Linux下Cold Fire 片內SRAM的應用程序優(yōu)化設計

3.3 配置實時數據和函數到片內SRAM中執(zhí)行
把用戶空間的實時數據和函數放置到片內SRAM中執(zhí)行,由于處理器可以直接從片內SRAM中存取數據和指令,減少了處理器存取數據和指令的周期,提高了程序的執(zhí)行效率。首先,放置實時數據到處理器片內SRAM中。通過S_malloc和S_free函數來實現(xiàn):S_malloc用來申請?zhí)幚砥鲀却婵臻g,S_free用來對這一申請的空間進行釋放。為了靈活使用定義的S_malloc和S_free函數,需要定義一個結構體和地址指針:

然后,通過動態(tài)內存分配方式可以把MP3解碼程序中的實時數據放入處理器內存中執(zhí)行。加載函數到SRAM中與加載實時數據不同,需要通過指針和枚舉變量來實現(xiàn)。首先通過一個宏定義設置每個函數大小為4 KB,并使用枚舉變量為函數分配處理器片內SRAM執(zhí)行的起始地址。

SRAMFUNC2=SRAM_BIG_FUNC1+BIG_FUNC_SIZE,…};
在定義完函數運行時加載的存儲地址之后,把MP3解碼程序中的MPEGSUB_synthesis和imdct_1等函數通過字符串拷貝的方式復制到處理器片內SRAM中執(zhí)行,經過編譯、鏈接這些函數在執(zhí)行時將會加載到相應的SRAM單元塊中。這樣就減少了處理器執(zhí)行解碼函數所需的時間,提高了程序的執(zhí)行效率。
4 性能測試與分析
為了驗證基于處理器片內SRAM的優(yōu)化設計方案,我們在MCF5329EVB開發(fā)板上對經該方案優(yōu)化過的MP3解碼器進行了驗證和測試。
首先,進行功能測試,應用MPEG組織推薦的測試碼流(128 kb/s,44.1 kHz)。選用一段音頻test.mp3,分別用標準浮點解碼器和本文設計的音頻解碼器進行本地解碼測試,并對其解碼波形進行比較分析。從圖4的波形比較可以看到,經過本方案優(yōu)化設計的解碼器解碼波形與標準浮點解碼器基本無差別。經人耳測試,無法辨別出兩者解碼輸出的差別。所以,從功能上講本文設計的基于片內SRAM的應用程序優(yōu)化方案是可行的。

其次,進行性能測試。在測試平臺上分別對優(yōu)化前后解碼器的MIPS消耗數和空間消耗量進行比較分析,如表2所列。
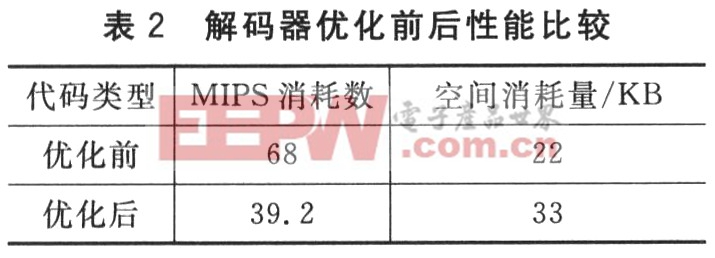
優(yōu)化前,解碼器MIPS消耗數為68 MIPS@240MHz;優(yōu)化后,解碼器MIPS消耗數為39.2 MIPS@240 MHz。在硬件條件允許的情況下,消耗的內存雖然有一定的增加,但是經過本文方案優(yōu)化后,解碼效率得到了很大的提高。
結 語
本文提出了在嵌入式Linux操作系統(tǒng)下基于處理器片內SRAM的應用程序優(yōu)化設計方案。以MP3解碼器為例,通過從配置音頻驅動程序、實時數據和函數到處理器片內SRAM中執(zhí)行來對解碼器進行優(yōu)化設計,并在ColdFire5329開發(fā)平臺上成功實現(xiàn)該方案。優(yōu)化后的MP3播放器不僅解碼效率高,而且音質好,完全可以在中低端處理器上實現(xiàn)實時播放,使低性能CPU處理復雜應用程序成為可能。該方案有效地提高了應用程序的執(zhí)行效率,降低了功耗,對嵌入式Linux應用產品開發(fā)有著重要參考價值。









評論