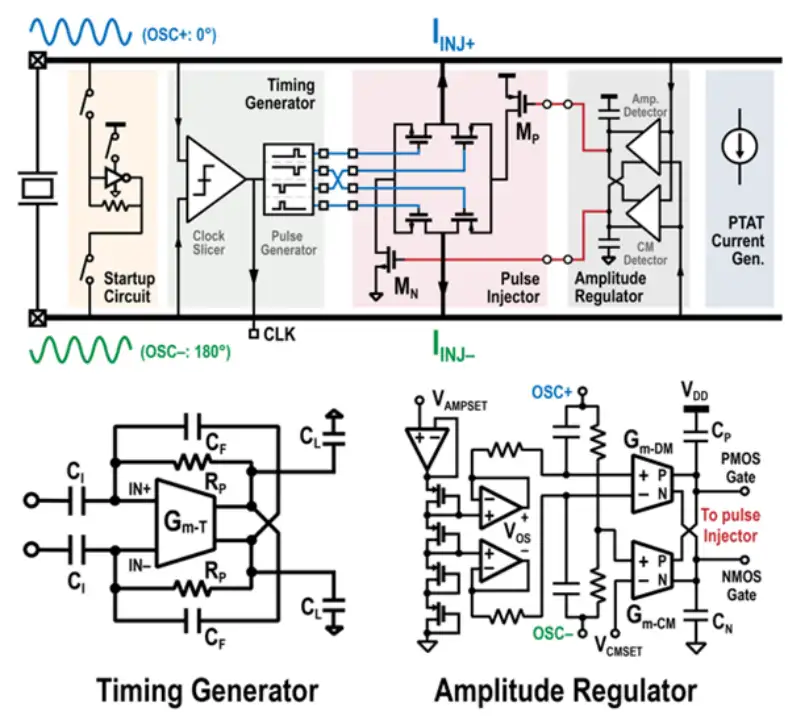
(a)電流注入型晶振結構與電路圖
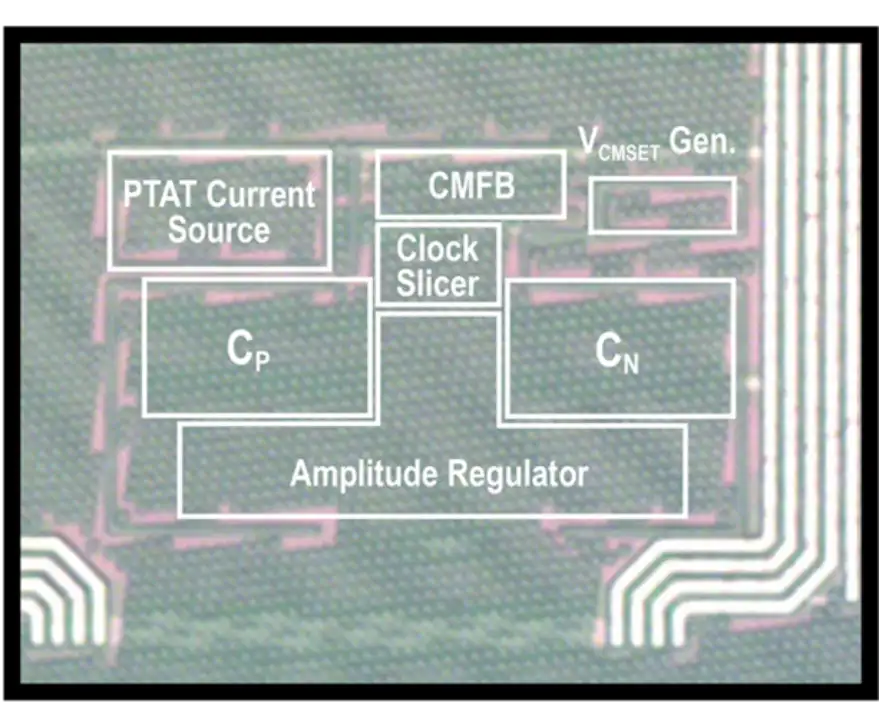
(b)晶振芯片顯微照片
超高速發送機芯片
不斷增長的通信需求持續推動有線通信鏈路向更高的數據速率演進,目前超高速有線收發機的數據速率已達到 100+Gb/s 量級。為了提高頻譜利用率,四電平脈沖幅度調制(PAM-4)在超高速鏈路中被廣泛采用。然而 PAM-4 調制方式面臨眼寬、眼高減小的挑戰。
北京大學蓋偉新教授團隊從電路設計和均衡機制方面入手,提出了可編程寬度的脈沖發生器,依靠脈沖寬度調節驅動器增益,從而實現最快信號翻轉速度,減小信號邊沿在碼元寬度中占據的比例,改善眼寬;提出了基于碼型的預加重均衡機制,通過檢測電路對待發送的信號碼型實時監測,在特定信號處以注入電流的方式加強信號,消除碼間干擾的同時避免輸出擺幅衰減。
基于上述創新設計,課題組研制了一款基于 28nm CMOS 工藝的超高速有線發送機芯片,并對芯片進行了性能測試與匯報。該發送機芯片實現了高達 128Gb/s PAM-4 的數據速率,并且取得了 1.4pJ/b 的能量效率。提出的可編程寬度脈沖發生器實現了 13% 的眼寬增長,且沒有額外的功耗代價;相比傳統前饋均衡,基于碼型的預加重均衡機制使得眼圖張開面積提高了約 25%。該電路可廣泛應用于數據中心、高性能計算等高通信需求的場景,為其提供高速率、高可靠的數據傳輸。
