一種基于支持向量機的車型自動分類器設(shè)計方案

車型自動分類一直是智能交通領(lǐng)域中的一個熱點問題。自動識別車輛類型對實現(xiàn)交通管理智能化具有重要意義。目前已經(jīng)廣泛應(yīng)用的分類方法是采用地感線圈根據(jù)不同類型車輛通過線圈產(chǎn)生的電磁感應(yīng)曲線不同這一原理進行分類。這種方法分類速度較低,誤差較大,因此難以滿足不停車收費系統(tǒng)的要求。
隨著計算機硬件性能的不斷提高,基于圖像處理的車輛分類方法逐漸得到重視,計算機對攝像機捕捉到的車輛圖像進行處理得到車輛的外形信息,這些信息可以作為車型識別依據(jù)進行車輛分類。已經(jīng)采用的數(shù)據(jù)分析方法有模式匹配和BP神經(jīng)網(wǎng)絡(luò)兩種。前者是將得到的外形信息與系統(tǒng)中的車型模式庫進行比對,輸出匹配度最大的模式類型作為車輛類型[1];后者是將車輛信息輸入到已訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)分類器進行分類[2]。基于模式匹配的分類方法實現(xiàn)原理簡單,但是選擇合適的模式比較困難;采用BP神經(jīng)網(wǎng)絡(luò)的分類方法中,由于BP神經(jīng)網(wǎng)絡(luò)本身存在網(wǎng)絡(luò)結(jié)構(gòu)無規(guī)律可循、作用機理不明確并易陷入局部極小值等缺陷從而限制了這種方法的應(yīng)用。
支持向量機是二十世紀90年代提出的一種新的學(xué)習(xí)機[3],具有較好的推廣能力和非線性處理能力。本文給出一種基于支持向量機的車型分類器的設(shè)計方案。
1 支持向量機識別理論
設(shè)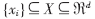 為輸入空間的某類別數(shù)據(jù)集,對于非線性可分情況而言,類別的邊界比較復(fù)雜。引入從輸入空間X到高維空間Y(特征空間)的非線性變換Φ將會簡化類別邊界。Φ可以把X中具有復(fù)雜幾何形狀的類邊界(覆蓋該類別全部數(shù)據(jù)集)映射為Y中的規(guī)則球(覆蓋變換后的相應(yīng)類別全部數(shù)據(jù)集)。如果希望輸入空間X中類的邊界緊致包圍本類數(shù)據(jù)集,就要在變換后空間Y中尋找最小的閉合球。Y中的閉合球表述為:
為輸入空間的某類別數(shù)據(jù)集,對于非線性可分情況而言,類別的邊界比較復(fù)雜。引入從輸入空間X到高維空間Y(特征空間)的非線性變換Φ將會簡化類別邊界。Φ可以把X中具有復(fù)雜幾何形狀的類邊界(覆蓋該類別全部數(shù)據(jù)集)映射為Y中的規(guī)則球(覆蓋變換后的相應(yīng)類別全部數(shù)據(jù)集)。如果希望輸入空間X中類的邊界緊致包圍本類數(shù)據(jù)集,就要在變換后空間Y中尋找最小的閉合球。Y中的閉合球表述為:
其中∣∣●∣∣為歐式范數(shù),a為球心。目標就是通過搜索所有滿足約束條件的a來最小化R2。
構(gòu)造Lagrange函數(shù)如下: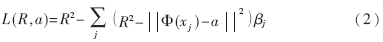
這里βj≥0,是Lagrange乘子。達到極小值的必要條件為: 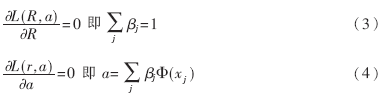
把式(3)和式(4)代入式(2)消去r和a,就轉(zhuǎn)化為它的Wolfe對偶問題:求式(5)中W關(guān)于變量βj的極大值。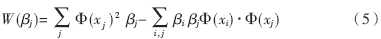
在W達到極大值時,對于球內(nèi)的數(shù)據(jù)和部分球上數(shù)據(jù),βj=0;對于位于球邊界的數(shù)據(jù),βj>0。滿足βj>0的數(shù)據(jù)就是支持向量,它們定義了球的中心,如式(4)。
可以采用合適的Mercer核函數(shù)替代內(nèi)積Φ(xi)·Φ(xj),
目前主要的核函數(shù)有兩種:
階次為d的多項式核函數(shù)
其中C>0為常數(shù)。位于球內(nèi)(包括球上)的數(shù)據(jù)點,有ζj=0和βj<C;對于孤立數(shù)據(jù)點βj=C。
定義輸入數(shù)據(jù)點x映射到特征空間內(nèi)時到球心距離為:
如果R(x)>R,那么x為孤立點或其它類點。
2系統(tǒng)實現(xiàn)
2.1圖像采集和特征提取
利用兩部CCD攝像機和圖像采集卡獲得同一車輛的兩幅圖像,基于雙目視覺原理對兩幅圖像進行特征匹配,得到車輛的三維模型。根據(jù)攝像機標定矩陣和成像幾何模型可以計算出車輛的三維數(shù)據(jù):車長、車寬和車高。采集每一類別車輛圖像若干,得到該類車輛訓(xùn)練樣本作為車型分類器訓(xùn)練依據(jù)。
2.2 訓(xùn)練數(shù)據(jù)預(yù)處理
