Nature重磅:Hinton、LeCun、Bengio三巨頭權威科普深度學習

將遞歸神經網絡(RNN)生成的標題作為額外輸入,深度卷積神經網絡(CNN)會從測試圖片中提取表征,再利用訓練好的RNN將圖像中高級( high-level )表征「翻譯成 」標題(上圖)。當RNN一邊生成單詞(黑體所示),一邊能將注意力集中在輸入圖像的不同位置(中間和底部;塊狀越亮,給予的注意力越多)的時候,我們發現,它能更好地將圖像「翻譯成」標題。
本文引用地址:http://www.104case.com/article/201612/342188.htm當前的卷積神經網絡由10~20層ReLUs,數百萬個權值及數十億個連接組成。兩年前,訓練如此龐大的網絡可能需要數周時間,而隨著硬件、軟件和算法并行化(algorithm parallelization)的進步,訓練時間已經縮短至幾個小時。
卷積神經網絡的視覺系統良好表現促使包括谷歌、Facebook、微軟、IBM、雅虎、推特和Adobe在內的多數主要科技公司以及數量激增的創業公司開始啟動研發項目,部署基于卷積神經網絡的圖像識別產品和服務。
卷積神經網絡易于在芯片或現場可編程門列陣(FPGA)中得以高效實現。為了實現智能手機、相機、機器人和無人駕駛汽車上的實時視覺應用,NVIDIA、Mobileye、因特爾、高通和三星等許多公司都正在開發卷積神經網絡芯片。
分布式表征和語言處理
深度學習理論顯示,與不適用分布式表征的經典學習算法相比,深度網絡有兩處異常明顯的優勢。這些優勢源于節點權重(the power of composition)以及底層數據生成分布具有適當的組成結構。第一,學習分布式表征能夠將通過訓練而學習獲得的特性值泛化為新的組合(例如,n元特征有2n 組合可能)。第二,深度網絡中的表征層相互組合帶來了另一個指數級優勢的潛力(指數性的深度)。
多層神經網絡的隱藏層學會以一種易于預測目標輸出的方式來再現網絡輸入。一個很好的示范就是訓練多層神經網絡根據局部文本中的前述語句預測下一個詞。文本的每個詞表示成網絡中的N分之一向量,也就是說,每個成分的值為1,余下的為0。在第一層中,每個字創建一個不同模式的激活或單詞向量(如圖4所示)。在語言模型中,網絡中的其他層學習如何將輸入的單詞向量轉化成輸出單詞向量來預測下一個單詞,也能用來預測詞匯表中單詞作為文本中下一個單詞出現的概率。正如學習分布表征符號文本最初展示的那樣,網絡學習了包含許多激活節點(active components )、且每一個節點都可被解釋成一個單詞獨立特征的單詞向量。這些語義學特征并沒有在輸入時被清晰表現出來。而是在學習過程中被發現的,并被作為將輸入與輸出符號結構化關系分解為微規則(micro-rules)的好方法。當詞序列來自一個大的真實文本語料庫,單個微規則并不可靠時,學習單詞向量也一樣表現良好。當網絡被訓練用于預測新文本中的下一個詞時,一些單詞向量非常相似,比如Tuesday和Wednesday,Sweden和Norway 。這種表征被稱為分布式表征,因為它們的元素(特性)并非相互排斥,且它們構造信息與觀測到的數據變化相對應。這些單詞向量由所習得的特性組成,這些特性并非由科學家們事先決定而是由神經網絡自動發現。現在,從文本中習得的單詞向量表征被非常廣泛地使用于自然語言應用。
表征問題是邏輯啟發與神經網絡啟發認知范式爭論的核心問題。在邏輯啟發范式中,一個符號實體表示某一事物,因為其唯一的屬性與其他符號實體相同或者不同。它并不包含與使用相關的內部結構,而且為理解符號含義,就必須與審慎選取的推理規則的變化相聯系。相比之下,神經網絡使用大量活動載體( big activity vectors)、權重矩陣和標量非線性,實現一種快速「直覺 」推斷,它是輕松常識推理的基礎。
