揭秘AI芯片創新風向!清華北大中科院專家同臺論道,如何突破性能瓶頸?

編輯 | 漠影
芯東西6月7日報道,在上周舉行的2022北京智源大會芯片前沿技術論壇上,來自清華、北大、中科院等科研院所的多位專家學者分享了AI芯片在存算一體、跨層優化、軟硬件協同設計等方面的前沿技術創新思路。清華大學教授、清華大學集成電路學院院長吳華強解讀了憶阻器存算一體芯片所面臨的挑戰;北京大學信息科學技術學院長聘副教授、博雅青年學者梁云分享了可用于降低軟硬件開發門檻的智能芯片設計工具;清華大學電子系長聘教授劉勇攀從“算法-架構-器件”協同優化的角度探討“分久必合”的芯片設計如何提升性能;中國科學院計算技術研究所副研究員、智源青年科學家杜子東聚焦AI訓練,提出支持高效量化訓練、精度損失可忽略不計的架構。面向產業落地,AI芯片公司昆侖芯科技的芯片研發總監漆維亦分享了其團隊在十年耕耘期間所觀察和總結的AI芯片大規模落地的4個挑戰。芯東西對論壇中的干貨內容加以梳理,與讀者共饗。
01.清華吳華強:憶阻器存算一體芯片興起,三大挑戰解析

▲吳華強
對于AI算法而言,“存儲墻”正成為主要的計算瓶頸,數據搬運會消耗大量功耗和時間。目前AI算法在一部分云計算里算子比較集中,因此與憶阻器陣列有很好的契合度。基于憶阻器等類腦計算器件的存算一體架構,學習了大腦工作機制,通過模擬一些突觸乃至神經元的功能,成為突破“馮·諾伊曼”瓶頸的最有潛力的技術路線之一,有望大幅提升算力和能效。憶阻器具有電阻可調特性,也可以解決很多傳統模擬計算的參數難以配置的問題,它的出現,使得“存算一體+模擬計算”的新計算范式興起。吳華強教授重點解讀了憶阻器存算一體芯片面臨的三個挑戰:1、如何真正克服比特誤差對系統誤差的影響?過去數字計算首先是比特精確,比特精確至少要保證系統精確。在基于憶阻器的模擬計算里,每個比特相對來說有一個range,個別比特可能完全不準。如需將每個比特都做得很精準,則能耗變高,能效會受影響。對此,解決思路一方面是從數學模型去驗證它們的誤差關系,另一方面從算法上進行挑戰,根據實踐,如果直接復制數字計算的算法,往往得到的效果較差,而在這之中進行微調,尤其對底層設備、對分布規律的理解會有很大的幫助。吳華強團隊提出由片外壓力訓練和片上自適應訓練組成的混合訓練框架,在片外壓力訓練中引入系統誤差模型,構建具有誤差耐受性的網絡模型,提升實際硬件系統的精度。在權重映射到芯片后,通過原位更新關鍵層權重進行自適應訓練,進一步提升精度。2、如何高效、低成本的設計并制造出憶阻器存算一體芯片?吳華強給出的解法是:CMOS嵌入式集成+EDA工具鏈。芯片走向更大規模,需要器件進一步優化結構。從2010年至今,其團隊制作憶阻器件的過程分了幾個階段:第一階段,用2μm工藝在實驗室中篩選CMOS兼容材料,制備單器件;第二階段,130nm工藝,打通后端集成工藝,發展了Foundry+Lab模式,最多集成到64M的憶阻器;第三階段,與聯電新加坡廠、廈門聯芯、中芯國際等大的代工廠合作,從40nm到28nm、22nm,可完成整個工藝的加工。其團隊還研發了從器件仿真、電路模塊設計到系統架構設計的EDA工具鏈,目前已將EDA工具鏈跟兩款工業芯片進行適配。此外吳華強透露,他們有計劃將EDA工具鏈開源。3、如何提升存算一體架構的通用性,使其適配更多的神經網絡算法?吳華強團隊研發的軟件工具鏈包括編譯器、軟件模擬、硬件模擬器等,通過軟件工具鏈實現算法和芯片硬件的解耦,可支持各種神經網絡算法。其中,編譯器對接算法層,可實現存算一體計算單元上高效部署神經網絡算法及生成可執行程序的功能;軟件模擬對接著編譯器和算法層,結合底層硬件模型,考慮真實器件的非理想因素,實現對真實硬件功能與性能的評估與探索;硬件模擬器對接編譯器,功能完整的計算單元模塊,模擬存算一體SoC工作過程中的數據信號與控制信號變化情況。在芯片方面,吳華強團隊在研制一款采用28nm制程工藝的集成憶阻器存算一體芯片,集成規模達到64Mb,數模轉換精度達8bit,預期算力超過100TOPS,預期能效超過10TOPS/W,具備一定通用計算能力,功能可重構、參數可配置,并有配套軟件工具鏈。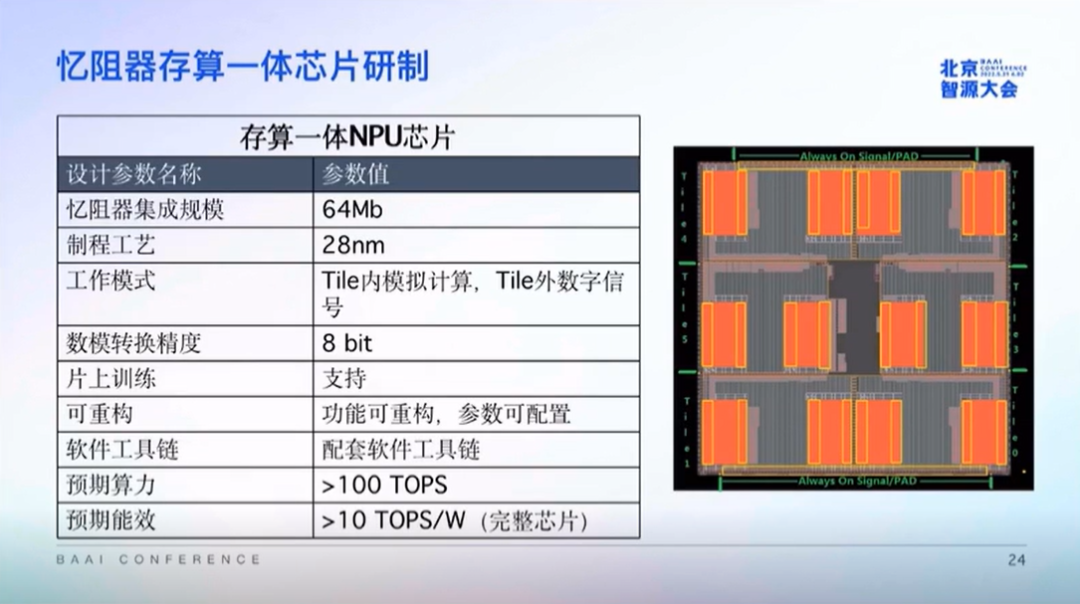
02.北大梁云:軟硬協同設計工具,降低智能芯片開發門檻

