小議車輛環境視覺基礎前視感知

前言
無論是AD/ADAS還是智能網聯車,前視感知都是其最基礎和重要的能力之一。自動駕駛(AD)是前幾年的熱門話題。今天雖然稍微降溫下來一些,但仍是大家關注的重點之一,畢竟它是人類長久以來的夢想之一。眾所周知,美國汽車工程師學會(SAE)將自動駕駛分為L0~L5共六個級別。其中L3及以上允許由系統在限定或不限定條件下完成所有的駕駛操作;而L2及以下還是需要由人類駕駛員一直保持駕駛狀態,因此大多還屬于高級駕駛輔助系統(ADAS),如車道偏離預警(LDW),前碰撞預警(FCW),自適應巡航(ACC),緊急自動剎車(AEB),車道保持輔助(LKA),交通標志識別(TSR),自動泊車(AP)等。和大多數智能機器人一樣,自動駕駛的處理流程可分為三個階段:感知、決策、執行。因此一旦感知出了問題,那后面基本就涼了。類似地,ADAS或AR導航也強依賴于對環境的感知。沒有準確且實時的感知能力,上層做的再炫酷也容易成為雞肋。ADAS和AD間的界線并沒那么清晰,前者可看作到后者的過渡產品,因此很多技術是通用的。前視感知是個非常大的話題,因此本文主要聚焦在一些最為基礎和通用的前視感知能力上。
2.業界
本節我們從工業界和學術界兩個方面簡要聊下業界的相關情況。它們各有優缺點,學術界涌現出更前沿更先進的方法,且指標明確,易于定量比較,但方法往往專注于單點,且對實際產品中的各種約束(如計算資源)考慮不多;而工業界直接面對產品,更多地考慮實用性和整體性。但采用的指標、數據不透明,難以衡量和比較。只有全方面的了解,通過產學研的加速融合,才能打造更加完善、更好用戶體驗的產品。
ADAS有著幾十年的發展歷史。國內外都有一大批優秀的廠商。這幾年,隨著國家駕駛安全政策的推動和自動駕駛技術受到熱捧,該領域出現了快速的增長。從老牌勁旅Bosch、Continental、Aptiv,Mobileye等,到一批相對年輕但很有競爭力的公司如Maxieye、Minieye、魔視、極目、縱目、Nauto等,這是一個既成熟,又充滿機遇的市場。根據中投顧問的《2017-2021年中國汽車高級駕駛輔助系統(ADAS)市場深度調研及投資前景預測報告》,ADAS年復合增長率將達35%,2020年中國市場可實現近800億市場空間。近幾年,車載AR導航將傳統的ADAS功能與導航功能、AR技術及HUD進行了融合,帶來了更直觀和人性化的用戶體驗,成為了市場的熱點。在實現方式上,各家在傳感器配置上也各有不同,有攝像頭、毫米波雷達、激光雷達等。其中,基于攝像頭的視覺方案由于其成本可控、算法成熟等優點,使用最為廣泛。其中的主要代表如Mobileye和Tesla Autopilot都是主要基于視覺的方案。

圖1 Tesla Autopilot(來自https://www.youtube.com/watch?v=24dRkHdpEPo)

圖2 Mobileye(來自https://www.mobileye.com/our-technology/)
雖然ADAS細分功能眾多,但很多功能功能(LDW,FCW,LKA,ACC等)都依賴于對前方環境中幾個基本對象的檢測和識別,即車道線、物體(包括車輛、行人、障礙物、交通燈、交通標識等)、可行駛區域,因此本文也會主要聚集在這幾類對象的檢測識別上。在準確率上,各家的產品往往很難量化及橫向比較,盡管大家的宣傳中常會出現“準確率>XX%”或者“誤報率/漏報率<X%”這樣的提法。但事實上由于指標定義和數據集的差異,很難做到“apples to apples”的對比。有些比較實在的會采用相對指標,比如與行業標桿(如Mobileye)在同樣的數據集上做橫向對比。這樣會更有說服力。但因為所用數據集未公開,別人也很難嚴格橫向比較。在性能上,由于ADAS對檢測的實時性要求非常高,所以很多至少會做到15 FPS以上。隨著深度學習的興起,越來越多的ADAS廠商也將基于傳統CV的方案逐漸過渡為基于深度學習的方案。深度神經網絡(DNN)的推理需要很大的計算量,而ADAS不像高級自動駕駛平臺配備強大的計算平臺,因此業界的趨勢之一是利用專用硬件(如FPGA或ASIC芯片)來進行加速。
在學術界,自動駕駛一直是經久不衰的熱點之一。這些方法上的創新很多同樣也可以用于ADAS和AR導航中。我們知道,2012年以來深度學習的快速發展使其成為機器學習中的絕對主流。基于深度學習的方法同樣也給自動駕駛帶來了巨大變革。基于傳統CV算法的方法在泛化能力上容易遇到瓶頸。經常是在一段路段調優跑溜后,換一段路又需要大量調參。當然,基于深度學習的方法也無法完全避免這個問題,但可以說是大大緩解了。學術界的優點就是較為透明公開、且容易對比。新的方法就是需要在與其它方法比較中才能證明其優異,因此歷史上通過競賽的方式來推動發展的例子不在少數。2004年開始,由DARPA主辦的幾場無人車挑戰賽開啟了無人車的新時代。在深度學習時代,各種針對路面環境檢測識別的榜單就如同ImageNet一樣,催生出一大批新穎的方法。其中針對車道線、物體和可行駛區域的比較典型的有:
KITTI:2013年由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創辦,是一套非常全面的算法評測數據集。其中覆蓋了2D、3D物體檢測,物體跟蹤,語義分割、深度估計等多種任務。但其數據集數量在現在看起來不算多,如物體檢測數據集訓練集和測試集總共1W5張左右,車道檢測就比較尷尬了,只有幾百張。
