孤立詞語音識別系統的DSP實現

0 引 言
在孤立詞語音識別中,最為簡單有效的方法是采用動態時間規整(Dynamic Time Warping,DTW)算法,該算法解決了發音長短不一的模板匹配問題,是語音識別中出現最早、較為經典的一種算法。用于孤立詞識別,該算法較現在比較流行的HMM算法在相同的環境條件下,識別效果相差不大,但HMM算法要復雜的多,這主要體現在HMM算法在訓練階段需要提供大量的語音數據,通過反復計算才能得到模型參數,而DTW算法的訓練中幾乎不需要額外的計算。所以在孤立詞語音識別中,DTW算法仍得到廣泛的應用。本系統就采用了該算法。
1 系統概述
語音識別系統的典型實現方案如圖1所示。輸入的模擬語音信號首先要進行預處理,包括預濾波、采樣和量化、加窗、斷點檢測、預加重等。語音信號經過預處理后,接下來重要的一環就是特征參數提取,其目的是從語音波形中提取出隨時間變化的語音特征序列。然后建立聲學模型,在識別的時候將輸入的語音特征同聲學模型進行比較,得到最佳的識別結果。
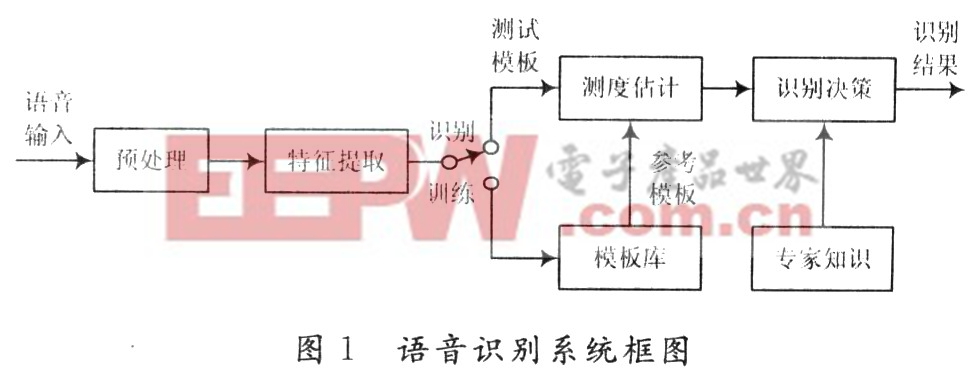
2 硬件構成
2.1 系統構成
這里采用DSP芯片為核心(圖2),系統包括直接雙訪問快速SRAM、一路ADC/一路DAC及相應的模擬信號放大器和抗混疊濾波器。外部只需擴展FLASH存儲器、電源模塊等少量電路即可構成完整系統應用。








評論