▲梁云
在他看來,摩爾定律停滯不前以及功耗限制,需要架構方面的創新,領域專用處理器(DSA)是一種可能的解決方案。DSA有多種優勢,從硬件角度,可以做更高效的并行設計、內存架構、數據表示形式;從軟件角度,可將復雜的編譯器變簡單。最近幾年,梁云主要關注的是張量(Tensor)計算。由于張量計算的重要性,許多廠商設計了采用Spatial空間架構的AI加速器,這種架構并行性和數據復用率很高,但也存在一些挑戰:一是如何做軟硬件協同設計,二是決定了硬件架構后如何實現?總結下來,整個軟硬件設計流程都需要非常底層的編程,而且很難優化,開發周期漫長。梁云所在課題組提出了一種軟硬一體的智能芯片設計與優化框架AHS,希望借助高層次的抽象、自動化工具和高效的算法,自動生成芯片的硬件架構和軟件算子庫,降低芯片軟硬件開發門檻。具體來說,其課題組通過設計領域專用語言和中間的表示形成降低編程門檻,借助機器學習算法讓優化更容易,設計這種自動化的工序來解決人工設計的問題。其工作包括硬件綜合、軟件編譯及軟硬件協同設計,每個組件均已開源。硬件綜合方面,其TENET框架可使用基于關系的表示形式,涵蓋硬件數據流的設計空間,能夠進行一系列的數學分析,分析出重用、延遲等跟性能相關的各種指標,從而幫助用戶在某些限制條件下找到更好的芯片設計。同時,該團隊提出了可在性能、生產力和支持的數據流上都取得最優的工具TensorLib,并為實現自動生成硬件構建了相應的EDA工具。軟件編譯方面,團隊提出了針對不同硬件的統一抽象,核心想法是將形式多樣的intrinsic在語義上降低到一個scalar program上,接下來把它形式化一個基于布爾矩陣的映射過程,在這里面通過檢查布爾矩陣來檢查映射方案的合理性。經實驗,其在單個算子和整個網絡上均實現大幅度性能提升。軟硬件協同設計方面,該團隊提出一種敏捷的協同設計方法HASCO,它基于新的數據結構張量語法樹做軟硬件的劃分。在硬件方面,其借助貝葉斯的優化做硬件優化和設計空間的探索;在軟件方面,引入強化學習,能快速找到所需軟件設計的參數。與非軟硬件協同設計的工作相比,其在邊緣場景和云計算場景的實驗結果在能效、性能方面均有一定的提升。03.清華劉勇攀:高能效AI芯片設計“分久必合”

