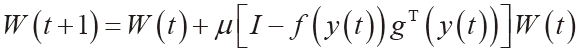Apache Iceberg在小紅書的探索與實踐

以下文章來源于DataFunTalk ,作者孫超
目前小紅書對數據湖技術的探索主要分為三個方向,第一個方向是在小紅書云原生架構下,對于大規模日志實時入湖的實踐,第二個方向是業務數據的CDC實時入湖實踐,第三個方向是對實時數據湖分析的探索。
今天的分享也主要圍繞這三個方向展開,并在最后介紹我們對未來工作的規劃:
- 日志數據入湖
- CDC實時入湖
- 實時湖分析探索
- 未來規劃
01 日志數據入湖
1. 小紅書數據平臺架構
在進入主題之前先介紹一下小紅書數據平臺的基本架構。
總體來說,小紅書數據平臺與其他互聯網公司大同小異,主要不同在于小紅書的基礎架構是“長”在多朵公有云之上的。在數據采集層,日志和RDBMS的數據源來自不同的公有云;在數據存儲加工層,絕大多數數據會存儲于AWS S3對象存儲;同時,數倉體系也是圍繞著S3來建設的,實時ETL鏈路基于Kafka、Flink,離線分析鏈路基于AWS EMR上的Spark、Hive、Presto等;在數據共享層,諸如Clickhouse、StarRocks、TiDB等OLAP引擎,為上層報表提供一些近實時的查詢。以上就是小紅書數據平臺整體的架構組成。
2. APM日志數據入湖
接下來我們用APM(Application Performance Monitor)的例子來介紹Iceberg如何在當前架構體系下運轉。
(1)使用Iceberg之前的APM鏈路
APM主要記錄小紅書APP前端和客戶端性能相關的埋點日志,可以達到百萬每秒的RPS。以前的離線鏈路是先將埋點數據發送到阿里云的Kafka,通過Flink作業落到阿里云的OSS對象存儲,然后通過Distcp搬到AWS S3上,之后通過Add Partition落地到Hive表里,接下來下游的EMR集群會對落地的數據做一些離線的ETL作業調度和Adhoc的查詢。整條鏈路中,數倉同學的痛點是Flink ETL作業上數據需要按業務分區動態寫入,但是各點位分區之間的流量非常不均勻。這就涉及到動態寫分區時候是否要加Keyby,如果加Keyby就會發生數據傾斜,不加Keyby每個寫算子的Subtask都會為每個分區創建一個Writer,而分區Writer又至少創建一個文件,同時 Flink Checkpoint 又會放大這個寫放大,最終導致小文件數爆炸。
小文件數多后會導致以下幾個后果:
- Distcp會變得非常慢,導致數據延遲在小時級以上。
- 流量小的很多文件集中在一個Task,導致查詢性能差。
(2)基于Iceberg的改良鏈路
Iceberg支持事務,我們可以利用這個特性來異步合并小文件,這樣既不影響主流的寫入又可以保障一致性,基于此想法我們可以得到以上的架構圖。
該架構簡化了落OSS 的步驟,Kafka數據可以直接通過Flink落到S3的Iceberg,之后異步執行合并小文件作業,此后下游就可以直接基于Iceberg做ETL調度。這個鏈路的問題在于:
- 異步的小文件合并為周期調度,但是Iceberg在commit之后,下游ETL讀文件作業會立即執行,在這之后再掛異步合并作業的意義就不大了。
- 如果同步合并小文件,即在Flink入湖作業中掛一個合并算子,這樣會引入跨云IO,并增加Flink作業的OOM風險。
所以我們還是決定通過加入Shuffle,從源頭解決數據傾斜的問題。我們自主設計了一個EvenPartitionShuffle的算法做數據Shuffle。Iceberg支持將分區級別的統計信息寫入到元數據中,這樣就可以拿到不同分區的流量分布,再根據下游的并行度,就可以將問題轉化為一個類背包問題,類似于Spark的AQE。
對于評估這個算法可以抽象出以下兩個指標:
- Fanout:下游Subtask的分區個數。
- Residual:下游Subtask的分配流量和與目標流量差距。
這兩個指標反映出小文件的個數以及數據傾斜的均勻程度,我們也在這兩個指標的評估下來不斷調整背包算法。從最終的效果來看,線上作業IcebergStreamWriter各Subtask數據負載還是比較均勻的,也極大減少了小文件數。
以上方案的優缺點如下:
優點:
- 小文件的問題得到了解決。
- Writer算子內存占用減少。
缺點:
- 引入了Shuffle。
- 流量動態變化。暫時還不能根據流量變化動態調整分區分布,因為當前是在Flink 作業啟動的時候讀取Iceberg的元數據。
(3)將基于Iceberg的鏈路應用于小紅書多云架構
