CV不存在了?Meta發布「分割一切」AI 模型,CV或迎來GPT-3時刻

CV 研究者接下來的路要怎么走?

「這下 CV 是真不存在了。< 快跑 >」這是知乎網友對于一篇 Meta 新論文的評價。
如標題所述,這篇論文只做了一件事情:(零樣本)分割一切。類似 GPT-4 已經做到的「回答一切」。

Meta 表示,這是第一個致力于圖像分割的基礎模型。自此,CV 也走上了「做一個統一某個(某些?全部?)任務的全能模型」的道路。

在此之前,分割作為計算機視覺的核心任務,已經得到廣泛應用。但是,為特定任務創建準確的分割模型通常需要技術專家進行高度專業化的工作,此外,該項任務還需要大量的領域標注數據,種種因素限制了圖像分割的進一步發展。
Meta 在論文中發布的新模型名叫 Segment Anything Model (SAM) 。他們在博客中介紹說,「SAM 已經學會了關于物體的一般概念,并且它可以為任何圖像或視頻中的任何物體生成 mask,甚至包括在訓練過程中沒有遇到過的物體和圖像類型。SAM 足夠通用,可以涵蓋廣泛的用例,并且可以在新的圖像『領域』上即開即用,無需額外的訓練。」在深度學習領域,這種能力通常被稱為零樣本遷移,這也是 GPT-4 震驚世人的一大原因。

論文地址:https://arxiv.org/abs/2304.02643
項目地址:https://github.com/facebookresearch/segment-anything
Demo 地址:https://segment-anything.com/
除了模型,Meta 還發布了一個圖像注釋數據集 Segment Anything 1-Billion (SA-1B),據稱這是有史以來最大的分割數據集。該數據集可用于研究目的,并且 Segment Anything Model 在開放許可 (Apache 2.0) 下可用。
我們先來看看效果。如下面動圖所示,SAM 能很好的自動分割圖像中的所有內容:
SAM 還能根據提示詞進行圖像分割。例如輸入 Cat 這個提示詞,SAM 會在照片中的幾只貓周圍繪制框并實現分割:

SAM 還能用交互式點和框的方式進行提示:


此外,SAM 還能為不明確的提示生成多個有效掩碼:

英偉達人工智能科學家 Jim Fan 表示:「對于 Meta 的這項研究,我認為是計算機視覺領域的 GPT-3 時刻之一。它已經了解了物體的一般概念,即使對于未知對象、不熟悉的場景(例如水下圖像)和模棱兩可的情況下也能進行很好的圖像分割。最重要的是,模型和數據都是開源的。恕我直言,Segment-Anything 已經把所有事情(分割)都做的很好了。」
 推特地址:https://twitter.com/DrJimFan/status/1643647849824161792
推特地址:https://twitter.com/DrJimFan/status/1643647849824161792
還有網友表示,NLP 領域的 Prompt 范式,已經開始延展到 CV 領域了,可以預想,今年這類范式在學術界將迎來一次爆發。

