GPU如何訓練大批量模型?方法在這里

深度學習模型和數(shù)據(jù)集的規(guī)模增長速度已經(jīng)讓 GPU 算力也開始捉襟見肘,如果你的 GPU 連一個樣本都容不下,你要如何訓練大批量模型?通過本文介紹的方法,我們可以在訓練批量甚至單個訓練樣本大于 GPU 內(nèi)存時,在單個或多個 GPU 服務器上訓練模型。
本文引用地址:http://www.104case.com/article/201810/393173.htm分布式計算
2018 年的大部分時間我都在試圖訓練神經(jīng)網(wǎng)絡時克服 GPU 極限。無論是在含有 1.5 億個參數(shù)的語言模型(如 OpenAI 的大型生成預訓練 Transformer 或最近類似的 BERT 模型)還是饋入 3000 萬個元素輸入的元學習神經(jīng)網(wǎng)絡(如我們在一篇 ICLR 論文《Meta-Learning a Dynamical Language Model》中提到的模型),我都只能在 GPU 上處理很少的訓練樣本。
但在多數(shù)情況下,隨機梯度下降算法需要很大批量才能得出不錯的結(jié)果。
如果你的 GPU 只能處理很少的樣本,你要如何訓練大批量模型?
有幾個工具、技巧可以幫助你解決上述問題。在本文中,我將自己用過、學過的東西整理出來供大家參考。
在這篇文章中,我將主要討論 PyTorch 框架。有部分工具尚未包括在 PyTorch(1.0 版本)中,因此我也寫了自定義代碼。
我們將著重探討以下問題:
在訓練批量甚至單個訓練樣本大于 GPU 內(nèi)存,要如何在單個或多個 GPU 服務器上訓練模型;
如何盡可能高效地利用多 GPU 機器;
在分布式設備上使用多個機器的最簡單訓練方法。
在一個或多個 GPU 上訓練大批量模型
你建的模型不錯,在這個簡潔的任務中可能成為新的 SOTA,但每次嘗試在一個批量處理更多樣本時,你都會得到一個 CUDA RuntimeError:內(nèi)存不足。
這位網(wǎng)友指出了你的問題!
但你很確定將批量加倍可以優(yōu)化結(jié)果。
你要怎么做呢?
這個問題有一個簡單的解決方法:梯度累積。
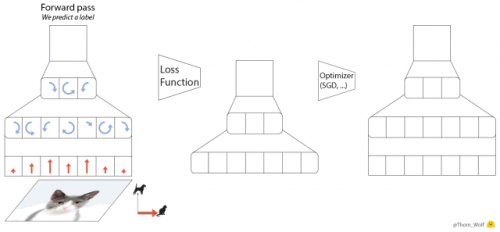
梯度下降優(yōu)化算法的五個步驟。
與之對等的 PyTorch 代碼也可以寫成以下五行:
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
predictions = model(inputs) # Forward pass with new parameters
在 loss.backward() 運算期間,為每個參數(shù)計算梯度,并將其存儲在與每個參數(shù)相關聯(lián)的張量——parameter.grad 中。
累積梯度意味著,在調(diào)用 optimizer.step() 實施一步梯度下降之前,我們會對 parameter.grad 張量中的幾個反向運算的梯度求和。在 PyTorch 中這一點很容易實現(xiàn),因為梯度張量在不調(diào)用 model.zero_grad() 或 optimizer.zero_grad() 的情況下不會重置。如果損失在訓練樣本上要取平均,我們還需要除以累積步驟的數(shù)量。
以下是使用梯度累積訓練模型的要點。在這個例子中,我們可以用一個大于 GPU 最大容量的 accumulation_steps 批量進行訓練:
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulated













評論