這7 個深度學習實用技巧,你掌握了嗎?

▌ 兩全其美的辦法
本文引用地址:http://www.104case.com/article/201802/375972.htm最近已經證明,可以得到兩全其美的結果:從 Adam 到SGD的高性能高速訓練! 這個想法是,實際上由于在訓練的早期階段SGD對參數調整和初始化非常敏感。 因此,我們可以通過使用Adam來開始訓練,這將節省相當長的時間,而不必擔心初始化和參數調整。 那么,一旦Adam獲得較好的參數,我們可以切換到SGD +動量優化,以達到最佳性能!
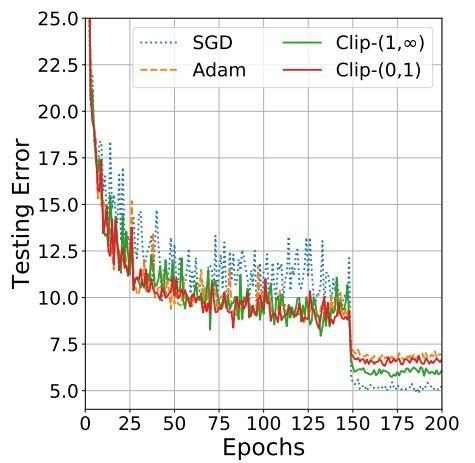
Adam vs SGD 性能
▌ 3-如何處理不平衡數據
在很多情況下,都要處理不平衡的數據,特別是實際應用程序中。 一個簡單而實際的例子如下:訓練您的深度網絡以預測視頻流中是否有人持有致命武器。 但是在你的訓練數據中,你只有50個拿著武器的人的視頻和1000個沒有武器的人的視頻! 如果你只是用這些數據來訓練你的網絡,那么你的模型肯定會非常偏向于預測沒有人有武器!
你可以做用以下的方法來解決它:
在損失函數中使用類權重。 本質上就是,讓實例不足的類在損失函數中獲得較高的權重,因此任何對該類的錯分都將導致損失函數中非常高的錯誤。
過度采樣:重復一些實例較少的訓練樣例,有助于平衡分配。 如果可用的數據很小,這個方法最好。
欠采樣:一些類的訓練實例過多,可以簡單地跳過一些實例。 如果可用數據非常大,這個方法最好。
為少數類增加數據。可以為少數類創建更多的訓練實例! 例如,在前面檢測致命武器的例子中,你可以改變屬于具有致命武器的類別的視頻的顏色和光照等。
▌ 4-遷移學習
正如我們所看到的,深層網絡需要大量的數據。遺憾的是,對于許多新的應用程序來說,這些數據可能很難得到并且開銷很大。 如果我們希望模型表現良好,可能需要數萬或數十萬個新的訓練樣例來進行訓練。 如果數據集不易獲取,則必須全部手動收集并標記。
這就是遷移學習的起點。 通過遷移學習,我們不需要太多的數據! 這個想法是從一個在數百萬圖像上訓練過的網絡開始的,比如在ImageNet上預訓練的ResNet。 然后,我們將“重新調整ResNet模型,只重新訓練最后幾層。
我們將ResNet從數百萬圖像中學到的信息(圖像特征)進行微調,以便將其應用于不同的任務。 因為跨域的圖像的特征信息經常是非常相似的所以這個方法是可行的,但是這些特征的分析根據應用而不同。
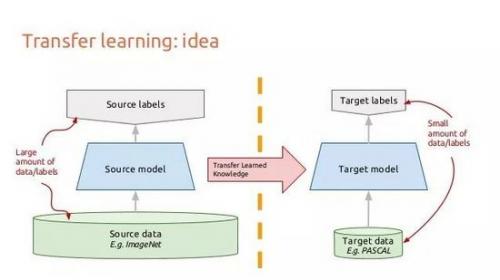
一個基本的遷移學習示例
▌ 5 – 用數據增強提高性能
前面已經說過:更多的數據=更好的表現。 除了遷移學習之外,另一種快速而簡單提高模型的性能的方法是數據增強。 數據增強是使用原始類別標簽的同時,改變數據集的原始圖像以合成一些新的訓練示例。例如,用于圖像數據增強的常見方式包括:
水平和/或垂直旋轉翻轉圖像
改變圖像的亮度和顏色
隨機模糊圖像
隨機從圖像裁剪塊
基本上,你可以進行任何改變,改變圖像的外觀但不改變整體內容,例如你可以使用藍色狗的照片,但你仍然應該能夠清楚地看到,這是一個狗的照片。