采用有導(dǎo)師訓(xùn)練的方法進行分類器訓(xùn)練,首先要確定訓(xùn)練樣本所屬類別。本文將車輛分為大型、中型和小型三類。按照前述方法獲取100個車輛三維數(shù)據(jù)對,采用動態(tài)聚類方法K-Means對100個數(shù)據(jù)樣本進行自動聚類[5],設(shè)定聚類類別數(shù)為3。從聚類結(jié)果選擇各類訓(xùn)練樣本(每類10個),其余數(shù)據(jù)作為測試樣本,訓(xùn)練樣本見表1。
2.3 分類器設(shè)計
支持向量機一般用于二類模式識別,對于多類問題識別能力不足。為了使二類分類器能用于多類模式,本文為每類車輛分別設(shè)計識別器,然后通過表決器進行決策,如圖1。
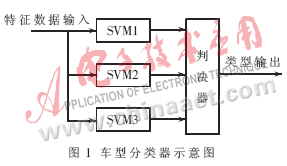
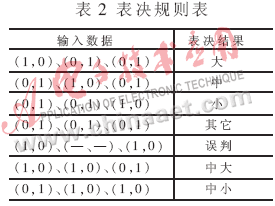
其中,SVM1、SVM2和SVM3分別為大、中和小型車的識別器,輸出結(jié)果分別為(大,非大)、(中,非中)和(小,非小)三個數(shù)對。表決器以三個識別器的輸出組成的向量作為輸入進行綜合判斷,輸出車輛類型。表決器的表決表見表2。
對于每個SVM識別器,遵循了相同的設(shè)計原則:首先采用有導(dǎo)師訓(xùn)練的方法進行訓(xùn)練,選擇合適的參數(shù)q和C;然后使用測試樣本測試識別率。
本文以小型車識別器SVM3為例說明SVM識別器的訓(xùn)練過程。
(1)標號:把屬于小型車的訓(xùn)練樣本標記為類別1,其余訓(xùn)練樣本均標記為類別0;
(2)訓(xùn)練:選擇參數(shù)q和C進行循環(huán),計算目標誤差;
(3)結(jié)束:當目標誤差小于0.001時結(jié)束循環(huán);
(4)調(diào)整:根據(jù)訓(xùn)練結(jié)果,調(diào)整參數(shù)q和C;
(5)重復(fù)步驟(2),直到得到滿意的訓(xùn)練結(jié)果為止。
通過反復(fù)試驗發(fā)現(xiàn),參數(shù)q影響識別器分類邊界的復(fù)雜性,q越大分類邊界越復(fù)雜,即支持向量個數(shù)越多;參數(shù)C的取值變化改變識別器對本類樣本數(shù)據(jù)異常的容忍度,C越小容忍本類異常數(shù)據(jù)的能力越差。當20≤q≤70時,識別器識別類1所用的支持向量數(shù)為3且保持不變,因此令q為45(C=1)。支持向量分別為(0.33 0.1405 0.141)、(0.33 0.1405 0.144)和(0.488 0.18 0.145)類似地,選取中型車識別器q為60(C=1),識別中型車所用支持向量個數(shù)為5,分別為(0.708 0.2035 0.263)、(0.589 0.2495 0.295)、(0.6071 0.25 0.2978)、(0.7696 0.25 0.3114)和(0.8614 0.249 0.281); 選取大型車識別器的q為30(C=1),識別中型車所用支持向量個數(shù)為4,分別為(0.975 0.2498 0.2704)、(0.894 0.23 0.332)、(1.198 0.248 0.3075)和(1.198 0.25 0.3647)。
2.4性能測試與結(jié)果分析
采用測試樣本對三個識別器分別進行測試。測試樣本由三種類型車輛數(shù)據(jù)組成,每類30個數(shù)據(jù)。測試分為識別器獨立測試和分類器聯(lián)合測試兩部分。在識別器獨立測試中,要考察每個識別器對本類數(shù)據(jù)的識別正確率和對其他類數(shù)據(jù)的識別正確率,獨立測試結(jié)果見表3;進行聯(lián)合測試即對3個分類器與表決器整體進行車型分類測試,測試依據(jù)為表2。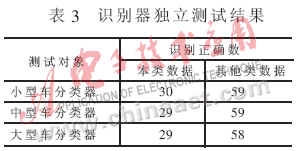
對表3中的測試結(jié)果進行分析,發(fā)現(xiàn)小型車識別正確率相當高,為98.89%;而中型車識別器和大型車識別器識別正確率分別為97.78%和96.67%。而且后兩者對本類數(shù)據(jù)和其他數(shù)據(jù)均有錯判現(xiàn)象發(fā)生。
由于本文設(shè)計的分類器采用了圖1所示結(jié)構(gòu)以及特殊的表決表(表2),具有較強的容錯能力,發(fā)生在小型車、中型車和大型車相鄰類型之間的錯判不會影響表決器的表決工作。只有當小型車識別器和大型車識別器均判為本類車時,表決器才輸出“誤判”。在聯(lián)合測試時,分類器對90個測試樣本的表決結(jié)果全部正確。
本文采用基于支持向量機的識別理論設(shè)計了一種可應(yīng)用于不停車收費系統(tǒng)的車型自動分類器。該分類器與RFID(射頻識別)技術(shù)相結(jié)合,能大幅度提升道路通行能力,有效打擊各種作弊行為。


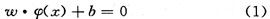




評論