該工作以《A 128Gb/s PAM-4 Transmitter with Programmable-Width Pulse Generator and Pattern-Dependent Pre-Emphasis in 28nm CMOS》為題,發表于今年 ISSCC,文章的第一作者是北京大學集成電路學院博士生盛凱,文章的通訊作者是蓋偉新教授。
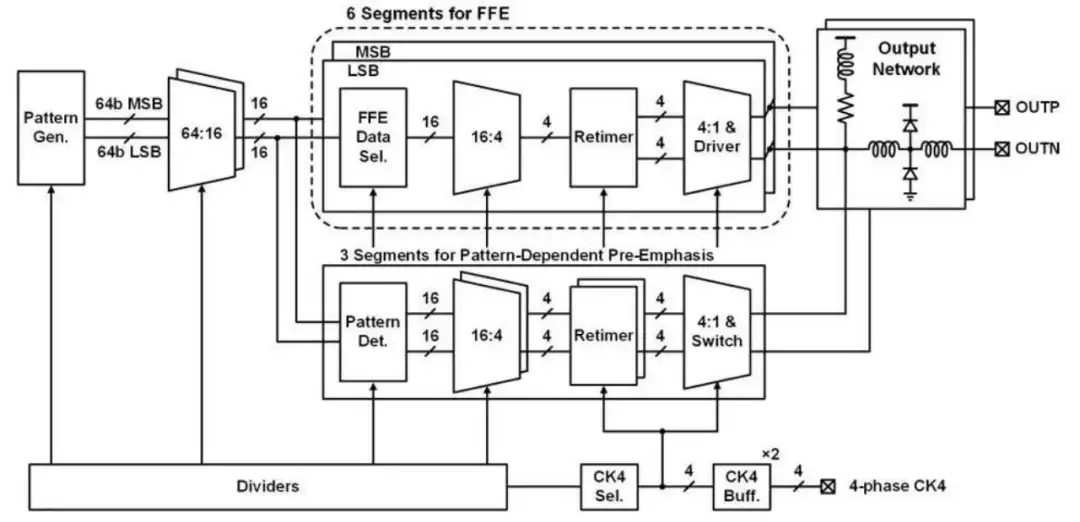
(a)發送機架構圖

(b)發送機芯片顯微照片
超高速接收機前饋均衡器芯片
該工作面向超高速串行傳輸應用,針對傳統判決反饋均衡器時序難以滿足、前饋均衡器采樣保持功耗較大的問題,設計并實現了一款超高速接收機前饋均衡器芯片,傳輸速率、均衡能力與能效比均為同類芯片最優水平。
北京大學蓋偉新-何燕冬教授團隊提出了基于延遲線與分布式抽頭的前饋均衡技術:該技術利用無源延遲線在超高速場景下損耗小的天然優勢,解決了對模擬信號延時的功耗與噪聲較大的問題,在實現 200Gb/s 超高速率均衡的同時,利用分布式結構降低了抽頭負載電容引入的信號反射;此外,通過在抽頭放大器中采用源極 RC 退化技術,賦予前饋均衡器靈活的低頻均衡能力,避免僅靠增加抽頭數量來消除長尾碼間干擾,大幅降低了電路功耗。