▲劉勇攀
隨著摩爾定律的放緩,“通用計算架構”+“工藝器件進步”相結合的性能提升之路,面臨日益嚴重的挑戰。制程工藝演進到28nm后,如果在傳統小容量的芯片市場,其容量沒有增加,專門為它做一個芯片,實際成本并未下降,這打破了摩爾定律以更便宜價格來提供更高算力的假設。過去“分而治之”的芯片傳統設計分層架構,好處在于有一個系統觀的架構師將要做的事拆分成若干層,大家各做各的,高效協同,從而提供更低的設計復雜度和更高靈活性。但隨著這個組織發展到一定程度,其代價是整個頂層執行效率的下降,此前的架構反而成為算力、能效提升的瓶頸,這就需要重新打通邏輯、重新定義層次,這對我們來講是很好的機會。劉勇攀認為,未來,在底層器件發展變慢的情況下,我們可能需要使用“分久必合”的跨層次協同模式,發揮一些從應用層面的新設計融合邏輯,不但要做算法和架構,還要做電路與器件的協同,來研發出高能效、高性價比的AI芯片。一個算法級稀疏可獲得10到30倍的理論加速,而真正到了通用的GPU、CPU層面,可能只有9到25倍的加速,如果做一個稀疏架構,就能很好發揮出稀疏算法的架構優勢,這便是典型的算法架構融合邏輯。器件方面,稀疏也好,低比特推理和訓練也好,都是從算法和架構上的優化。自下而上也有器件和電路的融合,包括先進工藝的DTCO(設計工藝協同優化)。現在有一些SRAM面積提升,并不是通過把某個管子做小,而是垂直堆疊起來,密度可能提升了幾倍、百分之幾十,這就是典型的先進工藝的DTCO。還有HBM、3D堆疊,這都是從存儲層面,未來可能會有更大容量、更高速的訪存、更低成本的片上存儲,以及更接近計算的HBM內存,這些內存將很大程度上解決未來計算中部分存儲帶寬的問題。另一個層面,這些器件電路不但可以做存儲,還能提升計算密度,可以做存算一體,甚至可以用光互聯,NVM(非易失存儲器)的計算堆疊實現更高性能、低功耗、低成本的計算。可以看到,設備和電路的協同設計前景巨大。最后,劉勇攀總結了對該領域的3點觀察:其一,做AI計算,可將原始算法變成硬件高效的AI算法,從而使能效和算力得到顯著的提升。其二,芯片或系統有按比例縮小(scaling down)和異構集成兩條路線,異構集成使我們能將更多DSA融合做一個整體解決方案。由于是芯片級集成,它不會受限于SoC要求的大的市場容量成本的問題。隨著一些新型封裝技術成熟,業界現已出現芯粒異構集成的方式,通過靈活互聯,打破過去單一器件和同構計算架構的帶來的局限。這些芯粒可以采用不同的工藝節點,從而繼續提升性價比,并一定程度上縮短設計周期,這為新型器件和領域定制化異構架構創新開辟了廣闊空間。其三是新器件。現在還處在相對萌芽期的光通信和光計算,未來有可能被集成到大算力AI芯片中,甚至是更遙遠的量子技術里。04.中科院杜子東:定制架構支持高效量化訓練,精度損失可忽略不計