CVPR 2017 TuSimple Competitions:2017年圖森未來主持的挑戰賽,分車道線檢測和速度估計兩個任務。其中車道線檢測數據集包含了幾千張主要是高速上的數據。雖然量不多,但因為和物體檢測這類通用任務相比,針對車道線檢測的競賽很少,所以它至今在很多車道線檢測的論文上還會被當成量化比較的重要參考。
CVPR 2018 WAD:由Berkeley DeepDrive主持,包含三項賽事:道路物體檢測,可行駛區域分割和語義分割的域適應。它基于BDD100K數據集。這是一個在數量和多樣性上都非常不錯的用于自動駕駛的數據集。其中用于物體檢測和可行駛區域分割的數據集共有10W張左右,其中訓練集和驗證集有約8W張。
Cityscapes:針對道路環境的經典語義分割數據集,同時也提供了語義分割、實例分割和全景分割任務的榜單。數據集采自50個城市,包含了5K張精細標注圖片和2W張較粗糙標注圖片。考慮到語義標注的成本相對大,這個數量已經算比較大了。
其它的榜單還有很多,無法一一列舉。雖然由于大多榜單只關注準確率導致其模型很難直接落到產品中,但其中確實也出現了非常多精巧的方法與創新的想法,為產品落地提供了有價值的參考。關于具體的方法我們留到后面專門章節進行討論。
還有一些介于工業界與學術界之間的工作,它們將學術界的成果向產品逐漸轉化,提供了參考實現。比較典型的有開源自動駕駛項目Apollo和Autoware。因為它們主要面向無人駕駛,所以會除了攝像頭之外,還會考慮激光雷達、毫米波雷達、高精地圖等信息。由于本文的scope,這里只關注基于攝像頭的對基礎對象的檢測。Apollo 2.5中采用的是一個多任務網絡檢測車道線與物體(之前讀代碼的一些筆記:自動駕駛平臺Apollo 2.5閱讀手記:perception模塊之camera detector),對于車道線模型會輸出像素級的分割結果,然后通過后處理得到車道線實例及結構化信息(相關代碼閱讀筆記:自動駕駛平臺Apollo 3.0閱讀手記:perception模塊之lane post processing);物體檢測是基于Yolo設計的Yolo 3D,除了輸出傳統的2D邊界框,還會輸出3D物體尺寸及偏轉角。版本3.0(官方介紹:perception_apollo_3.0)中加入了whole lane line特性,提供更加長距的車道線檢測。它由一個單獨的網絡實現。3.5中將物體與車道線檢測網絡徹底分離,車道線模型稱為denseline。最新的5.0(官方介紹:perception_apollo_5.0)中又引入DarkSCNN模型,它基于Yolo中的backbone Darknet,并引入了Spatial CNN(后面再介紹),同時該網絡中還加入了對滅點的檢測。Autoware中車道線用的是傳統CV的方法,物體檢測基于攝像頭部分使用的是SSD和YOLO等基于深度學習的方法(官方介紹:Overview)。
3.方法
我們知道,深度學習有三大基石:數據、算法和算力。對于基礎前視感知場景,我們也從這三個維度來聊一下。在此之前,我們先列下本文關注的單目基礎感知主要流程:

圖3 基礎前視感知簡要流程
從圖片流輸入,大致經歷預處理、檢測模型推理和后處理三個階段:
預處理:這一階段主要是做必要的數據處理,為后面的檢測準確好數據。如一些攝像頭進來的視頻流是YUV格式,而深度神經網絡模型輸入多是RGB格式,需要進行轉換。此外,很多模型會要求輸入數據作歸一化。另外,為了減少計算量,一般還會對輸入的圖像進行縮放和ROI的提取。
檢測模型推理:這一階段主要是做深度神經網絡的推理。對于要同時完成多個任務的場景,我們一般會使用多任務網絡。即每個任務對應一個網絡分支輸出,它們共享用于特征提取的backbone(按經驗很多時候backbone會占大部分的計算量)。近年學術界也出現一些對不同類型任務比較通用的backbone結構。
后處理:這一階段是將前面推理得到的結果進行進一步的處理,以傳到后面的決策或展示模塊。常見的對于車道線需要濾除噪點,聚類,曲線擬合,濾波(如Kalman filter)等;對物體檢測常見的有非極大值抑制(NMS)和跟蹤等;對可行駛區域,需要將分割結果轉為多邊形并確定其位置類別。
注意這里只畫了簡化的部分流程。實際場景中,可能還需要考慮非常多其它元素,比如:
相機標定(Camera calibration):我們在學車考“S彎”或者“單邊橋”等項目時,教練往往會告訴我們一些小技巧,如通過雨刮器的位置來估計輪胎的位置。這種技巧其實比較脆弱,因為座椅的調整,人的高矮都會影響其精確度。那在ADAS/AD場景中如何告訴機器以高精度做這件事呢,就是通過相機校準。這本質是做圖像坐標和世界坐標之間的轉換。另外,有了校準參數,我們還可以用它做逆透視映射(IPM),消除透視帶來的影響,方便車道線檢測及物體跟蹤等模塊。
光流(Optical flow):每一幀都檢測會帶來很大的計算開銷。有時我們會通過光流算法來計算圖像中像素點的瞬時速度,從而估計已檢測對象在當前幀的位置。這樣一方面能有效減少計算量,另一方面還能用于物體的跟蹤。
滅點(Vanishing point):我們知道,由于透視關系,平行的線(如車道線)在遠處會交到一點,稱為消失點或滅點。這個點對于車道檢測或最后的可視化都有幫助。在直線的情況下,我們可以通過車道線的交點來估計滅點,但如果車道線是不太規則的曲線,就比較麻煩,需要通過更復雜的方法進行估計。
