基于嵌入式操作系統的控制系統平臺設計

3.2.1數據結構設計
實時數據庫與其他一般數據庫一樣,包含一組對象及其結構,由于目前對實時數據庫還沒有提出統一的數據模型,所以不同廠家開發的數據庫的數據結構都有很大差別。本系統的實時數據庫,一個基本的數據對象為“數據”,一個數據包含若干信息,如數據名稱、數據類型、數據位置、數據長度等。
考慮到數據的存取效率,程序運行一開始,我們將在內存區開辟一段緩沖區,緩沖區中只存放數據,如果緩沖區大小不夠,即緩沖區的數據較多,可以自動擴展緩沖區大小。實時數據存放在緩沖區時,我們采取這種思想:如果不是bit型數據,由于數據長度都是字節的整數倍,存入緩沖區中以字節來進行存儲,該數據的長度length是以字節來計算。如果是bit型數據,存入緩沖區中,該數據的長度length是以位來計算,接著再存儲一個實時數據,若為非bit型數據,則從下一個字節開始存放,即原來的bit型數據占用一個字節,若為bit型數據,根據此數據的長度來判斷其存放位置,這里又分兩種情況,如果這兩個bit型數據的長度沒有超過8位,則緊接著前一個bit型數據后存儲這個bit型數據,如果兩個bit型數據的長度超過8位,則從下一個字節開始存放,即原來的bit型數據占用一個字節。
3.2.2數據存取設計
為了存取方便,我們將所有的實時數據組成一個鏈表,鏈表的節點類型為上述的rtdb_data_t結構。當向實時緩沖區中加入一條數據時,就自動會計算出數據存儲位置、長度等信息,并在實時數據庫鏈表中加上一個節點。這樣,取實時數據就非常靈活和方便,如果知道實時數據的名稱,則可以遍歷鏈表得到數據,如果知道數據的存儲位置和長度,則可以利用實時數據庫提供的接口直接從緩沖區中獲得數據,而不必遍歷鏈表,因為遍歷鏈表需要花費一些時間,這在實時性要求較高的本系統中不太適合,所以本系統常常采用后一種方法存取數據。實時數據庫鏈表結構如圖3所示。
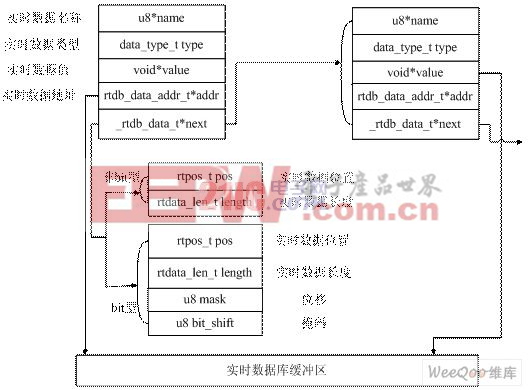
圖3實時數據庫鏈表結構
linux操作系統文章專題:linux操作系統詳解(linux不再難懂)



評論