詳細解析眾核多計算模式系統的構建

2.2 計算模式構建與切換
本文引用地址:http://www.104case.com/article/201808/385126.htm計算模式構建是形態管理模塊根據接收到的命令動態構建出被指定的目的計算模式的過程。眾核處理系統在初始化時,就已經創建了指定數目的CUDA 流(CUDA流的最大數目取決于GPU中硬件工作隊列的數目),并采用空位標記法對創建的CUDA流進行管理,通過標記位的有效性描述CUDA 流的可用性。當目的計算模式為單任務計算時,只需將首位的CUDA流標記設置為有效,其他全部標記為無效,在對計算任務加載時,將計算任務放入該CUDA流中進行計算;當目的計算模式為多任務計算時,需要將指定數目CUDA流的標記位設置為有效,在對計算任務加載時,通過輪詢的方式將計算任務放入到相應的CUDA 流中,利用CUDA 流的Hyper-Q特性,同時加載多個計算任務到眾核計算單元;當目的計算模式為多任務流式計算時,需要將指定CUDA 流的標記設置為有效,從構建第一個計算步開始,將第一個計算步放入第一個CUDA 流中進行計算,當第一個計算步首次完成計算后,利用二元信號量通知眾核控制單元中的任務管理模塊開始構建第二個計算步,并重新構建第一個計算步,以此類推,完成對多任務流式計算中每個計算步的動態構建過程。
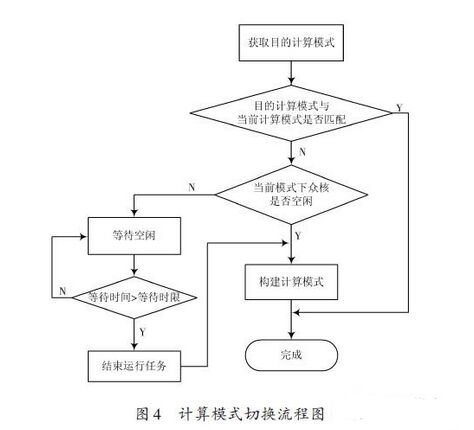
計算模式的切換是當眾核計算單元的當前計算模式與計算任務執行需要的計算模式(即目的計算模式)不匹配時,需要對眾核計算單元的計算模式進行切換,以適應計算模式變化的需求。
在從任務配置文件中獲取適應于計算任務執行的目的計算模式后,首先與當前計算模式進行比較,若匹配成功則不需要進行計算模式的切換;若匹配失敗則進一步判斷眾核在當前計算模式下是否空閑,如處于忙碌狀態則需要等待,對于不同優先級的任務設有不同的等待時限,以保證對計算任務的及時響應,當大于這一時限時強制結束正在運行的任務以釋放計算資源,從而構建新的計算模式,完成計算模的切換過程,流程圖如圖4 所示。
2.3 共享內存緩沖技術
眾核計算單元在對主控機請求的計算任務加載前,必須獲取來自主控機的任務數據,為了實現對任務數據的接收和發送,需要建立相應的數據緩沖區。傳統的方法是采用消息隊列和基于共享內存信號燈的方式來建立和管理數據緩沖區,但當數據的寫入和讀取速度差別較大時,容易造成數據緩沖區的阻塞。因此采用一種可滑動動態共享內存緩沖技術,如圖5所示。
在眾核控制單元的存儲空間中申請存儲空間作為存放數據的緩沖池,按需要建立指定數量的單向指針鏈表,每個指針鏈表代表一個數據緩沖區,在眾核處理系統的計算模式切換時,可根據并行任務數目的變化修改指針鏈表的節點數,使每個數據緩沖區占用的存儲空間按需滑動,以提高整個數據緩池數據的傳遞效率。
2.4 計算庫動態加載
在對計算任務的執行函數進行加載時,采用動態共享庫的方式,因為動態鏈接的共享庫具有動態加載、封裝實現、節省內存等優點,可以把眾核計算單元的執行函數與邏輯控制程序相隔離,降低了眾核計算與邏輯控制的耦合度,增加了可擴展性和靈活性。
在動態加載計算庫前,需要將執行函數編譯生成動態共享庫,進而在程序中進行顯示調用。當調用時使用動態加載API,該過程首先調用dlopen以打開指定名字的動態共享庫,并獲得共享對象的句柄;而后通過調用dlsym,根據動態共享庫操作句柄與符號獲取該符號對應的函數的執行代碼地址;在取得執行代碼地址后,就可以根據共享庫提供的接口調用與計算任務對應的執行函數,將執行函數發射到眾核計算單元,由眾核計算單元根據執行函數的配置參數組織計算資源進行計算;當不會再調用共享對象時調用dlclose關閉指定句柄的動態共享庫。
3 結語
針對復雜應用領域計算任務對多種計算模式的需求,本文研究了眾核處理機結構,根據NVIDIA KeplerGK110架構中Hyper-Q 與CUDA 流的特性,構建了可單任務并行計算、多任務并行計算、多任務流式計算間動態切換的眾核多計算模式系統,能夠提高實時計算平臺的靈活性,以適應不同的任務計算需求。下一步的研究方向是挖掘GPU中硬件工作鏈路與SM(Streaming Mul-tiprocessor)間的映射機制。




評論