測距:不少ADAS功能中都需要確定前方物體的距離。常用毫米波和超聲波雷達做距離檢測。而在純視覺方案中,雙目方案是根據視差來估計距離,原理就像人的兩只眼睛一樣。而對于單目方案就比較tricky一些,需要檢測物體后根據物體下邊界結合相機標定計算距離。現在雖然有基于單張圖像的深度估計方法,但那個本質上是靠的訓練所獲得的先驗,用作ADAS里的FCW啥的感覺還是精度不太夠。
3D姿態估計(3D pose estimation):高級點的前視感知對物體檢測除了邊界框,還會估計其姿態。這對動態障礙物的行為預測非常有幫助。
細粒度識別(Fine-grained recognition):對于一些識別的物體,如果它們的類別會影響到駕駛行為(如交通燈、交通標志、車道線等),則我們需要將檢測結果中相應部分拿出來進一步對其進行分類識別。
決策和展示:所有的檢測都是為了最后的決策和展示。如何自然地顯示(如通過AR展示的話如何與現實物體貼合),以及何時預警或介入控制都直接影響用戶體驗。
另外可能還需要檢測路面上的指示標記,以及對當前場景是否支持作檢測判斷等等。由于篇幅有限和使內容簡潔,這些本文都暫不涉及。檢測對象上本文主要關注車道線、物體和可行駛區域。
3.1數據
我們知道,深度學習的最大優勢之一就是能對大量數據進行學習。這就意味它的效果很大程度上依賴于訓練的數據量,而對于汽車的前視感知更是如此。因為汽車的環境是開放的,沒有充分而多樣的數據,模型便無法有效地泛化,那在各種corner case就可能出岔子。對于其它場景出岔也就出岔了,對AD或者ADAS來說那可能就危及生命安全了。數據集大體有兩類來源,一類是公開數據集;一類是自標數據集。它們各自有優缺點。
得益于自動駕駛領域的蓬勃發展,近年來出現了很多優質的公開數據集。
包含車道線的主要有BDD100K,CULane,TuSimple Lane Challenge和LLAMAS等。
包含物體檢測的太多了,貌似是個道路環境數據集就會有。如BDD100K,KITTI,Udacity Driving Dataset,Waymo Open Datasets等。
包含可行駛區域的有BDD100K,KITTI等。雖然理論上語義分割的數據集(如Cityscapes)就包含了可行駛區域的標注,但比較理想的標注還應該區分當前車道和相鄰車道。
其它的還有不少數據集,網上有很多列表整理,這里就不重復了。雖然這些數據集很豐富,但有時未必能直接用上。一方面是它們的標注之間有很大差異。其中一個差異點是標注格式,這個其實還好辦,腳本基本能搞定。比較麻煩的是有時候標注的規范和內容會有出入。以車道線為例:有些是采用雙線標法(如BDD100K),有些是單線標法(如CULane,TuSimple Lane Challenge);有些是標有限條(如CULane),有些是有多少標多少(如BDD100K);有些對于虛線是像素級精確標注(ApolloScape),有些是會將它們“腦補”連起來(CULane);有些標了車道線類型(BDD100K),有些沒有標(CULane)。而對于車輛和行人來說,不同數據集有不同的細分類。但本著人家標注也不容易,能用上一點是一點的精神,可以盡可能地對它們進行轉化,使它們一致并滿足特定需求。舉例來說,BDD100K中是雙線標注,而其它多數是單線標。為了統一,我們可以通過算法自動找到匹配的線并進行合并。自動合并效果如下:

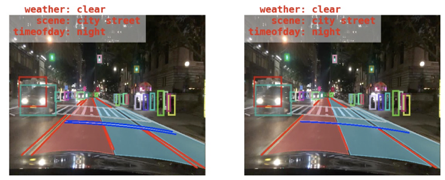
圖4 BDD100K數據集車道線標注自動轉換
公開的數據集雖然方便且量大,但往往沒法完全滿足需求。比如由于地域差異、攝像頭差異等會導致domain shift問題,另外有些針對性的case沒法覆蓋。公開數據集另一個問題是license。很多的公開數據集只能作研究用途,如果要商業用途是禁止或者需要專門再購買license的。因此,實際中往往還是需要請外包或自己標數據。
另外,為了獲得更大量更多樣的數據,業界有一些常用方法和方向,如:
數據增強(Data augmentation):最基本也很有效的擴充數據集手段之一,在車輛環境中尤為重要。由于道路環境數據集需要多樣化,因此我們需要通過數據增強來模擬不同的光照、天氣、視角等變化。
自動標注/輔助標注:雖然移動端上由于算力有限,我們只能犧牲準確率布署輕量級的網絡,但我們可以訓練重量級的精度較高的網絡模型用于對數據進行自動標注。以下是一個重量級網絡(不是SOTA的)在BDD100K上訓練后的檢測效果。雖然不是十全十美,但在有些小目標上可能比老眼昏花的我還要標得湊合。就算無法完全替代人肉標注也可以作為輔助有效減少人工。

圖5 某重量級網絡在BDD100K數據集上檢測效果(左:檢測結果;右:Ground truth)
仿真器:利用仿真器來幫助自動駕駛測試似乎已經是一個普遍性做法了。隨著3D圖形技術和硬件的飛速發展,今天仿真器中的渲染效果已相當逼真,已經不像當年賽車游戲里車后冒個煙還是“馬賽克”效果。因此,仿真器也有望用于產生可用于訓練的數據。
生成對抗網絡(GAN):我們知道,GAN是最近幾年非常火熱的一個方向。GAN也在一些工作中用于訓練數據的生成。雖然目前很多時候是看demo各種牛,但實際跑的時候可能就不是很理想。但不可否認這是一個很有前途的方向,不少工作應用它來緩解數據多樣化需求的問題。
3.2算法
針對前視感知中的幾類目標,算法是不同的。另一方面,我們知道深度學習的視覺領域研究比較多的任務是:圖片識別、物體檢測、圖像分割(包括語義分割、實例分割、全景分割)。那么問題來了,如何將對現有任務的方法充分應用來滿足前視感知的需求?如果實在不合適如何調整?