數據增強
▌ 6-通過集成提升模型!
在機器學習中,集成訓練多個模型,然后將它們組合在一起以獲得更高的性能。 這個想法是在相同的數據集上對同一任務訓練多個深度網絡模型。 然后,模型的結果可以通過投票進行組合,即具有最高票數的類勝出。
為了確保所有模型不同,可以使用隨機權重初始化和隨機數據增強。眾所周知,由于使用了多個模型,因此集成通常比單個模型更精確,從而從不同角度完成任務。在實際應用中,尤其是競賽中,幾乎所有頂級模型都使用集合方式。
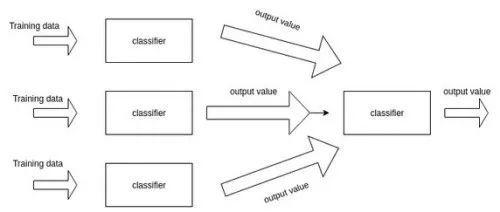
集成模型
▌ 7-加快剪枝
我們知道模型精度隨深度而增加,但速度又如何呢? 更多的層意味著更多的參數,更多的參數意味著更多的計算,更多的內存消耗和更慢的速度。理想情況下,我們希望在提高速度的同時保持高精度。我們可以通過剪枝來做到這一點。
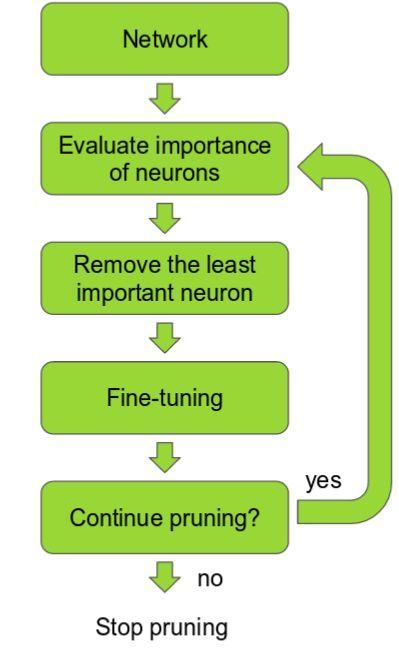
深度神經網絡剪枝策略
這個想法是,網絡中的許多參數是多余的,對輸出沒有太大貢獻。 如果可以根據貢獻值對網絡中的神經元進行排名,那么就可以從網絡中移除低排名的神經元,從而形成更小更快的網絡。 可以根據神經元權重的L1 / L2均值(平均激活)、一些驗證集上神經元不為零的次數以及其他方法來進行排序。 獲得更快/更小的網絡對于在移動設備上運行深度學習網絡非常重要。
修剪網絡的最基本的方法是簡單地放棄某些卷積濾波器。 最近文章表明,這樣做是相當成功的。 這項工作中的神經元排名相當簡單:每個濾波器的權重按照L1規范排名。 在每個修剪迭代中,對所有的過濾器進行排序,在所有層中修剪m個排名最低的過濾器,重新訓練和重復!
最近的另一篇分析殘差網絡結構的論文中提出了修剪“過濾器”的關鍵特點。 作者指出,在刪除層的時候,具有殘差快捷連接(例如ResNets)的網絡比不使用任何快捷連接(例如VGG或AlexNet)的網絡在保持良好的準確性方面更為穩健。這個有趣的發現具有重大的實際意義,因為它告訴我們,在修剪網絡進行部署和應用時,網絡設計至關重要(例如ResNets)。 所以使用最新最好的方法總是很好的!





評論