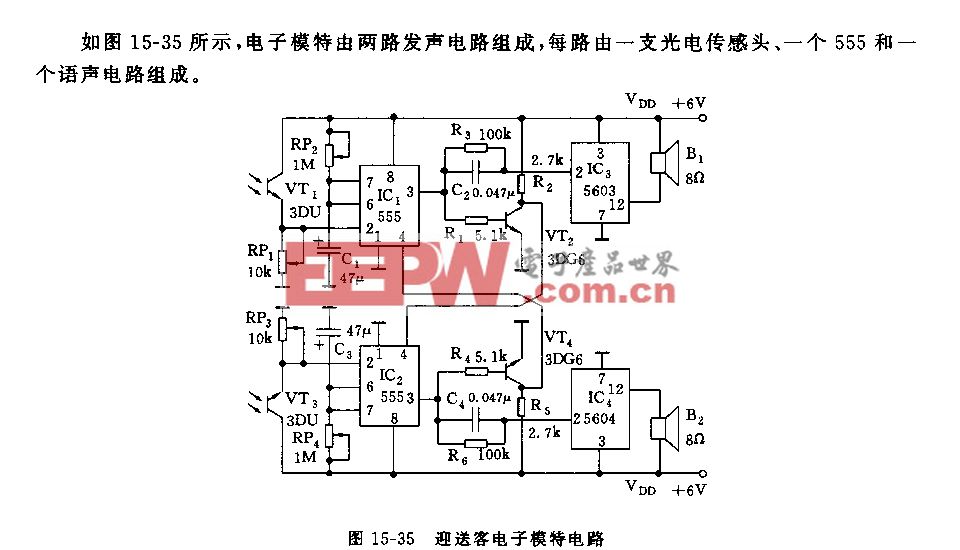
華為CVPR2021 | 加法網絡應用于圖像超分辨率

CVPR2021已經很多好的paper被公布,比如騰訊的20篇好文,后期我們也會詳細給大家分析,如果有機會還會分享代碼的整體運行講解。
今天我們要說的也是CVPR2021的一個優秀paper,華為技術產出的,其主要利用加法神經網絡(AdderNet)-加法網絡用于檢測,研究了單幅圖像超分辨率問題。 與卷積神經網絡相比,AdderNet利用加法計算輸出特征,避免了傳統乘法的大量能量消耗。

1、前言摘要
然而,由于計算范式的不同,很難將AdderNet在大規模圖像分類上的現有成功直接繼承到圖像超分辨率任務中。具體來說,加法器操作不容易學習標識映射,這對于圖像處理任務是必不可少的。此外,AdderNet無法保證高通濾波器的功能。
為此,研究員深入分析了加法器操作與標識映射之間的關系,并插入快捷方式,以提高使用加法器網絡的SR模型的性能。然后,研究員開發了一個可學習的power activation,以調整特征分布和細化細節。在幾個基準模型和數據集上進行的實驗表明,使用加法網絡的圖像超分辨率模型可以實現與其CNN基線相當的性能和視覺質量,并使能耗降低約2×。

2、相關領域及回顧
AdderNet
加法網絡,“計算機視覺研究院”平臺之前就詳細分析了,并且移植到目標檢測,具體鏈接如下:
CVPR2020最佳目標檢測 | AdderNet(加法網絡)含論文及源碼鏈接
代碼實踐 | CVPR2020——AdderNet(加法網絡)遷移到檢測網絡(代碼分享)
現有的有效超分辨率方法旨在減少模型的參數或計算量。最近,[Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, and Chang Xu. Addernet: Do we really need multiplications in deep learning? In CVPR, 2020]開創了一種新的方法,通過用加法運算代替乘法來減少網絡的功耗。它在卷積層中沒有任何乘法,在分類任務上實現了邊際精度損失。本此研究旨在提高加法網絡在超分辨率任務中的性能。
Preliminaries and Motivation
在這里,我們首先簡要介紹了使用深度學習方法的單個圖像超分辨率任務,然后討論了直接使用AdderNet構建節能SR模型的困難。現有的超分辨率方法大致可分為三類:interpolation based methods,dictionary-based methods和deep learning based methods。在過去的十年里,由于其顯著的表現,注意力已經轉移到深度學習方法上。[Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. In ECCV, pages 184–199, 2014]首先引入了深度學習方法來實現超分辨率,并取得了比傳統方法更好的性能。conventional SISR任務的總體目標函數可以表述為:

盡管下面公式顯示了類似的性能,在上面公式定義了SISR問題。與傳統的識別任務有很大的不同。例如,我們需要確保輸出結果保持X(即Iy)中的原始紋理,這是下面公式不容易學習的。因此,我們應該設計一個新的AdderNet框架來構建節能SISR模型。

3、AdderNet for Image Super-Resolution
Learning Identity Mapping using AdderNet

然后選擇每個元素的合適值:

Learnable Power Activation
除了標識映射外,傳統卷積濾波器還有另一個重要的功能,不能很容易地通過加法濾波器來保證。SISR模型的目標是增強輸入低分辨率圖像的細節,包括顏色和紋理信息。因此,在現有的SISR模型中,高通濾波器也是一個非常重要的組成部分。可以在下圖中找到,當網絡深度增加時,輸入圖像的細節逐漸增強。


4、實驗

一種具有不同策略的AdderSR網絡中加法層的輸出特征圖

[14]:Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, pages 1646–1654, 2016.


AdderSR Network and CNN on ×3 scale超分辨率圖像可視化

*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。