3.2.1車道線
首先是車道線檢測,這可能是幾類檢測目標中最特殊的,所以占的筆墨也會相對多些。它的特點是形狀狹長(可能跨越大半張圖片),并且形態多變(可能是直線也可能是曲線,還可能交叉等),容易與路面標識混淆,另外還需要區分實例。現有物體檢測的方法不太適合這種形狀的東西。我們知道,在深度學習占領視覺領域前,車道線檢測多采用傳統CV的方法。Udacity(其聯合創始人Sebastian Thrun是自動駕駛界大神)上有一個自動駕駛課程。其中有作業就是車道線檢測,因此網上有很多這個作業的實現。其中比較關鍵的幾步是通過邊緣檢測算法(如Canny,Sobel算子)得到邊緣,然后通過Hough transform檢測直線(如果假設車道線為直線),或者經過IPM得到鳥瞰視圖后通過滑窗搜索得到車道線上的像素點,最后多項式曲線擬合輸出。這里邊幾乎每一步都有不少參數,而且各步相互影響,如果場景很多樣化的話調參就可能會比較酸爽,另一方面它對于車道線不完整的情況(如因遮擋或磨損)表現不好。因此,這已經不是目前的主流,后面業界逐漸過渡到基于深度學習的方法。
2015年,深度學習風頭正勁,Stanford、Twitter等機構聯合發表的論文討論了將CNN應用到高速環境的車道線和車輛檢測中[1]。它使用當時物體檢測的方法[2]來檢測車道線。因為車道線很長條,因此被分成多個線段,每個線段被當成物體來檢測。最后通過DBSCAN進行聚類得到車道線實例。同期另外一條思路是將車道線檢測當作語義分割任務。當時語義分割領域有了FCN[3]、SegNet[4]和DeepLab[5]等早期經典網絡。結合一些包含車道線標注的語義分割數據集便可以進行車道線檢測。如論文[6]試圖將包括車道線在內的多種檢測任務在分割任務中一把搞定。然而故事還遠沒有結束,這里還存在以下兩個比較大的挑戰,接下去幾年的工作也是主要圍繞這兩點來展開:
繁瑣的后處理:現實中我們為了后面的決策還需要知道哪條是當前車所在車道(Ego lane)的左、右車道線和相鄰車道的車道線。另外,因為車道線往往不完整,因此還需要得到車道線的結構化表示(如多項式或樣條曲線)以便做插值。這樣,單就語義分割的結果還不夠。以往常見的做法是將分割結果進行聚類得到實例,然后通過一些后處理判斷其是哪條車道。另外,為了得到結構化表示還需要對這些點進行多項式擬合等操作。理想的方法是簡化或完全去除這些后處理,實現真正意義上end-to-end的檢測。
復雜的環境:路面環境復雜常常導致圖像中的車道線殘缺不全。如天氣因素,其它車輛遮擋,陰影和光照,磨損等等。另外的一個比較大的干擾來自于地面上的箭頭指示和漢字,僅看局部圖像的話人也難以區分。因此如果無法有效利用全局上下文信息很難對它們進行排除。對這些因素做到足夠魯棒是通往實用產品的必要條件。
來自三星的論文[7]將車左右兩條車道線作為兩個類別(加上背景共三類),從而直接通過神經網絡來學習,相當于做了實例分割,從而簡化了后處理。
2017年TuSimple主辦了車道線檢測競賽,炸出不少好的方法,同時也成為了車道線檢測的重要benchmark之一。第一名來自香港中文大學,它也是基于語義分割來做,并針對車道線這種狹長的物體提出了Spatial CNN(SCNN)[8]來替代MRF/CRF來對空間關系進行建模。另一個比較有意思的點是當時競賽提供的數據集才幾千張(標注圖片約3.6K),因此數據可能會成為主要瓶頸之一,于是他們整了一個大規模的車道線的數據集CULane。該數據集共有13W多張。它比較貼近現實情況,涵蓋了白天、晚上、擁堵、陰影、光照過亮等9種場景。對于車道線的實例區分問題,SCNN由于限定最多檢測4條車道線,因此它可以把4條車道線當4類物體來檢測。同時,網絡還有一個專門的分支用于預測對應的車道線是否存在。這樣便不需要聚類來提取實例。當時的第二名來自佐治亞理工(Georgia Institute of Technology)等機構。他們提出的方法[9]可以解決只能處理有限車道線的問題。它利用像素對之間的關系,通過對目標函數的巧妙構造,讓神經網絡學習像素的聚類信息。并且可以拓展到(理論上)無窮實例的場景。
2017年韓國KAIST和三星提出了VPGNet[10]。它是一個多任務網絡,其中一個分支用于預測滅點,它可以引導車道線的檢測。這在一些惡劣的天氣下可以有比較大的幫助。但這需要額外標注的數據集。論文中提到他們建立了自己的數據集但沒有公開。
