人工智能介入芯片制造流程

文︱LAURA PETERS
來源︱Semiconductor Engineering
編譯 | 編輯部
受到芯片短缺影響,晶圓廠和OSAT紛紛加大產能建設,并評估將人工智能和機器學習介入芯片制造,能否帶來更大的效益。
尤為重要的一點是,鑒于市場分析師對市場增長的預期,預計未來五年內,芯片制造業的市場規模將翻一番,工廠、人工智能數據庫和工具的整體改進對于提高生產率至關重要。
“我們不會在數字化轉型中失敗,因為別無選擇,”Inficon負責智能制造的總經理John Behnke表示。“所有晶圓廠的產能都將提升20%至40%,但現階段,在18到36個月內,他們都難以獲得新工具。為了充分利用這些潛力,我們將克服人類對變革的歷史恐懼。”
此外,這種變化需要有明確的投資回報率。“對我來說,一切都歸結為成本,”人工智能驅動的APC軟件的初創公司Sentient的首席執行官Abeer Singhal指出。“我們為什么要將數據遷移到云中?因為我們希望它是可訪問、可計算的。即便有下載、存儲和計算成本,但工程師希望擺脫為所有事情調用IT的現狀。他們希望收集高頻數據,同時做出明智的決策。”
其中一個重大挑戰是高度規避風險的制造業,該部門通過大部分漸進式改進取得了顯著收益。“半導體行業有很多技術類型的進步,但我們通常在進行業務變革方面非常緩慢,”數據庫供應商KX Systems半導體和制造副總裁Bill Pierson認為。“部分原因是因為你在一個已經建成的工廠里,它正在運行并獲得高產量,所以為什么要改變它呢?但是,我們看到自上而下的管理策略是試圖打破數據孤島,確保所收集的數據將提供給所有必要領域的工程師。”
其他人則指出了類似的趨勢。“人們輕易不會做出改變,”納米生物科學負責人兼紐約州立大學理工學院教授Scott Tenenbaum表示。“新冠疫情是一個很好的契機,人們嘗試了他們永遠不會嘗試的事情,除非他們必須這樣做。我們的很多技術都是這樣的。舊技術消失了,你別無選擇,只能使用新技術。”
在SEMI先進半導體制造大會的小組討論中,與會者指出了涉及AI/ML和全球晶圓廠的10個趨勢或建議:
到2025年,半導體領域的AI/ML將達到1000億美元;
工程師在調度和缺陷分類方面的成果唾手可得;
數字孿生和分析正在實現預測性維護;
非增值步驟可能會被跳過、縮短或移動;
晶圓廠現在正在招聘數據工程師;
大數據很好,但正確的數據更好;
工具狀態標準(SEMI E10)有助于透明度;
ML在測試平衡良率、缺陷、測試成本;
投資回報率承諾克服了行業的不情愿;
必須內置數據庫安全性。
SE:麥肯錫最近的一份報告顯示,人工智能和機器學習產生了約50億至80億美元的芯片收入,約占設備總收入的10%。預計到2025年,這一數字將增長到1000億美元左右。你同意這個估計嗎?
Behnke:顯然,我們可以看到AI、ML等技術在半導體制造中的廣泛應用,為半導體行業產生了15%以上的價值。這不認為這意味著它會產生另一個行業,晶圓廠撐起了950億美元的市場份額,但利用先進技術能力,晶圓廠在未來五年內將至少能夠再擴大950億美元。
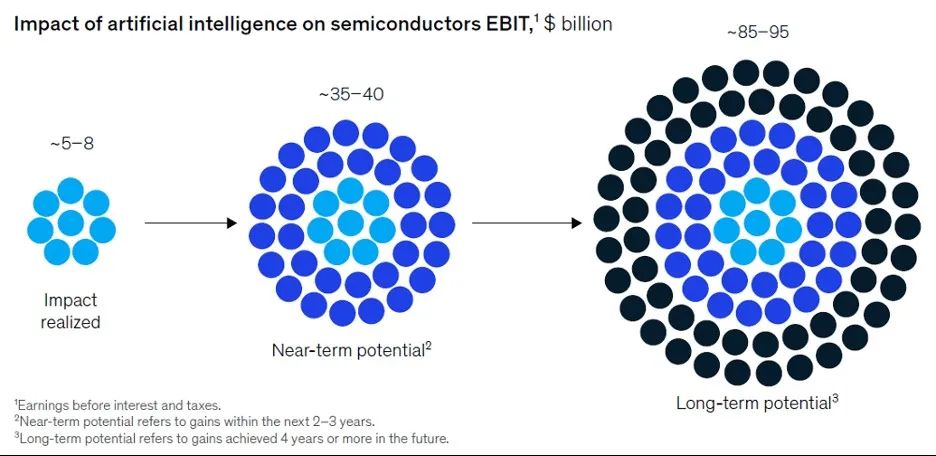
半導體領域的AI / ML在2021年創造了70億美元的價值,占芯片收入的10%,預計到2025年將上升到設備收入的20%達900億美元(圖源:麥肯錫公司)
Pierson:我們正試圖通過提高這些工程師的勞動力來提高晶圓廠的生產力并降低成本。勞動力是其中的關鍵部分。
SE:關于這一點,在晶圓廠中采用AI/ML將會得到哪些唾手可得的成果?