當解決以上問題之后,讓我們來看看如何將以上鏈路應用在小紅書的多云架構上。有兩個問題需要解決:跨云流式讀寫的問題,以及Iceberg與下游系統的集成。
①跨云流式讀寫
關于Iceberg多云架構下讀寫的問題,我們先來看以上架構圖的組件與數據流。在上面的架構圖中高亮標出了Iceberg兩個比較重要的抽象:Catalog與FileIO。
Catalog保存了Iceberg最新的元數據的指針,并且需要保證指針變更的原子性。Iceberg提供了HiveCatalog和HadoopCatalog兩種實現。HadoopCatalog依賴于文件系統rename接口的原子性,而rename在對象存儲上并不是原子操作(對于最新版本的HadoopCatalog,加一個顯式的鎖可以保證原子性,但是當時還沒有這方面的實現)。所以我們選用了HiveCatalog,對于HiveMetastore,離線數倉包括Iceberg都是讀寫一個RDS庫,所以通過EMR集群的HMS也能直接訪問到Flink寫進來的Iceberg表。
FileIO是Iceberg讀寫存儲系統的接口。HiveCatalog默認是HadoopFileIO,我們可以在中間封裝一層S3AFileSystem來讀寫S3。當我們走完這條鏈路時發現Flink讀寫都是正常的,但是離線所依賴的EMRFS不支持S3A的Schema。于是我們調研了Iceberg原生的S3FileIO,發現它的實現非常簡單直接,且可控性非常高,于是在經過了一些大規模的壓測,并解決了一些問題后就選擇了S3FileIO。
首先Flink TaskWriter在接收數據向下游寫到S3OutputStream。用戶可設置一個MPU閾值,當大于閾值時,會有一個線程池異步地使用MPU上傳文件到S3,否則就會走另一條路徑,將StagingFiles串在一起,通過PutObject請求寫到S3。
對于以上鏈路,我們也對S3FileIO做了一些優化以支持大流量的作業。
(1)S3Client上的優化:
- HttpsClients,我們將S3原生的HttpsClients(Java8自帶的HTTP URL Connection)更換為了Apache HttpClient,其在Socket鏈接以及易用性上有一些提升。在寫的過程中我們也遇到了一些問題,多云機器帶來的問題是每個廠商機器的內核是不太一樣的,例如在某云上發現有寫S3超時的問題,我們與廠商一起抓包發現是內核參數的問題。
- API Call Timeout,將S3的Timeout配置項暴露給Iceberg。
- Credential Provider,S3 SDK從FlinkConf中讀取密鑰。
(2)MPU Threshold
Flink做Checkpoint的時候,所有的Writer都會將數據刷到S3,這時候的毛刺會非常大。我們的方案是降低MPU的閾值以及ParquetWriter的RowGroup。降低Parquet的RowGroup就意味著它刷到S3OutputStream可以更早一點,降低MPU閾值就可以更早地上傳StagingFile。通過以上優化我們把CheckPoint在上傳到S3的延遲中從2分鐘降到了幾十秒。
(3)ResetException
當S3OutputStream通過BufferedInputStream把兩個StagingFile合并到一起并上傳時,當遇到諸如網絡問題時會重試,它重試的機制是通過InputStreaming的mark和reset來做的,但是默認的mark limit是128KB,BufferedInputStream超過128KB之后就會丟數據,重試時就會出現ResetException。我們將mark limit改成 StagingFiles Size +1,保證所有的數據都會緩存避免以上問題。
②下游系統集成
接下來要解決的是跟下游生態系統集成的問題。
- 第一個問題是Batch Read
Iceberg與Hive最明顯的區別就是分區的可見性語義,Hive在整個分區寫完后可見,而Iceberg在commit后就立即可見。但是下游離線調度的小時級任務比較依賴于HivePartition的可見性。
在此我們做了一個Sensor,其原理是Flink在寫的時候將Watermark寫進Iceberg表的Table Property。下游的離線調度就可以使用我們基于Airflow的Watermark Sensor去定期的輪詢HMS,查詢Watermark是否已經達到分區時間,條件滿足之后就會觸發Spark的調度。
- 第二個問題是Adhoc查詢
