Web文檔聚類中k-means算法的改進

利用向量空間模型對文檔進行聚類只能根據文檔的二種信息:(1)文檔中每個特征詞出現的頻率;(2)文檔的長度。由于文檔長度與文檔所屬的類別之間的關系不大,因此可以把所有的文檔長度進行歸一化處理,從而使文檔向量具有統一的特征維數m。

其中:m為特征向量維數,αk為二個文檔對應特征詞條的四位碼字的十進制數值差的絕對值。由于這種相似性的計算使用的是整數,所以計算速度和精度得到一定的提高。
可以利用簡單的示例驗證公式(5)的合理性。當二個文檔完全相似時,sim(di,dj)的值等于1,而二個文檔完全不同時它的值為0。這種方法不僅反應了文檔之間的差異,而且定量地描述了這種差異性,從而為文檔的聚類提供了依據。下面通過對具體的Web文檔進行實驗并進一步地驗證。
3實 驗
實驗用的文檔是從搜狐的中文網站上獲取的娛樂類文檔,選用其中的1500篇。對這1500篇文檔進行手工分類,如表1所示共分為10類。

衡量信息檢索性能的召回率和精度也是衡量分類算法效果的常用指標。然而聚類過程中并不存在自動分類類別與手工分類類別確定的一一對應關系,因此無法像分類一樣直接以精度和召回率作為評價標準。為此本文選擇了平均準確率作為評價的標準。平均準確率通過考察任意二篇文章之間類屬關系是否一致來評價聚類的效果。
試驗中對使用公式(3)和(5)的改進k-means算法和原k-means算法的平均準確度進行了比較,實驗結果如表2所示。
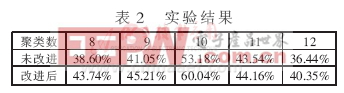
實驗結果表明,改進后的k-means算法與原k-means算法在運行速度上基本相同甚至略快,平均準確度則比原算法有了普遍提高,尤其在正確指定聚類數k時,平均準確度提高了近7%,說明此算法具有較高的準確性。由于實驗中使用的文檔集很小,所以改進的算法優勢不很明顯。
4結束語
本文對k-means算法進行了改進。根據不同位置的特征詞條對文檔內容的不同決定程度,提出一種新的文檔特征詞條的權重評價函數,并在此基礎上提出一種文檔相似性的度量方法。實驗表明改進后的算法不僅保留了原k-means算法效率高的優點,而且在平均準確度方面比原算法有了較大提高。實驗還表明,k-means算法要依賴原始聚類數k的選擇。如何為初始文檔集選擇合適的聚類數k以及進一步提高平均準確度是今后改進k-means算法的主要研究方向。


評論