2018年,魯汶大學(KU Leuven)的論文提出LaneNet[11],它將車道線檢測作為一個實例分割問題。以前很多方法對于提取車道線實例是用聚類,而對于車道線這種狹長的物體很難定義一個好的距離測度用于聚類。這篇論文的最大特色就是在傳統語義分割分支外還加了一個pixel embedding分支,用于對輸入圖像中的每個點得到其N維的embedding,這個分支是基于其實例信息訓練的。語義分割輸出的像素結合pixel embedding信息,作聚類后便可得到車道線的實例信息,最后通過多項式擬合輸出。魯汶大學這個團隊次年在論文[12]中把預測曲線與ground truth曲線間的面積作為損失函數,將擬合改造成可微分操作,從而讓神經網絡來學習擬合曲線的參數。前面LaneNet這篇論文另一個比較有特色的點是H-Net。IPM有利于車道線的多項式擬合。因為大多數彎曲的車道線在鳥瞰視圖下用二次曲線就夠了,但在透視視圖下卻需要更高階曲線才能擬合。而這個變換的參數一般需要通過相機標定。但是這個參數可能根據地形、坡道因素不同。因此最好可以根據輸入動態調整。H-Net采用通過神經網絡來預測的方式。這條思路上類似的工作還有來自2018年GM的3D-LaneNet[13]。該方法以end-to-end方式直接預測3D的車道線。網絡采用dual-pathway結構。一條對應普通透視圖,估計逆透視變換參數。該參數結合前面的feature map與另一條對應鳥瞰視角的網絡中feature map結合,最終輸出3D車道線。不過畢竟帶3D車道線標注的數據集不好弄,于是他們自己搞了個高速場景下的合成數據集作了實驗。因此該方法在真實場景下的效果還需要進一步驗證。
杜克大學和地平線提出的LaneNet[14](也叫LaneNet,但此LaneNet非彼LaneNet)將車道線檢測分為兩個階段-lane edge proposal和lane line localization。前者是一個語義分割網絡;后者是比較特色的地方,其網絡基于LSTM,輸出為各條車道線的信息。因此,某種程度上替代了很大部分后處理。
TomTom公司提出的EL-GAN[15]通過GAN的思想來改善語義分割的結果。單純的語義分割應用于車道線所得結果不會考慮其平滑或是鄰域一致性等。EL-GAN在GAN的基礎上添加了embedding loss通過discriminator讓語義分割的輸出更接近ground truth。直觀上這樣語義分割的結果就會更符合車道線的拓撲形狀特征,從而減化了后處理的工作。
我們知道,對于視覺任務,有兩個比較通用的思路是可以幫助提高準確率的。一個是注意力(Attention)機制。今年由香港中文大學等機構發表的論文[16]提出了Self Attention Distillation(SAD)方法。它基于注意力蒸餾(Attention distillation)的思想,將之改造為自蒸餾,從而不依賴傳統知識蒸餾中的teacher model。網絡中后面的層的feature map(具有更豐富上下文信息)作為監督信息幫助前面的層訓練。前面的層學到更好的表征后又會改善后面的層,構成良性循環。另一個是用RNN結合前后幀信息。武漢大學和中山大學的論論文[17]結合了CNN和RNN來使用連續幀進行車道線檢測。網絡結構中在由CNN組成的encoder和decoder間放入ConvLSTM用于時間序列上特征的學習。由于結合了前面幀的信息,在車道線磨損、遮擋等情況下可以做到更加魯棒。
3.2.2道路物體
然后是物體檢測,這塊的算法可以說是相當豐富。因為物體檢測的應用范圍非常廣,因此它幾乎伴隨著計算機視覺領域的發展。相關的survey很多(如[18],[19]等)。深度學習興起后,一大波基于深度神經網絡的物體檢測算法被提出。SOTA以極快的速度被刷新。從two-stage方法到輕量的one-stage方法,從anchor-based方法到近年很火的anchor-free方法,從手工設計到通過自動神經網絡架構搜索,琳瑯滿目,相關的總結與整理也非常多。
對于道路環境來說,幾乎和通用物體檢測算法是通用的。如果要找些區別的話,可能汽車前視圖像中,由于透視關系,小物體會比較多。2018年CVPR WAD比賽其中有一項是道路環境物體檢測。第一名方案來自搜狗,根據網上介紹(給機器配上“眼睛”,搜狗斬獲CVPR WAD2018挑戰賽冠軍),其方案在Faster R-CNN的基礎上使用了CoupleNet,同時結合了rainbow concatenation。第二名方案來自北京大學和阿里巴巴,提出了CFENet[20]。經典的one-stage物體檢測網絡SSD在多個scale下的feature map進行預測,使得檢測對物體的scale變化更加魯棒。小目標主要是通過淺層的較大feature map來處理,但淺層特征缺乏包含高層語義的信息會影響檢測效果。CFENet針對前視場景中小物體多的特點對SSD進行了改進,在backbone后接出的淺層上加入CFE和FFB網絡模塊增強淺層特征檢測小目標的能力。
現實應用中,物體檢測模型的輸出還需要經過多步后續的處理。其中比較常見和重要的是NMS和跟蹤:
神經網絡模型一般會輸出非常多的物體框的candidate,其中很多candidate是重疊的,而NMS的主要作用就是消除那些冗余的框。這個算子很多的推理框架不支持或支持不好,所以一般會放到模型推理外面作為后處理來做。在學術界NMS這幾年也出現了一些可以提高準確率的變體。