▲杜子東
量化被認為是有望降低帶寬/存儲要求、提升效率、降低計算成本的有效手段。過去采用低比特或量化推理方面的應用很多,但在開銷巨大的深度學習訓練中,量化應用相對較少。現有的量化訓練算法相關文章常常采用16bit,少部分可做到8bit,其量化效果通常只有部分數據能做到8bit,大部分數據還需16bit、32bit,對于像CPU/GPU等平臺沒有加速效果。杜子東團隊也在GPU上實現了一個量化訓練,相比32bit,直接在CPU+GPU平臺做量化訓練,會比平常慢1.09倍~1.8倍。在訓練中,GPU并不能給予很好的硬件和軟件的支持,也沒有特別好的低位寬的高效深度學習算法,這是現在阻礙量化訓練的兩大因素。量化算法需對大量數據進行基于動態統計的量化和高精度的權重更新,這使得這些量化訓練算法不能有效地部署在當前的深度學習處理器上。對此,杜子東團隊提出了第一個用于高效量化訓練的定制神經網絡處理器架構,其訓練精度損失可忽略不計。其團隊提出了3個策略來解決上述問題,一是局部量化,二是基于誤差估計的多路量化,三是原位權值更新。通過將這三點應用于AI加速器上,在硬件中做針對性地支持,使之能做在線量化訓練,并避免了多變的數據訪問,相對同規格TPU實驗,其性能提升1.7倍,能效提升1.62倍。05.昆侖芯科技漆維:AI芯片大規模落地,直面哪些挑戰?

▲漆維
昆侖芯1代采用14nm制程,在百度搜索引擎、小度等業務中部署超過2萬片,經歷過互聯網大規模核心算法考驗的產品。昆侖芯2代采用7nm制程,于2021年8月量產。其4nm昆侖芯3代已啟動研發,昆侖芯4代也在規劃中。在演講中,漆維分享了AI芯片在走向產業大規模落地過程中所面臨的挑戰:首先是算法的多樣化。不同業務場景有不同的算法模型,即便是同一個業務線,其算法也在持續優化和突破。如谷歌曾在TPU論文中提到等芯片研發完成、要推到業務端落地部署時,才發現業務團隊兩年前所提的模型和精度需求已被推翻。第二,這個賽道并不是一個藍海,因為有行業巨頭NVIDIA在前面。NVIDIA已有10多年的積累,構建了非常強大的護城河,并敢于對自家架構做持續創新,其GPU已跟所有的主流框架做了適配。這種情況下,客戶對于為什么要選到你的AI芯片是有心理防線的,因此不僅要做到有一個非常可觀的實際性能收益,也需要整個軟件棧做到非常靈活,實現盡量小的成本。第三,客戶的需求并非一成不變,且非常嚴苛。以互聯網為例,他們并不會關心一個單一指標,他們關心延時、吞吐、TCU,這些指標很多時候是糅合在一起的。例如,客戶可能關心其業務在滿足一定延時條件下,到底單卡能給他帶來的吞吐是多少,甚至有時還會加一些限制,如要求其CPU或者整個AI芯片、GPU限制在一定程度的利用率,去確保整個業務系統的魯棒性。最后,能夠在真正場景中做到業務規模的量化,整個軟硬件系統都將面臨非常大的工程挑戰。硬件產品做到萬級、十萬級甚至更高時,穩定性怎么樣,成本對業務來說是不是可接受的;整個軟件棧要適配不同的深度學習框架、處理器、操作系統以及不同OEM的不同機型等等。到業務實際部署環節,有時不是單行程的業務在跑,而會為了把利潤率做高,可能會做多行程的混部。在這種場景下,整個AI卡實際性能能否做到很穩定,都是走向芯片量產后要面臨的工程化挑戰。針對上述挑戰,昆侖芯的發展分成了兩個階段:第一個階段是2011~2017年,主要基于FPGA開發集群,隨后因底層硬件存在種種限制,FPGA在業務形態及架構上遇到瓶頸,致使相應性能和功耗等指標很難達到最優,因此大概在2017到2018年,也就是AI發展相對成熟之際,昆侖芯團隊開始轉型,并于2018年正式啟動昆侖芯的研發。從FPGA到昆侖,昆侖芯團隊對整個芯片的架構做了抽象,從早期一些偏靜止的優化做成一個通用的設計。之所以要做通用的AI處理器,一則為靈活支持更廣泛的應用場景,二則需要靈活可編程以適應各種業務的需求,三則盡可能降低芯片、軟件以及對業務牽引的成本。在漆維看來,現在是一個很好的時代,信創國產化等趨勢給了AI芯片一個良機,有一批早期用戶愿意接納和嘗試你的產品,而從早期客戶到主流客戶中間有一條鴻溝,什么時候真正邁過這個鴻溝,AI芯片產品才真正在市場上站住了腳。06.結語:砸錢堆算力,堆不出AI芯片的未來
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

伺服電機相關文章:伺服電機工作原理