Singhal:大數據和人工智能算法代表了APC工程師的范式轉變。與過去相比,如今可以在幾分鐘內構建復雜的流程模型。例如,AI輔助運行到運行的控制器可以提取內聯SPC數據,將其與100多個FDC和良率指標相結合,以提供對系統運行狀況的洞察并提出改進建議。
另一個 AI 用例是構建自適應工具狀態模型,以防止計劃中或計劃外的工具事件過多的提前發送。人工智能的潛力是無窮無盡的。
Behnke: 到目前為止,晶圓廠投資回報率最高的應用是調度。工具必須在六個月或更短的時間內提供價值,包括ROI、周期時間改進或其他KPI。因此,智能制造很大程度上是采用工程師幾十年來一直在工作的環境以及豐富的歷史數據,升級這些環境來創建一個數字孿生體,這有點像類固醇上的模擬器,使用計量學和傳感器以及其他數據源,使得孿生體的信息實際上具有更高的保真度和對工廠的理解。這種數字表示會查看當前事件和選項,通過基于ML的歷史學習利用其具有的價值,并快速確定下一步應該做什么。顯而易見的是調度。我應該在什么工具上放什么批次,以什么順序?更重要的是,應該設置工具來做什么?這適用于APC,FDC 2.0(故障缺陷分類)等。如今,芯片制造商擁有在晶圓廠層面實現這一目標的工具,真正令人興奮的是,在五年左右的時間里,公司內的所有工廠都利用這些工具,從晶圓廠到組裝和封裝。
Singhal: 客戶希望從呼叫IT處理所有事情的麻煩中解脫出來。這是將所有內容推送到云的重要驅動因素。但他們也希望能夠以每秒100千兆的速度下載。因此,我們談論的是帶寬,這是有成本的,存儲數據并使其可用。對于目前芯片的發展趨勢,這些芯片專門設計成能夠在芯片上集中處理信息,而不是在一起工作的不同系統中。
高級算法可使用可操作數據處理歷史數據,以便在決策價值最高的情況下實現實時決策(圖源:Gartner)
SE:半導體短缺對芯片制造有何影響?
Behnke:當今社會與過去完全不同,所以人們現在明白,我們需要開始更聰明地做事。高管與董事會都參與其中,他們承受著巨大的壓力。在新的董事會會議記錄中,他們被問到,“你的智能制造戰略是什么?這在兩年前還沒有爆發疫情的時候是聞所未聞的。”
Pierson: 我們正在轉向以數據為中心的世界,我看到的變化之一是一級芯片公司都擁有這些所謂的數據工程師團隊。他們不是數據科學家,也不是主題專家。他們是數據工程師,負責整個組織并為整個組織中的人員準備數據以供使用。隨著這種數據爆炸的發生,需要認識到,對這個定義的角色有很大的需求,人們需要認識到需要格式化數據。大多數數據都有一個時間戳,所以也許我們可以索引時間序列。
SE:特別是對于傳統晶圓廠來說,學習曲線是什么樣的?