基于上述創新技術,課題組研制了一款基于延遲線的 200Gb/s 接收機前饋均衡器芯片。該芯片實現了對 200Gb/s 數據的均衡,可提供高達 17.2dB 的均衡能力,且能效比僅 0.43pJ/b,均為接收機連續時間前饋均衡器的最優水平。該均衡器芯片具有高帶寬、低功耗、低噪聲的優勢,可廣泛用于數據中心、Chiplet 等串行數據傳輸應用中,為未來短距 200Gb/s 接收機提供了全新的低功耗解決方案。
該工作以《一款 28nm 工藝下, 基于延遲線技術并支持低頻均衡的 0.43pJ/b, 200Gb/s,5 抽頭接收機前饋均衡器》(A 0.43pJ/b 200Gb/s 5-Tap Delay-Line-Based Receiver FFE with Low-Frequency Equalization in 28nm CMOS)為題,發表于今年 ISSCC 先進有線互連技術(Session 6: Advanced Wireline Links and Techniques)分會場,文章的第一作者為北京大學集成電路學院博士生葉秉奕,文章的通訊作者為蓋偉新教授。
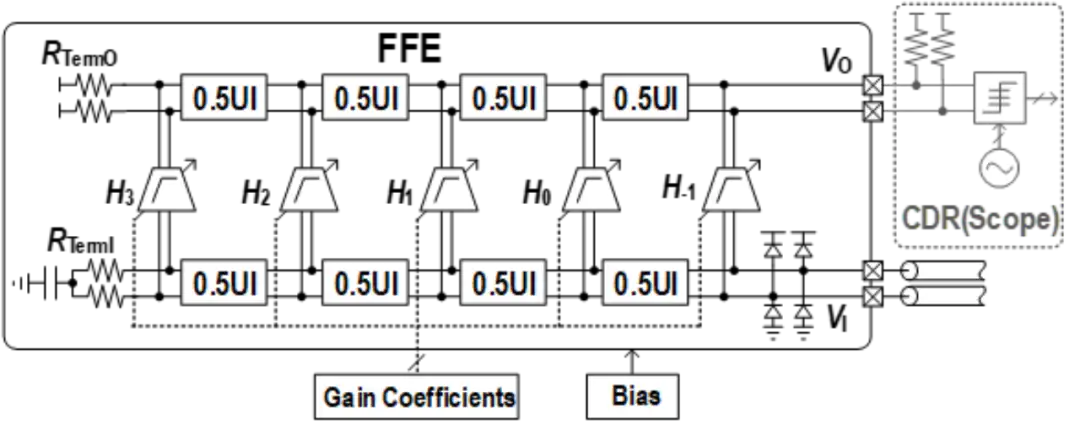