更是有網友表示蚌不住了,SAM 一出,CV 是真的不存在了。投稿 ICCV 的要小心了。

不過,也有人表示,該模型在生產環境下的測試并不理想。或許,這個老大難問題的解決仍需時日?
方法介紹
此前解決分割問題大致有兩種方法。第一種是交互式分割,該方法允許分割任何類別的對象,但需要一個人通過迭代細化掩碼來指導該方法。第二種,自動分割,允許分割提前定義的特定對象類別(例如,貓或椅子),但需要大量的手動注釋對象來訓練(例如,數千甚至數萬個分割貓的例子)。這兩種方法都沒有提供通用的、全自動的分割方法。
SAM 很好的概括了這兩種方法。它是一個單一的模型,可以輕松地執行交互式分割和自動分割。該模型的可提示界面允許用戶以靈活的方式使用它,只需為模型設計正確的提示(點擊、boxes、文本等),就可以完成范圍廣泛的分割任務。
總而言之,這些功能使 SAM 能夠泛化到新任務和新領域。這種靈活性在圖像分割領域尚屬首創。
Meta 表示,他們受到語言模型中提示的啟發,因而其訓練完成的 SAM 可以為任何提示返回有效的分割掩碼,其中提示可以是前景、背景點、粗框或掩碼、自由格式文本,或者說能指示圖像中要分割內容的任何信息。而有效掩碼的要求僅僅意味著即使提示不明確并且可能指代多個對象(例如,襯衫上的一個點可能表示襯衫或穿著它的人),輸出也應該是一個合理的掩碼(就如上面動圖「SAM 還能為為不明確的提示生成多個有效掩碼」所示)。此任務用于預訓練模型并通過提示解決一般的下游分割任務。
如下圖所示 ,圖像編碼器為圖像生成一次性嵌入,而輕量級編碼器將提示實時轉換為嵌入向量。然后將這兩個信息源組合在一個預測分割掩碼的輕量級****中。在計算圖像嵌入后,SAM 可以在 50 毫秒內根據網絡瀏覽器中的任何提示生成一個分割。
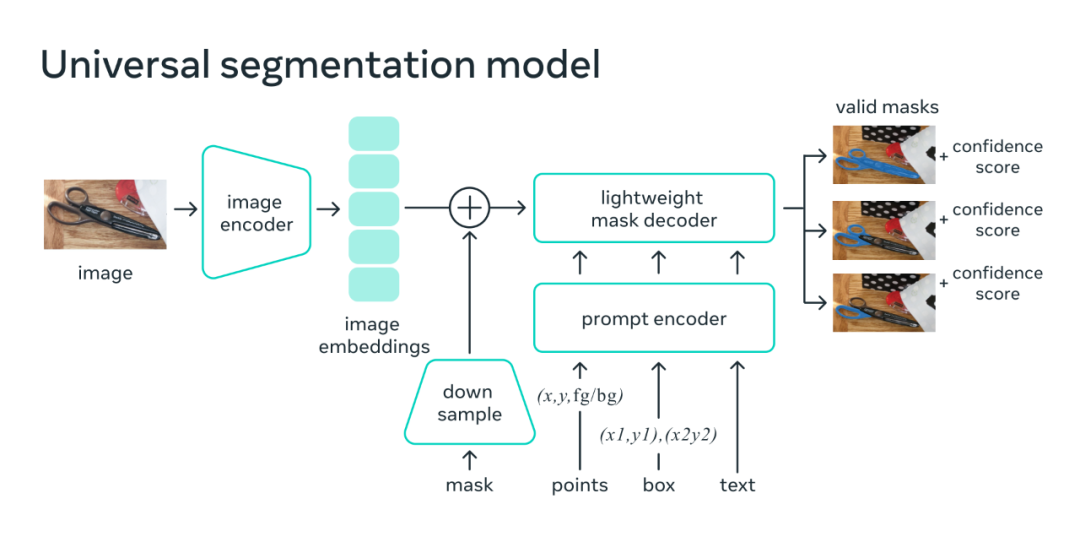 在 web 瀏覽器中,SAM 有效地映射圖像特征和一組提示嵌入以產生分割掩碼
在 web 瀏覽器中,SAM 有效地映射圖像特征和一組提示嵌入以產生分割掩碼
1100 萬張圖片,1B+ 掩碼
數據集是使用 SAM 收集的。標注者使用 SAM 交互地注釋圖像,之后新注釋的數據又反過來更新 SAM,可謂是相互促進。
使用該方法,交互式地注釋一個掩碼只需大約 14 秒。與之前的大規模分割數據收集工作相比,Meta 的方法比 COCO 完全手動基于多邊形的掩碼注釋快 6.5 倍,比之前最大的數據注釋工作快 2 倍,這是因為有了 SAM 模型輔助的結果。