在介紹神經語言模型前,語言統計模型的標準方法并沒有使用分布式表征:它是基于計算短符號序列長度N(稱為N-grams,N元文法)出現的頻率。N-grams可能出現的次數與VN一致,這里的V指的是詞匯量的大小,考慮到詞匯量大的文本,因此需要更龐大的一個語料庫。N-grams把每一個詞作為一個原子單位,因此它不能在語義緊密相關的單詞序列中,一概而論,但是,神經語言模型可以實現上述功能,因為它們將每個單詞與真實特征值的向量關聯起來,并且語義相關的單詞在該向量空間中更為貼近。
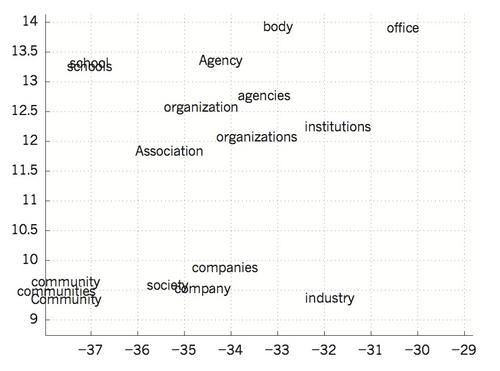
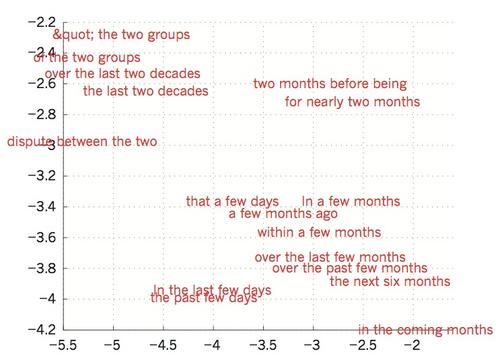
圖4|已完成學習的單詞向量的可視化展現
左邊介紹了為了建模語言而習得的詞匯表征,通過使用 t-SNE算法[103]非線性映射至二維空間中以便于觀察。右邊是一個由實現英-法互翻的遞歸神經網絡學習短語的二維空間表示。由圖可知,語義或排序相似的單詞表征映射較為接近 。詞匯的分布式表征通過使用反向傳播獲得,以此來學習每個單詞的表征形式及預測目標數量的功能,比如序列中的后續單詞(如語言建模)或者翻譯文字的全部序列(機器翻譯)。
遞歸神經網絡
最初引入反向傳播時,最令人激動的應用便是訓練遞歸神經網絡(簡稱RNNs)。對于那些需要序列連續輸入的任務(比如,語音和語言),RNNs是上乘之選(圖5)。RNNs一次處理一個輸入序列元素,同時維護隱式單元中隱含著該序列過去所有元素的歷史信息的「狀態向量」。當我們考慮隱式單元在不同的離散時間步長的輸出,就好像它們是在多層網絡深處的不同神經元的輸出(圖五,右)如何利用反向傳播訓練RNNs,一目了然。
RNNs是非常強大的動力系統,但訓練它們也被證實存在一些問題,因為反向傳播梯度在每個時間間隔內或增長或下降,因此,一段時間之后通常會導致結果激增或者降為零。
因先進的架構和訓練的方式,RNNs不僅被證實擅長預測文本中下一個字符或句子中下一個單詞,還可應用于更加復雜的任務。例如,某時刻閱讀英文句子中的單詞后,一個英語的「編碼器」網絡將被生成,從而幫助隱式單元的最終狀態向量很好地表征句子所傳達的思想。這種「思想向量(thought vector)」可以作為一個集大成的法語「編碼器」網絡的初始化隱式狀態(或額外的輸入),其輸出為法語翻譯首單詞的概率分布。如果從概率分布中選擇一個特定首單詞作為編碼網絡的輸入,將會輸出翻譯句子中第二個單詞的概率分布,依此類推,直到停止選擇為止。總體而言,這一過程是根據英語句子的概率分布而生成的法語單詞序列。這種近乎直接的機器翻譯方法的表現很快和最先進(state-of-the-art)的方法不相上下,同時引發人們對于理解句子是否需要使用推理發掘內部符號表示質疑。這與日常推理中涉及到根據合理結論類推的觀點是匹配的。
除了將法語句子翻譯成英語句子,還可以學習將圖片內容「翻譯」為英語句子(如圖3)。編碼器是一種在最后隱層將像素轉換為活動向量的深度卷積網絡。解碼器是一種類似機器翻譯和神經網絡語言模型的遞歸神經網絡。近年來,引發了人們對深度學習該領域的熱議。RNNs一旦展開(如圖5),可被視作是所有層共享同樣權值的深度前饋神經網絡。雖然它們的主要目的是長期學習的依賴性,但有關理論和經驗的例證表明很難學習并長期儲存信息。