(a) 接收機前饋均衡器架構圖
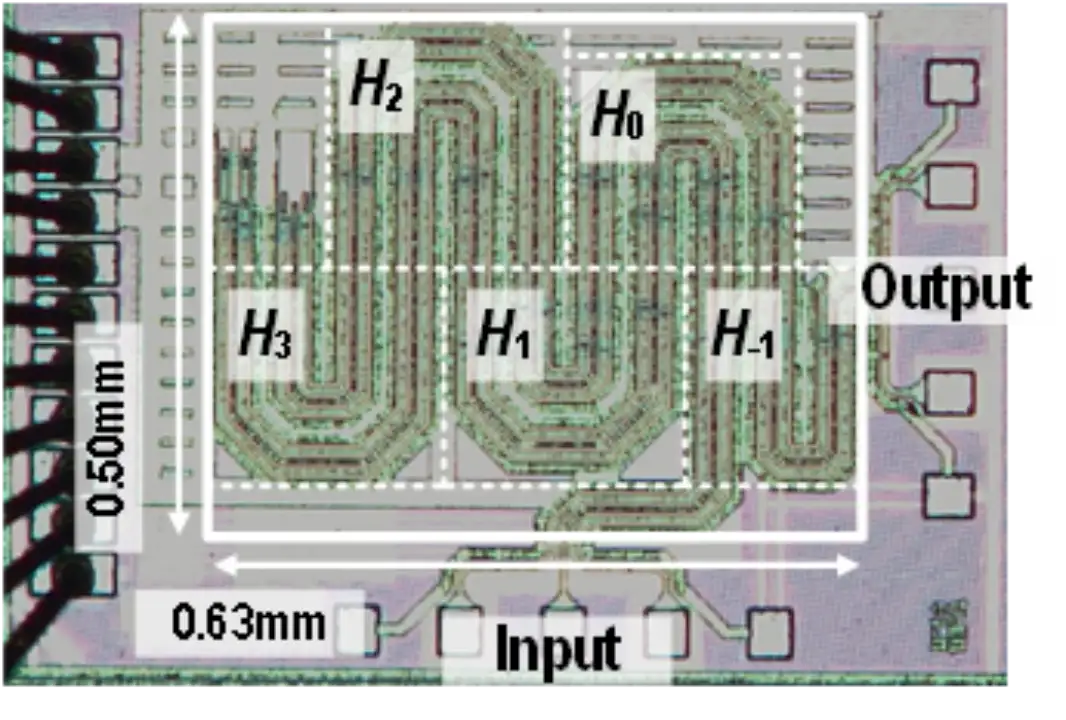
(b)均衡器芯片顯微照片
高能效模數轉換器芯片
面向語音識別、智慧醫療等多種物聯網應用,針對其對中等帶寬信號實現高精度、高能效采集的需求,本工作實現了一種在性能上國際領先且易于驅動和系統集成的增量型縮放式模數轉換器,相比于其他同類型的縮放式模數轉換器設計取得了最高的帶寬和最低的驅動需求。
本工作在縮放式模數轉換器的架構和電路方面提出了新的設計方法:在架構方面,首次采用噪聲整形逐次逼近型量化器進行縮放式模數轉換器中的細量化,并提出了一次采樣多次量化的量化方法,大幅降低了對采樣電路的要求,提升了系統的帶寬;在電路方面,提出了一種新型的環路濾波器電路設計方法,該方法僅需要一個動態緩沖器即可實現高階、高魯棒性的環路濾波器,顯著降低了系統硬件開銷和功耗。
基于上述創新技術,課題組研制了一款基于 28nm CMOS 工藝的增量型縮放式模數轉換器芯片。該款芯片一次模數轉換僅需要 8 次采樣,在低頻 2.5kHz 和中頻 20kHz 的輸入信號下分別達到了 92.5dB 和 92.2dB 的信噪失真比,系統功耗為 160μW,在同類的縮放式模數轉換器中具有最高的輸入帶寬(150kHz),且易于驅動,單次轉換所需的輸入驅動開銷最小,整個系統達到了國際領先的模數轉換器能效水平(182.2dB FoM)。