基于DSP+FPGA的機器人語音識別系統的設計

3.3.1 語音信號的預加重和加窗
預加重處理主要是去除聲門激勵和口鼻輻射的影響,預加重數字濾波H(Z)=1一KZ-1,其中是為預加重系數,接近1,本系統中k取0.95。對語音序列X(n)進行預加重,得到預加重后的語音序列x(n):x(n)=X(n)一kX(n一1) (1)
系統采用一個有限長度的漢明窗在語音序列上進行滑動,用以截取幀長為20 ms,幀移設為10 ms的語音信號,采用漢明窗可以有效減少信號特征的丟失。
3.3.2 端點檢測
端點檢測在詞與詞之間有足夠時間間隙的情況下檢測出詞的首末點,一般采用檢測短時能量分布,方程為:
其中,x(n)為漢明窗截取語音序列,序列長度為160,所以N取160,為對于無音信號E(n)很小,而對于有音信號E(n)會迅速增大為某一數值,由此可以區分詞的起始點和結束點。
3.3.3特征向量提取
特征向量是提取語音信號中的有效信息,用于進一步的分析處理。目前常用的特征參數包括線性預測倒譜系數LPCC、美爾倒譜系數MFCC等。語音信號特征向量采用Mel頻率倒譜系數MFCC(Mel Frequency Cepstrum Coeficient的提取,MFCC參數是基于人的聽覺特性的,他利用人聽覺的臨界帶效應,采用MEL倒譜分析技術對語音信號處理得到MEL倒譜系數矢量序列,用MEL倒譜系數表示輸入語音的頻譜。在語音頻譜范圍內設置若干個具有三角形或正弦形濾波特性的帶通濾波器,然后將語音能量譜通過該濾波器組,求各個濾波器輸出,對其取對數,并做離散余弦變換(DCT),即可得到MFCC系數。MFCC系數的變換式可簡化為:
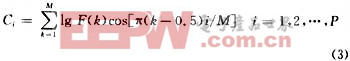
其中,i為三角濾波器的個數,本系統選P為16,F(k)為各個濾波器的輸出數據,M為數據長度。
3.3.4 語音信號的模式匹配和訓練
模型訓練即將特征向量進行訓練建立模板,模式匹配即將當前特征向量與語音庫中的模板進行匹配得出結果。語音庫的模式匹配和訓練采用隱馬爾可夫模型HMM (Hidden Markov Models),他是一種統計隨機過程統計特性的概率模型一個雙重隨機過程,因為隱馬爾可夫模型能夠很好地描述語音信號的非平穩性和可變性,因此得到廣泛的使用。
HMM的基本算法有3種:Viterbi算法,前向一后向算法,Baum-Welch算法。本次設計使用Viterbi算法進行狀態判別,將采集語音的特征向量與語音庫的模型進行模式匹配。Baum-Welch算法用來解決語音信號的訓練,由于模型的觀測特征是幀間獨立的,從而可以使用Baum- Welch算法進行HMM模型的訓練。
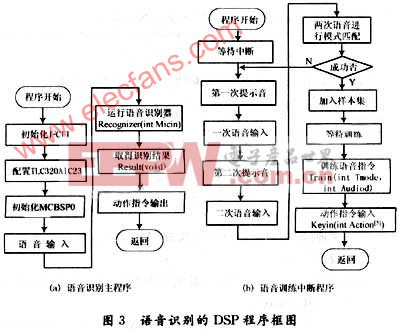
3.4 語音識別程序的DSP開發
DSP的開發環境為CCS3.1及。DSP/BIOS,將語音識別和訓練程序分別做成模塊,定義為不同的函數,在程序中調用。定義語音識別器函數為int Recognizer(int Micin),識別結果輸出函數為int Result(void),語音訓練器函數為int Train(int Tmode,int Audiod),動作指令輸入函數為int Keyin(int Action)。
語音識別器的作用是將當前語音輸入變換成語音特征向量,并對語音庫的模板進行匹配并輸出結果,語音應答輸出函數將獲取的語音識別結果對應的語音應答輸出,語音訓練是將多個不同年齡、不同性別、不同口音的人語音指令輸入轉化為訓練庫的模板。為防止樣本錯誤,每個人的語音指令需要訓練2次,對于2次輸入用用歐氏距離去進行模式匹配,若2次輸入相似度達到95%,則加入樣本集。語音應答輸入函數是為每個語音庫中模板輸入對立的語音輸出,以達到語言應答目的。系統工作狀態為執行語言識別子程序,訓練時執行外部中斷,執行訓練函數,取得數據庫模板,訓練完畢返回。程序框圖如圖3所示。
本文引用地址:http://www.104case.com/article/151217.htm









評論