為了解決這一問題,一個擴展網絡存儲的想法出現。第一種方案是采用了特殊隱式單元的LSTM,該自然行為便是長期的保存輸入。一種類似累加器和門控神經元的稱作記憶細胞的特殊單元:它通過在下一個時間步長擁有一個權值并聯接到自身,從而拷貝自身狀態的真實值和累積外部信號,但這種自聯接是另一個學習并決定何時清除記憶內容的單元的乘法門所操控。
LSTM網絡最終被證明比傳統的遞歸神經網絡(RNNs)更為有效,尤其是,每一個時間步長內有若干層時,整個語音識別系統能夠完全一致地將聲學轉錄為字符序列。目前,LSTM網絡及其相關形式的門控單元同樣也用于編碼與解碼網絡,并在機器翻譯中表現良好。
過去幾年里,幾位學者提出一些不同的方案來增強RNNs存儲器模塊。這些建議包括,神經圖靈機——通過加入RNNs可讀可寫的“類似磁帶”的存儲來增強網絡,而記憶網絡中的常規網絡通過聯想記憶來增強。記憶網絡在標準的問答基準測試中表現良好,記憶是用來記住稍后要求回答問題的事例。
除了簡單記憶化、神經圖靈機和記憶網絡被用于通常需要推理和符號操作的任務以外,還可以教神經圖靈機「算法」。除此以外,他們可以從未排序的輸入符號序列(其中每個符號都有與其在列表中對應的表明優先級的真實值)中,學習輸出一個排序的符號序列。可以訓練記憶網絡用來追蹤一個設定與文字冒險游戲和故事的世界的狀態,回答一些需要復雜推理的問題。在一個測試例子中,網絡能夠正確回答15句版的《指環王》中諸如「Frodo現在在哪?」的問題。
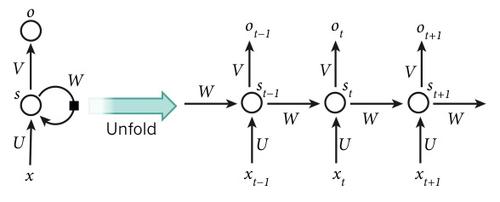
圖5 |一個遞歸神經網絡在時間中展開的計算和涉及的相關計算
人工神經元(例如,隱式樣單元分組節點在時間t的標準值下)獲得其他神經元的輸入——在之前的步驟中(黑色區域呈現,代表一步延遲,如左)。這樣,一個遞歸神經網絡可由xt的輸入序列元素,映射到一個輸出序列與元素ot,每次ot值取決于所有前面的xt?(t?≤t)。相同的參數(U,V矩陣W)在每步中使用。許多其他結構是可行的,包括一個變體的網絡可以生成的輸出序列(例如,詞語),每一個都作為下次的輸入步驟。反向傳播算法(圖1)可以直接應用于計算機圖形展開網絡,并對所有的標準陳述和參數,計算其總誤差的導數(例如,生成正確的輸出序列的對數概率)。
深度學習的未來
無監督學習促進了人們重燃對深度學習的興趣,但是,有監督學習的成功蓋過了無監督學習。雖然我們沒有關注這方面的評論,但是,從長遠來看,我們還是期望無監督學習能夠變得更加重要。(因為)人類和動物的學習方式大多為無監督學習:我們通過觀察世界來發現它的結果,而不是被告知每個對象的名稱。
人類視覺是一個智能的、基于特定方式的利用小或大分辨率的視網膜中央窩與周圍環繞區域對光線采集成像的活躍的過程。我們希望機器視覺能夠在未來獲得巨大進步,這些進步來自于那些端對端的訓練系統,并集合卷積神經網絡(ConvNets)和遞歸神經網絡(RNNs),利用強化學習來決定走向。結合了深度學習和強化學習的系統尚處在嬰兒期,但是,在分類任務上,它們已經超越了被動視覺系統,并在嘗試學習操作視頻游戲方面,產生了令人印象深刻的結果。
未來幾年,理解自然語言會是深度學習產生巨大影響的另一個領域。我們預測,當它們學習了某時刻選擇性地加入某部分的策略,那些使用遞歸神經網絡(RNNs)的系統將會更好地理解句子或整個文檔。
最終,人工智能的重大進步將來自將表征學習與復雜推理結合起來的系統。盡管深度學習和簡單推理已經用于語音和手寫識別很長一段時間了,我們仍需要通過大量向量操作的新范式替換基于規則的字符表達操作。



評論