跟蹤是理解物體行為的重要一環。比如幀1有車A和車B,幀2有兩輛車,我們需要知道這兩輛車哪輛是A,哪輛是B,或都不是。只有找到每個物體時間維度上的變化,才能進一步做濾波,以及相應的分析。比較常見的多物體跟蹤方法是SORT(Simple Online and Realtime Tracking)框架[21],或許它的準確率不是那么出眾,但綜合性能等因素后還是不錯的選擇,尤其是對于在線場景。結合通過CNN提取的外觀特征(在DeepSORT[22]中采用)和Kalman filter預測的位置定義關聯度的metric,將幀間物體的跟蹤作為二分圖匹配問題并通過經典的匈牙利算法求解。前后幀物體關聯后通過Kalman filter對狀態進行更新,可以有效消除檢測中的抖動。
3.2.3可行駛區域
再來說下可行駛區域。開過車的同志們都知道咱們的很多路沒有那么理想的車道線,甚至在大量非結構化道路上壓根兒就沒有車道線。在這些沒有車道線、或者車道線不清晰的地方,可行駛區域就可以派上用場。一般在可行駛區域中我們需要區分當前車道和其它車道,因為該信息對后面的決策規劃非常有價值。
在這個任務上早期比較流行的榜單是KITTI的road/lane detection任務。很多論文都是拿它作benchmark,其榜單上有一些是有源碼的。不過那個數據量比較少,多樣化程度也不夠,要用它訓練得泛化能力很強實在比較勉強。
2018年CVPR WAD比賽中一個專項是可行駛區域檢測。所用的BDD100K數據量相比豐富得多。當時的冠軍方案是來自香港中文大學的IBN-PSANet。它的方案是結合了IBN-Net[23]和PSANet[24]。前者主要特色是結合了batch normalization(BN)和instance normalization(IN)。BN幾乎是現代CNN的標配。它主要用于解決covariate shift問題,提高訓練收斂速度;而IN可以讓學習到的特征不太受像顏色、風格等外觀變化的影響。而結合了兩者的IBN可以吸收兩者的優點。而PSANet的特色主要是提出了PSA結構,它本質是一種注意力機制在視覺上的應用。對于每一個像素,網絡學習兩個attention mask,一個對應它對其它每個像素的影響,一個對應其它每個像素對它的影響,從而使得分割可以充分考慮全局上下文信息。
可行駛區域檢測中對于語義分割的輸出比較粗糙,且形式不易于后面模塊處理,因此還需要經過一些簡單的后處理。比如先聚類,再計算各類簇的凸包,最后通過這些多邊形的位置關系便可以確定它們是當前車道還是其它車道的可行駛區域。
值得一提的是,可行駛區域和車道線語義上是非常相關的,因此可以通過相互的幾何約束來提高準確率。業界也有不少這方面的嘗試,越來越多的深度神經網絡將它們進行融合。
3.3優化
從算法到產品最大的鴻溝之一便是性能優化。移動端設備有限的算力正在與多樣化算法的算力需求形成矛盾。這在之前寫的文章《淺談端上智能之計算優化》中進行過初步的討論。對于像ADAS這樣的場景實時性尤其重要。我們可以從文中提及的幾個角度進行優化。
首先,在網絡設計上我們在backbone上可以選擇這幾年經典的輕量級網絡(如MobileNet系[25],[26],ShuffleNet系[27],[28],EfficientNet[29]等)。這些網絡一般在計算量上比重量級網絡有數量級上的減少,同時又可以保持準確率不損失太多。另一方面,對于多個檢測任務,由于輸入相同,我們一般會使用多分支的網絡結構。每個任務對應一個分支(head),它們共享同一個用于特征提取的backbone。按經驗來說,這個backbone占的計算一般會比較大,因此這樣可以節省下相當可觀的計算開銷。但是這樣的多任務多分支網絡會給訓練帶來困難。最理想的當然是有全標注的數據集,但這樣的數據集比較難獲得。對于這個問題,我們可以采取兩種方法:一種是如前面提的,靠重量級高準確率網絡自動標注。如訓練高準確率的物體檢測模型給已有車道線標注的數據集進行標注;另一種就是對帶特定標注的數據輸入,訓練對應的部分(backbone和相應的head)。
對于給定網絡結構,我們可以通過模型壓縮進一步減少計算量。因為普遍認為推理時不需要訓練時那樣復雜的模型和高的精度。模型壓縮有很多種方法,有量化、剪枝、知識蒸餾、低軼分解等等。常用的方法之一是量化。一般來說,將FP32轉為FP16是一種既比較安全收益又比較大的做法,然而在一些低端設備上我們還需要作更低精度(8位或以下)的量化。這時就得花更多精力在準確率損失上了。量化又分為post-training quantization和quantization-aware training。前者使用方便,不需要訓練環境,最多需要少量(幾百張)數據集作為量化參數calibration之用,但缺點是會對準確率損失較大;而后者,需要在訓練時插入特殊的算子用于得到量化所用參數及模擬量化行為。另一種常用的壓縮方法是網絡剪枝。根據網絡模型的敏感度分析,一些層稍作裁剪可能就會有大的準確率損失,而另一些層進行裁剪則準確率損失不大,甚至還會使準確率上升。這就給了我們簡化模型從而減少計算量的機會。低軼分解本質上是通過對矩陣的近似來減少矩陣運算的計算量。知識蒸餾是一種很有意思的方法,就像現實中的老師教學生,通過teacher model來幫助訓練student model。
