高速可擴展的Montgomery乘法器設計方案

3 性能分析與比較
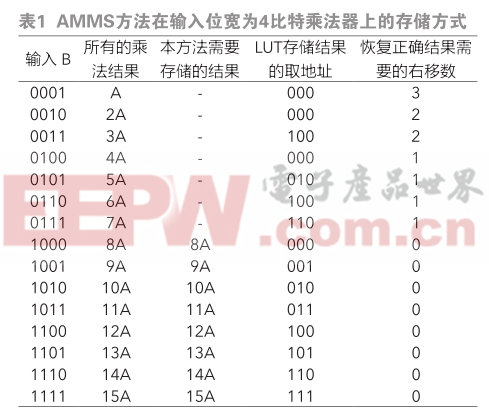
本文引用地址:http://www.104case.com/article/187254.htm對于基為64的Montgomery乘法器,計算一次模乘運算的總時鐘周期數時,需要考慮NW≤2NS和NW>2NS兩種情況,NW代表操作數所含的字數。一個MMcell需要兩個時鐘周期的執行時間,因此一個字經過流水線的總時鐘周期數是2NS+1。由于每次可處理6 bit,所以需

從表1可以看出,在不同條件下,本文的設計在性能上平均比Tenca的設計提高了48%。本文采用字長32 bit,級數NS=8實現基為64的Montgomery乘法器,且使用Verilog HDL語言實現上述設計,并使用ModelSim 對設計進行了仿真驗證;基于SMIC 0.18 μm CMOS標準數字邏輯工藝,利用Design Compiler 進行了綜合設計,結果顯示頻率達到251 MHz,面積為37 381門。
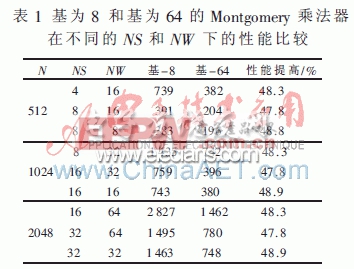
顧葉華在參考文獻[4]中對Tenca提出的流水線結構進行了優化,提出了一種基為4的Montgomery乘法器方案。面積和速度的比較如表2所示。從表中可以看出,本設計在512 bit和1 024 bit下具有最小的時間×面積的值,綜合性能最優。
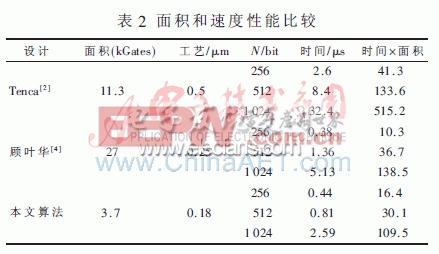
本文對Tenca提出的基為8的可擴展Montgomery模乘器進行改進,采用了更高的基為64的設計,進一步減少了部分積的個數,縮短了運算時間。與Tenca在參考文獻[2]中的設計相比,時鐘周期數平均減少了48%,并且縮短了關鍵路徑的延遲相比,綜合性能具有明顯地提高。


評論