基于GPU的并行Voronoi圖柵格生成算法

Voronoi圖是一種空間分割算法。其是對空間中的n個離散點而言的,它將平面分割為n個區域,每個區域包括一個點,此區域是到該點距離最近的點的集合。由于Voronoi圖具有最鄰近性,鄰接性等眾多性質和完善的理論體系,其被廣泛的應用在地理學、氣象學、結晶學、航天、機器人等領域。
本文引用地址:http://www.104case.com/article/201808/385935.htmVoronoi圖的生成主要有矢量方法和柵格方法。矢量法中,典型的方法有增量法、分治法和間接法。分治法是一種遞歸方法,算法思路簡單,但是很難在應用過程中實現動態更新。間接法則是根據其對偶圖Delaunay三角網來構造Voronoi圖,因此其性能的高低由所采用的Delaunay三角網的構造算法所決定。增量法通過不斷向已生成的Voronoi圖中增加點來動態構建Voronoi圖。相對于前兩種方法,增量法構造簡單并且容易實現動態化,所以被廣泛應用。矢量方法的優勢是生成Voronoi圖精度高,但是存在存儲復雜,生長元只能是點和線,以及難以向三維及高維空間擴展等問題。因此本文重點研究了Voronoi圖的柵格生成方法,首先比較了常見的柵格方法生成Voronoi圖的優缺點,然后結合CUDA的出現,提出一種基于GPU的 Voronoi圖并行柵格生成算法。
1 柵格法簡介
柵格方法生成Voronoi 圖主要是將二值圖像轉化為柵格圖像,然后確定各個空白柵格歸屬。主要方法有兩類,一類以空白柵格為中心,計算每個空白柵格到生長目標的距離,以確定其歸屬,常見的方法有代數距離變換法,逐個空白柵格確定法等;另一類以生長目標為中心,不斷擴張生長目標的距離半徑,填充其中的空白柵格,直到將整個圖像填充完成,主要有圓擴張法,數學形態學距離變換法等。代數距離變換法對距離圖像進行上行掃描(從上到下,從左到右)和下行掃描(從下向上,從右到左)兩次掃描,計算出每個空白柵格最鄰近的生長目標,以此生長目標作為其歸屬。此方法中柵格距離的定義直接影響了空白柵格的歸屬和Voronoi圖的生成精度,通常使用的柵格距離定義有街區距離、八角形距離、棋盤距離等。距離變換的柵格生成方法精度低、耗時長,所需要花費的時間和柵格的數量成正比,當柵格為n×n大小時,其時間復雜度為O(n×n)。圓檢測法以生長目標為圓心,以一定的步長為初始半徑,所有生長目標同時對其構成的圓內的空白柵格進行覆蓋。通過不斷擴大生長目標的半徑,將會有越來越多的空白柵格被各個圓所覆蓋,直到最終覆蓋完整個圖像。數學形態學距離變換法與圓檢測法類似,其思想來源于數學形態學中膨脹操作,膨脹操作起到了擴大圖像的效果,通過不斷的對生長目標進行膨脹操作,最終擴張到所有的空白柵格。這兩種方法有個共同的缺點,在每次擴張后,都需要判斷整個柵格圖像是否已完成擴張,而這需要遍歷柵格圖像,十分耗時。
2 GPU下的柵格生成方法
2.1 CUDA編程模型與GPU
CUDA是一個并行編程模型和一個軟件編程環境,其采用了C語言作為編程語言,提供了大量的高性能計算指令開發能力,使開發者能夠在GPU的強大計算能力上建立起一種更加高效的密集數據計算解決方案。
CUDA將CPU作為主機端,GPU作為設備端,一個主機端可以有多個設備端。其采用CPU和GPU協同工作的方式,CPU主要負責程序中的串行計算的部分,GPU主要負責程序中的并行計算的部分。GPU上運行的代碼被稱為內核函數,其能夠被GPU上內置的多個線程并行執行。一個完整的任務處理程序由 CPU端串行處理代碼和GPU端并行內核函數共同構成。當CPU中執行到GPU代碼時,其首先將相關數據復制到GPU中,然后調用GPU的內核函數,GPU中多個線程并行執行此內核函數,當完成計算后,GPU端再把計算的結果返回給CPU,程序繼續執行。通過將程序中耗時的且便于并行處理的計算轉移到GPU中使用GPU并行處理,以提高整個程序的運行速度。CUDA是以線程網格(Grid),線程塊(Block),線程(Thread)為三層的組織架構,每一個網格由多個線程塊構成,而一個線程塊又由多個線程構成,如圖1所示。在GPU中,線程是并行運行的最小單元,由此可見,當存在大量的線程時,程序的并行程度將會十分高。目前的GPU上一個網格最多包含65535×65535個線程塊,而一個線程塊通常有512個或1024個線程,所以理論上可以對65535×65535×512個柵格同時進行計算。
傳統的柵格生成算法中,不論是采用以空白柵格為中心確定其歸屬的方法,還是以生長目標為中心通過不斷增長生長目標半徑對空白柵格進行覆蓋的方法,他們在計算每個空白柵格距離時,只能通過遍歷柵格,逐一處理。而柵格處理過程中的一個重要特點是,各個柵格的計算并不依賴于其他柵格的計算結果。即各個柵格的計算是相互獨立的,而由于CPU的串行性,導致了各個柵格只能順序處理,降低了處理速度。
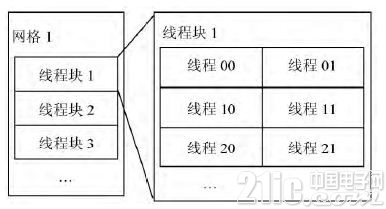
圖1GPU組織架構
由于GPU下的多個線程都是硬件實現的,各個線程的處理都是并行的,因此將柵格距離的計算分散到GPU端各個線程,必然能夠提高其生成速度。為了并行處理柵格化圖像,可以采用如下的想法,將每一個柵格點對應于一個線程,此線程計算此柵格到所有的生長目標的距離,取最小距離的生長目標作為其歸屬。即采用一個線程用來確定一個空白柵格歸屬的方法。
確定方法后,就需要對GPU端內核函數進行設計,由于內核函數是并行處理的執行單元,其設計方式直接決定了GPU端的程序運行效率。因此如何設計良好的內核函數是提高并行速度的關鍵。本文采用如下方式進行內核函數的設計,假設共分配了K個并行處理線程,柵格規模為M×N,設A[i]為第i個線程處理的柵格編號。當K
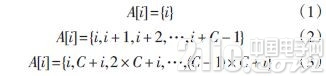
由于顯卡上的內存是動態隨機存儲(DRAM),因此最有效率的存取方式,是以連續的方式存取。當采用第一種方式時,看似是一種連續的存取方式,實際上恰好是非連續的,當第i個線程處理第i個柵格時,由于處理需要一定的時間,此時GPU自動將下個一線程i+1需要的內存數據取出給其使用,此時下一個線程的內存數據卻是在i+C處,內存變成了間斷存取。而在使用第二種方式進行處理時,恰好是一種連續的存取方式,由于第i個線程正在處理第i個柵格數據,此時 GPU為第i+1個線程準備數據,而此時的數據正好為第i+1內存處。滿足了內存的連續存取特性。因此本文采用第二種方式,內核函數的設計偽代碼如下:












評論