網絡模型敲定后,就需要考慮性能優化。深度的優化是離不開硬件的考慮的。對于一些用于自動駕駛的計算平臺,可能直接就上像Nvidia的PX2這樣的高性能硬件平臺了。但對于普通車規硬件平臺,肯定是扛不住這種成本的。這些常規車機平臺中一些稍高端的會有幾百GFLOPS的GPU處理能力,或其它DSP,NPU等計算硬件。這里我們一般會首選這些硬件做模型推理而非CPU。因為如果將這些計算密集型任務往CPU放,會和系統中其它任務頻繁搶占資源導致不穩定的體驗。而對于低端一些的平臺GPU基本只夠渲染,那只能放到CPU上跑,一般會用上面提到的量化方法將模型轉為8位整型,然后將推理綁定到固定的核上以防止影響其它任務。推理引擎有兩類選擇。對于一些有成熟推理引擎的硬件平臺,使用廠商的引擎(如Intel有OpenVINO,高通有SNPE)通常是一個方便快捷的選擇;還有一種方法就是用基于編譯器的推理引擎,典型的如TVM。它以offline的方式將網絡模型編譯成可執行文件并可進行自動的執行參數優化。至于哪個性能好,通常是case-by-case,需要嘗試。值得注意的是,上面選取的輕量型網絡一般是memory-bound的,因此優化時需要著力優化訪存。
如果平臺上有多種可以執行神經網絡算子的硬件,如CPU、GPU、NPU、DSP,那可以考慮通過異構調度來提高硬件利用率,從而達到性能的優化。現在業界已有不少的異構計算框架,如ONNXRuntime,Android NN runtime等。這里面,最關鍵核心的問題在于調度。對于單個網絡模型而言,先要對網絡進行切分,然后分配到最合適的硬件上,然后在每個硬件上進行本地調度。難點在于這個調度是NP-hard的,意味著對于實際中大規模問題,不可能在合理時間找到最優解,而要找到盡可能優的近似解是門大學問。業界出現了大量的方法,如精確算法、基于啟發式策略、元啟發式搜索和機器學習的方法。對于前視感知任務中的多分支模型,一個最簡單而有效的做法就是將backbone以及各個head的分支作為子圖進行切分和調度。如果要得到更優的調度,則可以進一步嘗試基于搜索和學習的方式。
4.小結
前視感知領域是一個小打小鬧容易但做好非常難的東西。它需要長期的沉淀才能構建起核心競爭力和技術壁壘。我們看到今天行業龍頭Mobileye獨領風騷,但少有人看到它在早期的執著。Mobileye創立于1999年,但到2007年才開始盈利。類似的還有谷歌的無人駕駛車(差不多10年了),波士頓動力的機器人(貌似27年了),還有許許多多這樣“耐得住寂寞”的公司。即使最后失敗,相信也會滋養出更大的輝煌。而一旦成功,便能奠定絕對的市場地位,讓其它競爭者難望其項背。
可以看到,學術界的成果和產品之間還有不小的鴻溝。當然其中的因素有很多,如成本、功耗等等,而其中最關鍵的因素之一是性能。傳統的方式很多時候會算法管算法,整好后拿去優化,相互獨立,最多整幾輪迭代。而今天我們看到,兩者需要越來越多地相互融合,共同演進。通過hardware-software co-design才能打造和打磨出更加完美的產品。它需要算法設計中便考慮對于特定平臺硬件上的友好性。舉例來說,為了更好的部署,網絡設計時最好就要考慮哪些算子在目標平臺上能被較好地加速;同時訓練時加入特定的元素以便于后面的模型剪枝和量化。如果等吭哧吭哧訓練了幾周,模型都出來了再考慮這些問題就可能會帶來巨大的成本。近幾年大熱的AutoML中的自動神經網絡架構搜索(NAS)現在也越來越多地朝著hardware/platform-ware的方向發展。
最后,車輛環境感知中,數據的長尾問題是擺在AD/ADAS面前最大的問題。車輛環境是個開放環境,路上可能碰到任何無法預想的東西。2016年蘭德智庫指出自動駕駛系統需要進行110億英里的測試才能達到量產應用條件。顯然,這不是幾輛車上路滿大街跑能搞得定的,傳統的測試手段已捉襟見肘。當然,對于ADAS這類駕駛輔助類功能要求會低一些,但本質上面臨的問題是類似的。傳統的汽車功能安全標準已經無法涵蓋這類問題。雖然現在有針對性的預期功能安全(SOTIF)標準正在起草,但其可操作性和有效性還有待驗證。總得來說,汽車的智能化給測試驗證提出了非常有趣同時也是前所末有的挑戰。
參考資料
[1]B.Huval et al.,“An Empirical Evaluation of Deep Learning on Highway Driving,”CoRR,vol.abs/1504.01716,2015.
[2]C.Szegedy,A.Toshev,and D.Erhan,“Deep Neural Networks for Object Detection,”in Advances in Neural Information Processing Systems 26,2013,pp.2553–2561.