Pierson: 這是一個旅程,有些公司比其他公司更先進。一些工程師可能使用鉛筆和紙墊,他們只需要能夠存儲數據并想要一個儀表板。這是旅程的早期部分。有些人正在談論做數字孿生體并在整個工廠擴張。這個旅程將繼續下去,對我們的工作方式進行評分將需要5到10年的時間。每個晶圓廠都是不同的,你必須在他們所在的地方與他們見面。
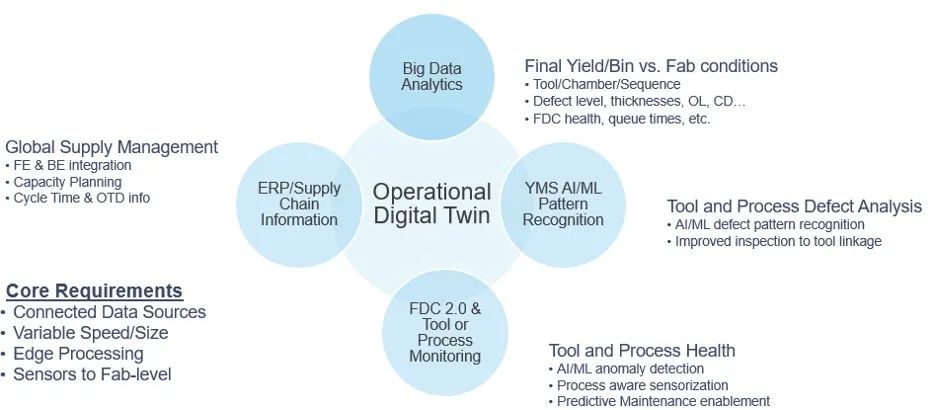
工廠運轉的各個方面都可以利用以數字孿生為基礎的數據處理和分析(圖源:Inficon)
Behnke:對于更多可能性的探索是人工智能其中一個很大的優勢。人工智能不只是獲取某個參數,而是會獲取每個參數和每個組合。人工智能的功能很強大,據我所知,沒有人能做到這一點。現階段,智能終端搭載了越來越多的傳感器,因此系統將越來越智能。而AI是我們遇到的最好的技術,可以捕獲任何無法通過肉眼識別的信息。
Tenenbaum:然而相應地,人工智能普遍被過度炒作。人工智能在針對大規模數據集的識別方面極具優勢,但它不太擅長識別隨機事件。以用于預測股市的人工智能技術為例,在基于專業交易者時,這項技術運作良好。但對于業余交易者和“羅賓漢”,或對于通配符和比特幣,該技術在數據分析方面則表現不佳。因此,當你談論如何讓人工智能介入產品制造時,人工智能技術在對可預測事項的預測中很有優勢。但是,同樣代價高昂的一次性事件,對于人工智能來說則非常具有挑戰性。
SE:當行業轉向300mm晶圓時,各公司之間進行了更加密切的合作,并制定了SEMI標準。你看到這里發生了什么?
Behnke:行業內制定了E10標準,即SEMI E10設備可靠性、可用性和可維護性規范。通過這一規范,可以更好地跟蹤模塊化系統中的工具,以提高利用率。現階段,該規范并沒有得到那么廣泛的報道,但業界已經有一些企業開始采用。隨著這些解決方案的推進,這將是一個很大的幫助。
對晶圓缺陷的高度關注給減少非增值步驟帶來了很大的壓力,特別是晶圓和器件的計量和測試。在半導體測試領域,為了確保檢測可能影響可靠性的潛在缺陷,系統級測試的應用需求越來越旺盛。
“像Nvidia、AMD和Intel這樣的領導者已經這樣做了多年,但最近公司一直在更快地進行更多的系統級測試,以對內存和其他測試進行功能測試,”Advantest的Dave Armstrong表示。“他們發現兩個教學測試是不夠的,所以他們需要做高速測試,以確保一個已知的良好的小芯片。”
對額外測試的需求很大程度上是由潛在缺陷問題的新知識驅動的,這些信息是通過學習平臺獲得的。“高級數據分析提供了對異常值檢測的洞察,并指導我們進行測試儀和測試程序設計,”Armstrong稱。
半導體測試也從切割大量測試數據的能力中受益匪淺。大型測試設施每天可生成高達4TB的數據,這些數據用于反饋過程,以提高產量和質量。
Teradyne運營高級副總裁Ken Lanier指出,測試儀上的多個傳感器還可以監控芯片的電壓、溫度和其他參數,這些參數與機器學習一起可以實時修改測試過程。
“由于測試是發布到生產環境之前的最后一步,因此在幾周內調試大量軟件程序和測試模式數據的壓力很大,因為編程錯誤可能導致IC生產商丟棄數百萬美元的好設備,或者更糟糕的是,運送壞設備。在良率、缺陷率和測試成本之間進行權衡,需要對設計仿真、測試程序和機器學習工具進行大量投資,以識別最輕微的異常,標記測試設備上的問題并縮短調試周期,“Lanier表示。
展望未來,數據安全是另一個需要解決的問題,因為它是數據共享的障礙。“這些數據庫需要是非常安全的環境,因為沒有人愿意出于IP原因共享數據,”Inficon的Behnke表示。“沒有人愿意共享數據,因為他們還擔心安全方面的問題。”
半導體行業正在努力保護自己的片上數據,但它也在擴大這一努力,將電子系統和數據庫納入其工廠。這可能需要時間,但它被視為必要的步驟,因為孤島被打破,數據跨越傳統的分界線。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。









