孤立詞語音識別系統的DSP實現

2.2 系統主要功能模塊構成
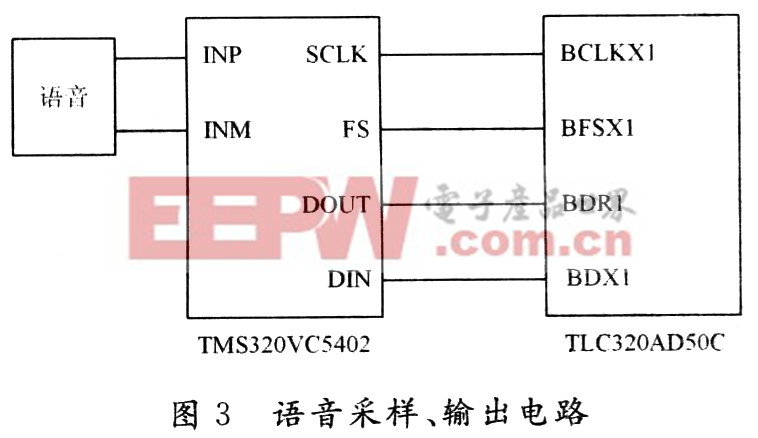
語音處理模塊采用TI TMS320VC5402,其主要特點包括:采用改進的哈佛結構,一條程序總線(PB),三條數據總線(CB,DB,EB)和四條地址總線(PAB,CAB,DAB,EAB),帶有專用硬件邏輯CPU(40位算術邏輯單元(ALU),包括1個40位桶形移位器和二個40位累加器;一個17×17乘法器和一個40位專用加法器,允許16位帶或不帶符號的乘法),片內存儲器(八個輔助寄存器及一個軟件棧),片內外專用的指令集,允許使用業界最先進的定點DSP C語言編譯器。TMS320VC5402含4 KB的片內ROM和16 KB的雙存取RAM,一個HPI(HostPortInterface)接口,二個多通道緩沖單口MCBSP(Multi-Channel Buffered SerialPort),單周期指令執行時間10 ns,帶有符合IEEE1149.1標準的JTAG邊界掃描仿真邏輯。語音輸入、輸出的模擬前端采用TI公司的TLC320ADSOC,它是一款集成ADC和DAC于一體的模擬接口電路,并且與DSP接口簡單,性能高、功耗低,已成為當前語音處理的主流產品。16位數據結構,音頻采樣頻率為2~22.05 kHz,內含抗混疊濾波器和重構濾波器的模擬接口芯片,還有一個能與許多DSP芯片相連的同步串行通信接口。TLC320AD50C片內還包括一個定時器(調整采樣率和幀同步延時)和控制器(調整編程放大增益、鎖相環PLL、主從模式)。TLC320AD50C與TMS320VC5402的硬件連接,如圖3所示。
3 語音識別算法實現
3.1 語音信號的端點檢測
語音的端點檢測是語音識別中最基本的模塊,在嵌入式語音識別系統中更是占有非常重要的地位:一方面端點檢測的結果不準確,系統的識別性能就得不到保證;另一方面如果端點檢測的結果過于放松,雖然語音部分被很好地包含在處理的信號中,但是增加過多的靜音則會增加系統的運算量,同時對識別性能也有負面影響。因此為能量和過零率兩個參數分別設定兩個門限,一個是比較低的門限,數值比較小,對信號的變化比較敏感,很容易就被超過。另一個是比較高的門限,數值比較大,信號必須達到一定的強度,該門限才可能被超過。低門限被超過未必就是語音的開始,有可能是時間很短的噪聲引起的。高門限被超過,則基本確信是由于語音信號引起的。
整個語音信號的端點檢測可以分為四段:靜音、過渡段、語音段、結束。程序中使用一個變量status來表示當前所處的狀態。在靜音段,如果能量或過零率超越了低門限,就應該開始標記起始點,進入過渡段。在過渡段中,由于參數的數值比較小,不能確信是否處于真正的語音段,因此只要兩個參數的數值都回落到低門限以下,就將當前狀態恢復到靜音狀態。而如果在過渡段中兩個參數中任意一個超過了高門限,就可以確信進入語音段了。一些突發性的噪聲可以引發短時能量或過零率的數值很高,但是往往不能維持足夠長的時間,這些可以通過設定最短時間門限來判別。當前狀態處于語音段時,如果兩個參數的數值降低到低門限以下,而且總的計時長度小于最短時間門限,則認為這是一段噪音,繼續掃描以后的語音數據。否則就標記好結束端點,并返回。
3.2 語音特征參數的提取
近年來,一種能夠比較充分利用人耳這種特殊的感知特新的參數得到了廣泛的應用,這就是Mel尺度倒譜參數(Mel-scaled Cepstrum Coefficients,MFCC)。它和線性頻率的轉換關系是:
fMel=2 596log10(1+f/700)
MFCC參數是按幀計算的。首先要通過FFT得到該幀信號的功率譜,轉換為Mel頻率下的功率譜。這需要在計算之前先在語音的頻譜范圍內設置若干個帶通濾波器Hm(n)。MFCC參數的計算流程為:
(1)確定每一幀語音采樣序列的點數,本系統采取N=256點。對每幀序列s(n)進行預加重處理后再經過離散FFT變換,取模的平方得到離散功率譜s(n)。
(2)計算s(n)通過M個Hm(n)后所得的功率值,即計算s(n)和Hm(n)在各個離散頻率點上乘積之和,得到M個參數Pm,m=0,1,…,M-1。
(3)計算Pm的自然對數,得到Lm,m=0,1,…,M-1。
(4)對L0,L1,…,LM-1計算其離散余弦變換,得到Dm,m=0,1,…,M-1。
(5)舍去代表直流成分的D0,取D1,D2,…,DK作為MFCC參數。此處K=12。
3.3 特定人語音識別算法
在孤立詞語音識別中,最為簡單有效的方法是采用DTW動態時間規整算法,設參考模板特征矢量序列為A={a1,a2,…,aj),輸入語音特征矢量序列為B={b1,b2,…,bk),j≠k。DTW算法就是要尋找一個最佳的時間規整函數,使得語音輸入B的時間軸k映射到參考模板A的時間軸j上總的累計失真最小。
將己經存入模板庫的各個詞條稱為參考模板,一個參考模板可以表示為{R(1),R(2),…,R(M)},m為訓練語音幀的時序標號,m=1為起點語音幀,m=M為終點語音幀,因此M為該模式包含的語音幀總數,R(m)為第m幀語音的特征矢量。所要識別的一個輸入詞條語音稱為參考模板,可表示為{T(1),T(2),…,T(N)),n為測試語音幀標號,模板中共包含N幀音,T(n)為第n幀音的特征矢量。







評論