這7 個深度學習實用技巧,你掌握了嗎?

前幾天,深度學習工程師George Seif發表了一篇博文,總結了7個深度學習的技巧,主要從提高深度學習模型的準確性和速度兩個角度來分析這些小技巧。在使用深度學習的時候,我們不能僅僅把它看成一個黑盒子,因為網絡設計、訓練過程、數據處理等很多步驟都需要精心的設計。作者分別介紹了7個非常實用小技巧:數據量、優化器選擇、處理不平衡數據、遷移學習、數據增強、多個模型集成、加快剪枝。相信掌握了這7個技巧,能讓你在實際工作中事半功倍!
本文引用地址:http://www.104case.com/article/201802/375972.htm

7 Practical Deep Learni ng Tips
7個實用的深度學習技巧
深度學習已經成為解決許多具有挑戰性問題的方法。 在目標檢測,語音識別和語言翻譯方面,深度學習是迄今為止表現最好的方法。 許多人將深度神經網絡(DNNs)視為神奇的黑盒子,我們輸入一些數據,出來的就是我們的解決方案! 事實上,事情要復雜得多。
在設計和應用中,把DNN用到一個特定的問題上可能會遇到很多挑戰。 為了達到實際應用所需的性能標準,數據處理、網絡設計、訓練和推斷等各個階段的正確設計和執行至關重要。 在這里,我將與大家分享7個實用技巧,讓你的深度神經網絡發揮最大作用。

▌ 1-數據,數據,數據
這不是什么大秘密,深度學習機需要大量的“燃料”, 那“燃料”就是數據。擁有的標簽數據越多,模型的表現就越好。 更多數據產生能更好性能的想法,已經由谷歌的大規模數據集(有3億圖像)證明!為了感受數據帶給深度學習模型的性能提升,在部署Deep Learning模型時,你應該不斷地為其提供更多的數據和微調以繼續提高其性能。 Feed the beast:如果你想提高你的模型的性能,就要提供更多的數據!
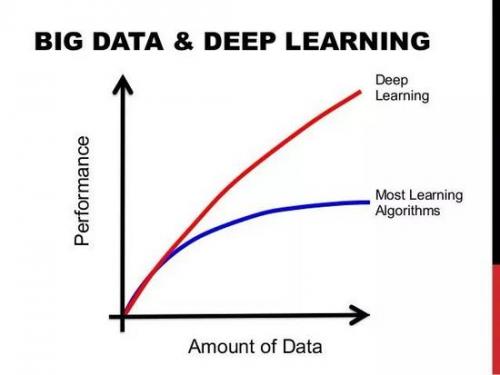
圖顯示數據量的增加會得到更好的性能
▌ 2-你應該選擇哪一個優化器
多年來,已經開發了許多梯度下降優化算法,他們各有其優缺點。 一些最流行的方法如下:
Stochastic Gradient Descent (SGD) with momentum
Adam
RMSprop
Adadelta
RMSprop,Adadelta和Adam被認為是自適應優化算法,因為它們會自動更新學習率。 使用SGD時,您必須手動選擇學習率和動量參數,通常會隨著時間的推移而降低學習率。
在實踐中,自適應優化器傾向于比SGD更快地收斂, 然而,他們的最終表現通常稍差。 SGD通常會達到更好的minimum,從而獲得更好的最終準確性。但這可能需要比某些優化程序長得多的時間。 它的性能也更依賴于強大的初始化和學習率衰減時間表,這在實踐中可能非常困難。
因此,如果你需要一個優化器來快速得到結果,或者測試一個新的技術。 我發現Adam
很實用,因為它對學習率并不是很敏感。 如果您想要獲得絕對最佳的表現,請使用SGD + Momentum,并調整學習率,衰減和動量值來使性能最優化。





評論