[3]E.Shelhamer,J.Long,and T.Darrell,“Fully Convolutional Networks for Semantic Segmentation,”CoRR,vol.abs/1605.06211,2016.
[4]V.Badrinarayanan,A.Handa,and R.Cipolla,“SegNet:A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling,”CoRR,vol.abs/1505.07293,2015.
[5]L.-C.Chen,G.Papandreou,I.Kokkinos,K.Murphy,and A.L.Yuille,“DeepLab:Semantic Image Segmentation with Deep Convolutional Nets,Atrous Convolution,and Fully Connected CRFs,”CoRR,vol.abs/1606.00915,2016.
[6]E.Romera,L.M.Bergasa,and R.Arroyo,“Can we unify monocular detectors for autonomous driving by using the pixel-wise semantic segmentation of CNNs?,”CoRR,vol.abs/1607.00971,2016.
[7]J.Kim and C.Park,“End-To-End Ego Lane Estimation Based on Sequential Transfer Learning for Self-Driving Cars,”in 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops(CVPRW),2017,pp.1194–1202.
[8]X.Pan,J.Shi,P.Luo,X.Wang,and X.Tang,“Spatial As Deep:Spatial CNN for Traffic Scene Understanding,”ArXiv E-Prints,Dec.2017.
[9]Y.-C.Hsu,Z.Xu,Z.Kira,and J.Huang,“Learning to Cluster for Proposal-Free Instance Segmentation,”CoRR,vol.abs/1803.06459,2018.
[10]S.Lee et al.,“VPGNet:Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition,”CoRR,vol.abs/1710.06288,2017.
[11]D.Neven,B.De Brabandere,S.Georgoulis,M.Proesmans,and L.Van Gool,“Towards End-to-End Lane Detection:an Instance Segmentation Approach,”ArXiv E-Prints,Feb.2018.
[12]B.D.Brabandere,W.V.Gansbeke,D.Neven,M.Proesmans,and L.V.Gool,“End-to-end Lane Detection through Differentiable Least-Squares Fitting,”CoRR,vol.abs/1902.00293,2019.
[13]N.Garnett,R.Cohen,T.Pe’er,R.Lahav,and D.Levi,“3D-LaneNet:end-to-end 3D multiple lane detection,”CoRR,vol.abs/1811.10203,2018.
[14]Z.Wang,W.Ren,and Q.Qiu,“LaneNet:Real-Time Lane Detection Networks for Autonomous Driving”CoRR,vol.abs/1807.01726,2018
[15]M.Ghafoorian,C.Nugteren,N.Baka,O.Booij,and M.Hofmann,“EL-GAN:Embedding Loss Driven Generative Adversarial Networks for Lane Detection”,CoRR,vol.abs/1806.05525,2018
[16]Y.Hou,Z.Ma,C.Liu,and C.Change Loy,“Learning Lightweight Lane Detection CNNs by Self Attention Distillation,”ArXiv E-Prints,p.arXiv:1908.00821,Aug.2019.
[17]Q.Zou,H.Jiang,Q.Dai,Y.Yue,L.Chen,and Q.Wang,“Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks”,CoRR,vol.abs/1903.02193.2019
[18]Z.Zou,Z.Shi,Y.Guo,and J.Ye,“Object Detection in 20 Years:A Survey,”CoRR,vol.abs/1905.05055,2019.
[19]X.Wu,D.Sahoo,and S.C.H.Hoi,“Recent Advances in Deep Learning for Object Detection,”ArXiv E-Prints,p.arXiv:1908.03673,Aug.2019.
[20]Q.Zhao,T.Sheng,Y.Wang,F.Ni,and L.Cai,“CFENet:An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving,”ArXiv E-Prints,Jun.2018.
[21]A.Bewley,Z.Ge,L.Ott,F.Ramos,and B.Upcroft,“Simple Online and Realtime Tracking,”CoRR,vol.abs/1602.00763,2016.
[22]N.Wojke,A.Bewley,and D.Paulus,“Simple Online and Realtime Tracking with a Deep Association Metric,”CoRR,vol.abs/1703.07402,2017.
[23]X.Pan,P.Luo,J.Shi,and X.Tang,“Two at Once:Enhancing Learning and Generalization Capacities via IBN-Net,”in The European Conference on Computer Vision(ECCV),2018.
[24]H.Zhao et al.,“PSANet:Point-wise Spatial Attention Network for Scene Parsing,”in Computer Vision–ECCV 2018,Cham,2018,pp.270–286.
[25]A.G.Howard et al.,“MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications,”ArXiv E-Prints,Apr.2017.
[26]M.Sandler,A.Howard,M.Zhu,A.Zhmoginov,and L.-C.Chen,“Inverted Residuals and Linear Bottlenecks:Mobile Networks for Classification,Detection and Segmentation,”ArXiv E-Prints,Jan.2018.
[27]X.Zhang,X.Zhou,M.Lin,and J.Sun,“ShuffleNet:An Extremely Efficient Convolutional Neural Network for Mobile Devices,”ArXiv E-Prints,Jul.2017.
[28]N.Ma,X.Zhang,H.-T.Zheng,and J.Sun,“ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design,”ArXiv E-Prints,2018.
[29]M.Tan and Q.V.Le,“EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks,”ArXiv E-Prints,p.arXiv:1905.11946
————————————————
版權聲明:本文為CSDN博主「ariesjzj」的原創文章,遵循CC 4.0 BY-SA版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/jinzhuojun/article/details/105316083



評論