如何快速使用大規模機器學習的核心技術?

具體來說,DMTK當前版本的工具包主要有以下幾個部分:
本文引用地址:http://www.104case.com/article/201602/287461.htm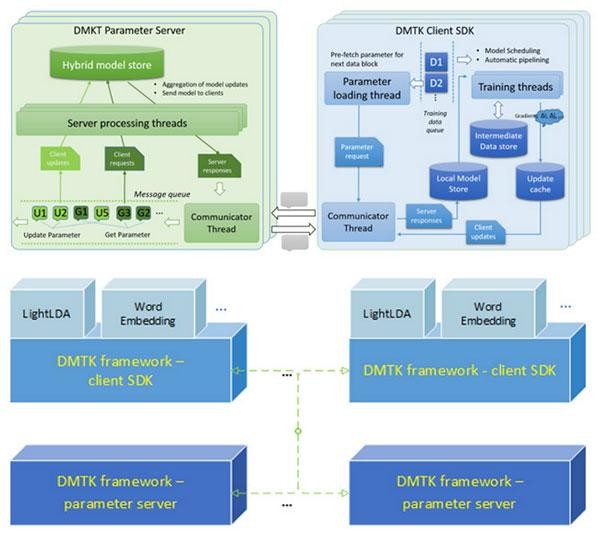
DMTK分布式機器學習框架
主要由參數服務器和客戶端軟件開發包(SDK)兩部分構成。
1. 參數服務器。重新設計過的參數服務器在原有基礎上從性能和功能上都得到了進一步提升——支持存儲混合數據結構模型、接受并聚合工作節點服務器的數據模型更新、控制模型同步邏輯等。
2. 客戶端軟件開發包(SDK)。包括網絡層、交互層的一些東西,支持維護節點模型緩存(與全局模型服務器同步)、節點模型訓練和模型通訊的流水線控制、以及片狀調度大模型訓練等。用戶并不需要清楚地知道參數和服務器的對應關系,SDK會幫助用戶自動將客戶端的更新發送至對應的參數服務器端。
通用分布式機器學習算法
LightLDA:LightLDA是一種全新的用于訓練主題模型的學習算法,是具有可擴展、快速、輕量級,計算復雜度與主題數目無關等特點的高效算法。在其分布式實現中,DMTK團隊做了大量系統優化使得其能夠在一個普通計算機集群上處理超大規模的數據和模型。例如,在一個由8臺計算機組成的集群上,只需要一個星期左右的時間,可以在具有1千億訓練樣本(token)的數據集上訓練具有1千萬詞匯表和1百萬個話題(topic)的LDA模型(約10萬億個參數)。這種規模的實驗以往在數千臺計算機的集群上也需要數以月計的時間才能得到相似結果。
分布式詞向量:詞向量技術近來被普遍地應用于計算詞匯的語義表示,它可以用作很多自然語言處理任務的詞特征。微軟為兩種計算詞向量的算法提供了高效的分步式實現:一種是標準的word2vec算法,另一種是可以對多義詞計算多個詞向量的新算法。
詞向量的作用是為了比較兩個詞之前的距離,基于這個距離來判斷語義上更深的信息。以前的詞向量模型以單詞為維度建立,每個單詞學出一組參數,每組參數即為詞向量,每個單詞通過映射至詞向量上來進行語義上的表達。一個向量在語義空間中對應一個點。而一詞多義的現象極為普遍,但如果多個意思在語義空間中只用一個點來表達就不太科學。如果我們希望學出多個語義空間中的點,在建立模型時就不會讓每個單詞只表達出一個向量,而是最開始時就讓每個單詞選擇N個向量進行定義,而后置入概率混合模型。這個模型通過在學習過程中不斷的優化,產生對每個單詞多個向量的概率分布,結合語境對每個向量分配概率,從而學習更有意義的詞向量表達。
一詞多義的學習框架和學習過程與一詞一義并沒什么不同,但它有更多的參數,并且需要在學習過程中分配多個向量各自對應的概率,因此復雜度更高。由于整個過程通過多機進行并行,因此還是能夠保證以足夠快的速度完成訓練。比如在對某網頁數據集(約1千億單詞)進行訓練時,8臺機器大概40個小時內就可以完成模型訓練。
DMTK提供了豐富的API接口給研發人員。大數據接口主要集中在并行框架這部分,來解決很多機器一起學習時,單機的客戶端如何調用參數服務器的問題。
王太峰為我們列舉了DMTK中對于不同需求的開發者設計的API:
保持原有機器學習算法流程:這類開發人員最需要的API就是同步參數,依照自己原有的算法進行訓練,只在需要多機之間交互時利用DMTK的API來獲取模型參數(GET)和發送更新(ADD)。通常這類開發需要花的精力比較少。 從頭設計算法:這類開發人員不需要設計完整算法流程,只需按照DMTK中對數據塊描述,接口會告訴DMTK每條數據需要什么參數,如何利用數據進行參數更新。DMTK客戶端SDK會自動啟動內置的學習流程,進行逐條數據的訓練,并在必要的時候進行模型交互。
目前DMTK在GitHub上有1400多顆星,在分布式機器學習的框架上來說排名是非常靠前的。用戶也反饋了很多對代碼修復的意見、和對增加一些額外功能需求的建議。
DMTK并非完整的開箱即用解決方案,其中分布式的算法,如LightLDA,WordEmbedding可以為很多用戶直接所用。同時,DMTK在設計上允許用戶進行后續擴展,使其能夠支持更多的算法和平臺。王太峰還透露,目前DMTK還是利用現有的文檔系統(Filesystem),直接將數據分布在里面,各個機器處理本地硬盤上的數據。在此基礎上,DMTK正逐漸增加對Hadoop的一些支持,如利用HDFS去讀數據,幫助用戶調度作業等。
后記
就在不久前,微軟公司還發布了另一套機器學習工具包,即計算網絡工具包(Computational Network Toolkit)——或者簡稱CNTK。另外,谷歌開源人工智能系統TensorFlow,IBM開源機器學習平臺SystemML。這對廣大開發者和創業公司來說,無疑在很大程度上簡化基礎技術的投入和難度。










評論