Adhoc查詢使用了Kyuubi這樣一個多租戶的SQL Gateway通過Spark去讀Iceberg表。用戶可以直接通過三段式的表名去查詢Iceberg 表,例如:
hive_prod.Iceberg_test.table
總結:
我們目前在生產環境已經落地了幾個比較大的作業,單作業的吞吐達到了GB/S以及百萬級別的RPS,數據的就緒時間大概在五分鐘左右,由Flink Checkpoint來控制。下游的讀耗時得益于小文件問題的解決以及Iceberg基于文件的Planning,使下游讀耗時減少了30%~50%。
02 CDC實時入湖
1. Mysql全量入倉
小紅書數倉數據的另一重要來源是MySQL,目前的Mysql2Hive鏈路是全量入倉這種比較傳統的模式,主要通過Airflow定時調度,使用Sqoop去小時級別或天級別從MySQL拉數據寫到Hive表相應的分區里面。
其中比較特殊的一點是為了解決Schema Evolution,每次拉取數據的時候都會生成一個Avro Shema,對應的Hive表選用了行存儲的Avro表,而不是通常會使用的基于列存的Parquet文件的表。它的缺點是不如列存高效,但是它解決了一個問題——下游的用戶不需要考慮schema變化的情況。這條鏈路的好處是簡單實用直接,缺點是MySQL壓力大,下游查詢不夠高效。
2. CDC增量入倉
關于CDC如何增量入離線數倉的問題,大廠都有一些比較成熟穩定的方案。
如上圖, ODS一般有兩張表,一張增量表一張全量表,開始會有一個全量表的導入,之后會通過實時流進增量表,然后通過Merge任務進行周期性的合并操作。這個鏈路已經在很多廠都有了成熟穩定的實踐,缺點是鏈路比較長。
3. CDC實時入湖
我們最終的鏈路如上圖,將MySQL的上游數據庫通過全增量數據發送到Kafka,然后使用Flink將數據Upsert到Iceberg里面,同時會處理一些Schema Evolution的情況,這條鏈路就非常簡潔。
整條鏈路中我們需要特別注意,同?主鍵(業務主鍵+ Shard Key)的Binlog應該保序。以下是在整條鏈路中保持Exactly-Once語義所做的事情:
①Binlog
- 全增量,先發全量再發增量。
- At-Least-Once,保證重復發送時保證有序(最終?致性)。
- MQ Producer根據主鍵Hash(且分桶數固定,不受擴容影響)。
②Flink
- Shuffle Key 只能是主鍵的?集 + Immutable Columns。
③ Iceberg sink
- Upsert Mode。
(1)Merge on Read
這個方案我們在實踐中也發現一些問題,最核心的就是DeleteFile多導致的MOR查詢性能差。
Iceberg查詢時,每個DataFile都需要讀取相應的DeleteFile進內存進行過濾,會使得Task的IO負載很重,這樣我們的優化思路就轉換為如何減少DeleteFile。而出現DeleteFile過多的原因是,Update的實現要先把當前行刪掉再Insert,刪掉這行就至少會生成一個DeleteFile。我們對此所作的優化是去除重復的Insert事件,這樣只需要對Update做Delete。當下游Insert很多,Update很少的時候就會有比較大的收益。
(2)Hidden Partition
Iceberg的分區與Hive不同的是它的分區信息可以被隱藏起來,不需要用戶去感知,在建表或者修改分區策略之后,新插入的數據自動計算所屬分區。
利用隱藏分區我們可以做到以下優化:
- 在讀數據時可以只查詢關聯分區,忽略其他分區。
- 錯峰做File Compaction,減少沖突。例如在寫當前小時分區時我們可以對之前的分區做File Compaction。
對于FlinkSQL原生不支持隱藏分區的問題,我們通過Table Property去定義隱藏分區,在建表的時候去建相應的分區。
(3)Auto Schema Evolution
在實時流處理Binlog,一個繞不開的問題是上游的Schema變更了下游怎么及時的檢測到,再去做相應的Writer的變更,下游表的變更。有一種解決方案是當消費到上游變更的Event事件時,我們會在平臺把作業重新改掉重啟,也就是先變更下游的Iceberg的Table Schema,再變更Flink SQL,之后重新啟動作業。但在平臺化之前,對于一些常用的場景,比如加列,已經能覆蓋線上很多Schema Evolution的場景。為了讓Flink作業能自動監測到加列并且有序的正確的提交到Iceberg,我們將Binlog中的Schema隨著每條數據記錄一起發送,當數據往下發到Iceberg的Dynamic Streaming Writer時,就可以和Writer里面保存的上一個Schema去做比較,假設只是加列,那么我們就會做兩件事情:
- 關掉當前的Writer,以新的Schema去建立新的Writer寫數據。
- 以Schema變更的時間點為分割,對Schema變更前的數據先提交,再對Schema 進行Update,之后再提交 Schema變更后的文件。
(4)CDC實時入湖其他工作
除此之外,CDC與實時鏈路我們還做了其它一些工作:
- Binlog Format。支持解析Canal PB格式。
- Progressive Compaction。Compaction是我們接下來工作的重點,尤其在MySQL的量比較小的時候,如果想維持五分鐘級別的CheckPoint,小文件問題就會非常突出。如何避開流式任務正在寫的Partition去做Compaction 也是目前在做的事情。
以上就是我們目前正在做的CDC入湖的一些工作。
03 實時湖分析探索
我們想用Iceberg 來做一些更面向未來的事情。
1. 實時分析鏈路
首先介紹一下目前分析的實時鏈路。
Kafka通過Flink做一些Join和聚合操作之后,最后會生成一張大寬表存儲到ClickHouse中以提供秒級或者毫秒級的返回功能,Kafka在其中也用做了事實表的存儲。以上架構圖來自FLIP-188,FLIP-188要做的事情就是如何實現流批一體的存儲。我們數倉同學的需求是要對中間結果進行一些查詢操作或者利用其進一步生成下游的表,這些操作只利用Kafka是做不了的。常見的做法是利用Kafka再接一個任務,將中間結果寫到Iceberg或者Hudi表里面。
2. 流批一體存儲
我們實現流批一體存儲是通過直接在Kafka里雙寫一份數據到Iceberg的列存儲上。這除了讓Kafka做擴容更簡單,更重要的是支持一些離線數倉的用法,我們不必再啟動一個Flink的作業去寫到S3。要實現這樣的功能首先需要一個Schema的概念,也就是如何把Kafka的Schema映射到下游表的Schema,對此我們讓用戶在我們的平臺上來自定義,同時有一個Remote Fetcher模塊來拿到這個Schema,之后通過Iceberg寫到下游。真正的寫線程是在Broker里面,可以根據Leader去動態遷移。之后集群中的Controller節點上啟動一個單獨的Commiter進程,接受Fetcher傳來的數據文件列表,定期commit。
3. Iceberg外表
ClickHouse社區版是存算耦合的,離線數倉想用這部分的數據就比較困難。我們公司內部的ClickHouse已經實現了存算分離的架構,數據是存儲于對象存儲的。在此基礎上,我們和ClickHouse團隊合作做了Iceberg的外表。Iceberg外表沒有使用Paruqet這種開放式的文件格式,而是使用了MergeTree的格式。上圖是一張Iceberg傳統的數據文件組織形式圖,它的Metadata層分成了Manifest List和Manifest File,之后會指向一些DataFile。這些DataFile與ClickHouse里面的part概念很像,所以我們就將Manifest File指向了一個part.ck文件,part.ck其實也是一層衍生的元數據文件,它的下游會再去讀一些bin/mark的文件,這樣就可以完成對ClickHouse數據的讀取。
04 未來規劃
未來規劃主要有存、算、管三個方向。
- 首先在存儲方面,我們需要對CloudNative FileIO持續優化,比如進一步減少Checkpoint的毛刺、進一步提高吞吐、提高跨云讀寫的穩定性。
- 關于計算,我們會跟更多引擎去集成,目前已經集成了Spark引擎,同時正在集成ClickHouse。另外StarRocks社區已經集成了Iceberg外表的Connector,我們以后也會在上面做一些應用。在查詢方面,計劃通過改變數據的組織形式,或者添加一些二級索引來做Data Skipping去加速查詢。
- 管理方面,讓Iceberg持續穩定的運行下去還是需要外掛表維護作業的,這對下游數倉同學來說還是引入了運維壓力。我們接下來會將其服務化,思考如何智能地拉起一些作業,以及運用什么策略可以減少沖突的概率。
這就是我們正在做的和將來準備做的一些事情。
編輯:王菁
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
linux操作系統文章專題:linux操作系統詳解(linux不再難懂)