最終的數據集超過 11 億個分割掩碼,在大約 1100 萬張經過許可和隱私保護圖像上收集而來。SA-1B 的掩碼比任何現有的分割數據集多 400 倍,并且經人工評估研究證實,這些掩碼具有高質量和多樣性,在某些情況下甚至在質量上可與之前更小、完全手動注釋的數據集的掩碼相媲美 。
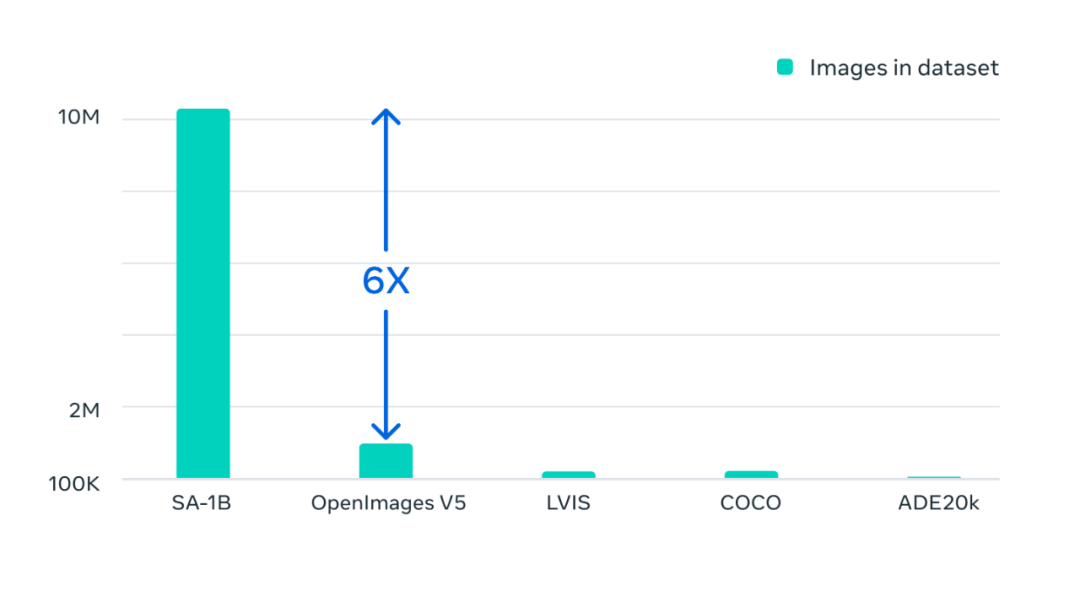
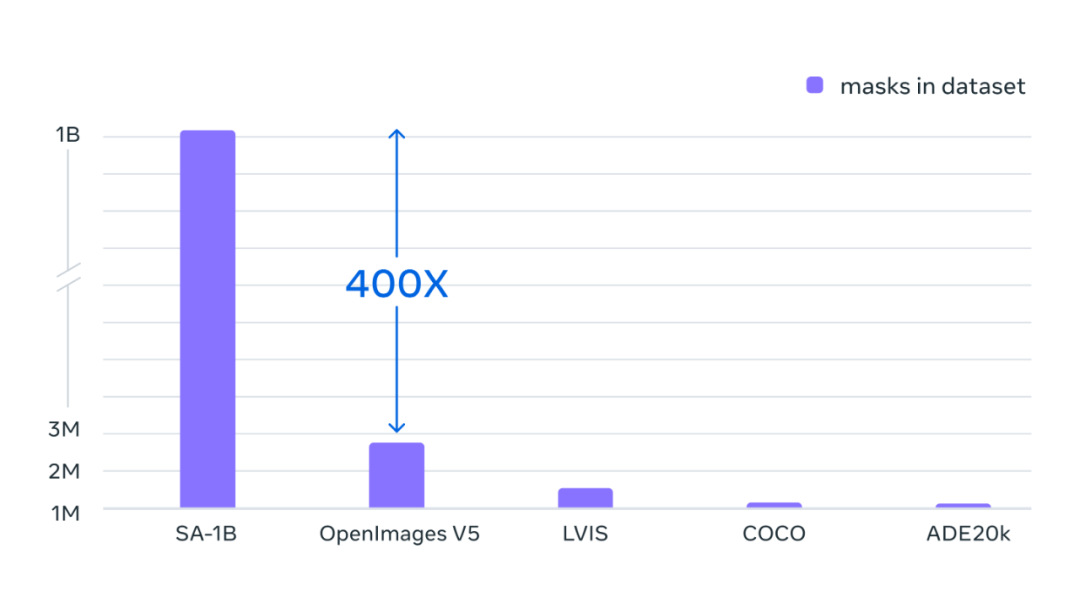 Segment Anything 對使用數據引擎收集的數百萬張圖像和掩碼進行訓練的結果,得到一個包含 10 億個分割掩碼的數據集,是以往任何分割數據集的 400 倍。
Segment Anything 對使用數據引擎收集的數百萬張圖像和掩碼進行訓練的結果,得到一個包含 10 億個分割掩碼的數據集,是以往任何分割數據集的 400 倍。
SA-1B 的圖像來自跨不同地理區域和收入水平的多個國家或地區的照片提供者,在擁有更多圖像的同時對所有地區的總體代表性也更好。Meta 分析了其模型在感知性別表現、感知膚色和年齡范圍方面的潛在偏差,結果發現 SAM 在不同群體中的表現類似。
SA-1B 可以幫助其他研究人員訓練圖像分割的基礎模型。Meta 也進一步希望這些數據能夠成為帶有附加注釋的新數據集的基礎,例如與每個 mask 相關的文本描述。
未來展望
通過研究和數據集共享,Meta 希望進一步加速對圖像分割以及更通用圖像與視頻理解的研究。可提示的分割模型可以充當更大系統中的一個組件,執行分割任務。作為一種強大的工具,組合(Composition)允許以可擴展的方式使用單個模型,并有可能完成模型設計時未知的任務。
Meta 預計,與專門為一組固定任務訓練的系統相比,基于 prompt 工程等技術的可組合系統設計將支持更廣泛的應用。SAM 可以成為 AR、VR、內容創建、科學領域和更通用 AI 系統的強大組件。比如 SAM 可以通過 AR 眼鏡識別日常物品,為用戶提供提示。
SAM 還有可能在農業領域幫助農民或者協助生物學家進行研究。

未來在像素級別的圖像理解與更高級別的視覺內容語義理解之間,我們將看到更緊密的耦合,進而解鎖更強大的 AI 系統。
來源:機器之心
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