該電路可廣泛應用于多種物聯網應用場景,并且為如縮放式模數轉換器的多步模數轉換器提供了新的實現和量化方法。
該工作以《A 150kHz-BW 15-ENOB Incremental Zoom ADC with Skipped Sampling and Single Buffer Embedded Noise-Shaping SAR Quantizer》為題,發表于今年 ISSCC,文章的第一作者是北京大學集成電路學院博士生王宗楠,文章的通訊作者是唐希源研究員。
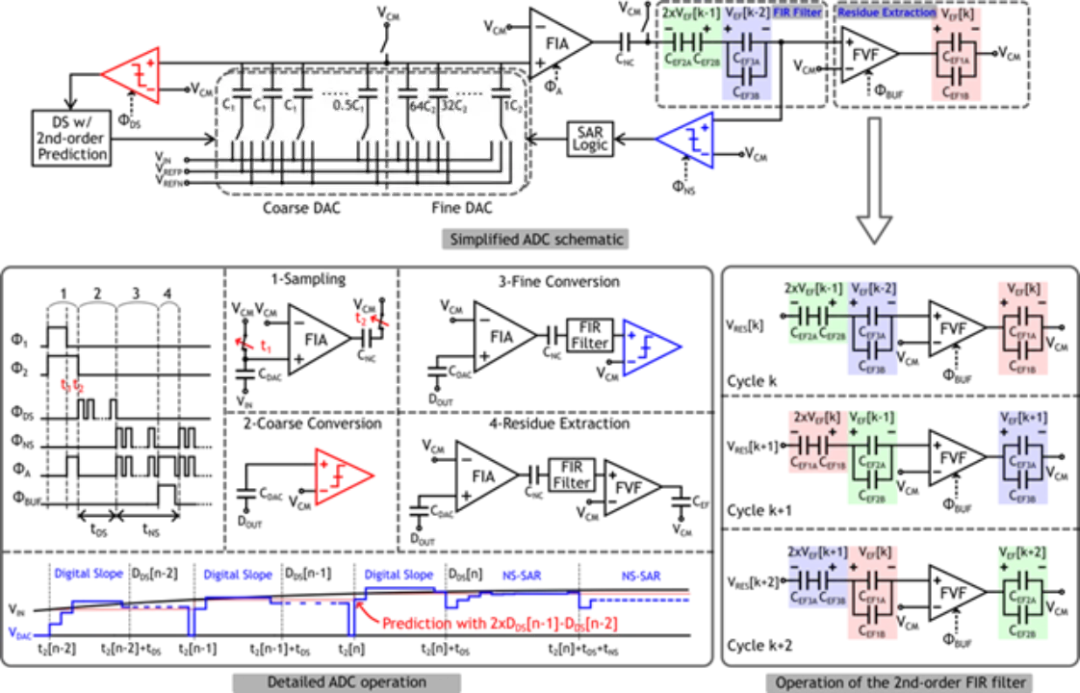
(a) 縮放式模數轉換器電路及原理圖
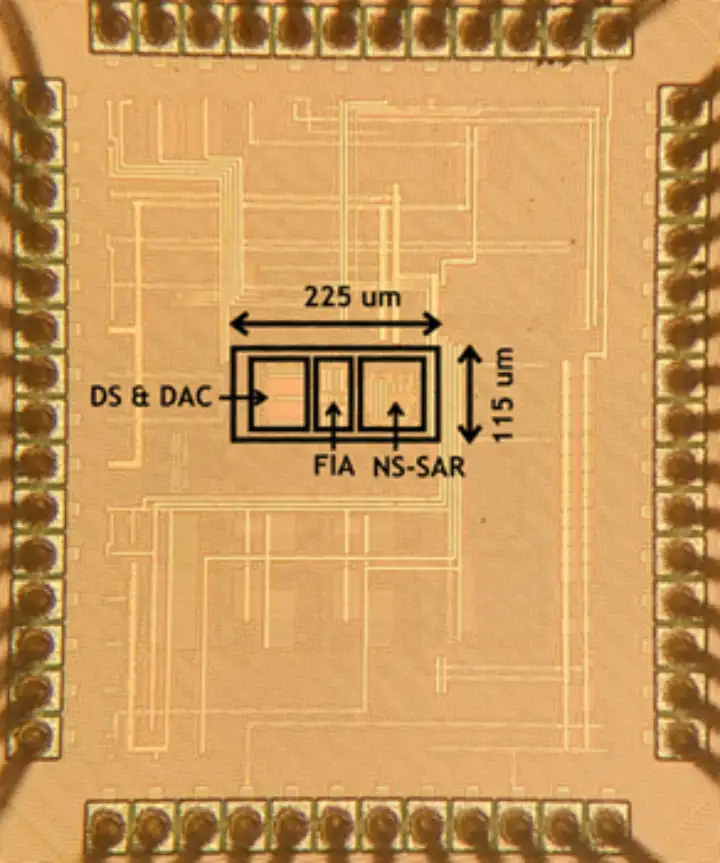
(b)縮放式模數轉換器芯片顯微照片
以上北京大學論文的相關研究工作得到了國家重點研發計劃、國家自然科學基金、北京市科委、浙江省重點研發計劃等項目的資助,以及國家集成電路產教融合創新平臺、微納電子器件與集成技術全國重點實驗室、微電子器件與電路教育部重點實驗室、集成電路高精尖創新中心、集成電路科學與未來技術北京實驗室等基地平臺和浙江省北大信息技術高等研究院、杭州微納核芯電子科技有限公司的支持。










評論