AVS 運動補償電路的VLSI 設計與實現

摘要:
提出了一種基于AVS 標準的高效的運動補償電路硬件結構, 該設計采用了8 ×8 塊級流水線操作, 運動矢量歸一化處理和插值濾波器組保證了流水線的高效運行以及硬件資源的最優利用。采用Verilog 語言完成了VLSI 設計, 并通過EDA 軟件給出仿真和綜合結果。
關鍵詞:
運動補償; 流水線; AVS
0 引言
AVS 標準是數字音視頻編解碼技術標準工作組(AVS 工作組) 制定的數字音視頻編碼標準,其視頻部分已于2006 年2 月份被信產部頒布為國家標準,于2006 年3 月1 日起實施。該標準主要面向高清晰度和高質量數字電視廣播、數字存儲媒體和其他相關應用。
運動估計和運動補償是AVS 中去除時間冗余的主要方法,它采用多種宏塊劃分方式,1P4 像素插值、雙向估計和多參考幀等技術大大提高了編碼效率,但同時也給編解碼器增加了一定的復雜度。本文針對AVS 所特有的運動補償解碼過程進行深入分析,并提出了與其算法相適應的運動補償電路的設計方案,電路采用Verilog 語言描述,并給出了綜合和仿真的結果。
1 AVS 運動補償關鍵技術分析研究
與其他視頻編解碼算法相類似,AVS 的運動補償技術主要涉及三個步驟:通過比特流中的相關信息計算運動矢量、按照運動矢量的指示進行地址轉換從MIU 中讀取參考像素值、通過參考像素值對當前解碼塊進行預測。同時,作為一種高效率的視頻壓縮算法,AVS 也有其獨特的技術特征。
AVS 共有4 種宏塊劃分類型:16 ×16 ,16 ×8 ,8 ×16和8 ×8 ,比MPEG- 2 增加了8 ×8 大小塊的運動估計,但并未像H. 264 一樣進行更細一級到4x4 塊的劃分;同時AVS 支持的最大參考幀數為2 幀,而不是MPEG- 4PH. 264 的16 幀,這些都使得AVS 既保證了一定的數據壓縮率,又控制了運算復雜度。
AVS 充分利用了圖像的運動連續性,對雙向預測分兩種模式進行處理:對稱模式和直接模式。在對稱模式中,前向矢量由當前圖像中空間相鄰塊的運動矢量獲得,而后向運動矢量由前向運動矢量通過一定的對稱規則獲得,從而節省了后向運動矢量的編碼開銷;在直接模式中,前向和后向運動矢量都是由后向參考圖像中相應位置的時間相鄰塊的運動矢量獲得,不需要傳送運動矢量差值,從而也提高了編碼效率。
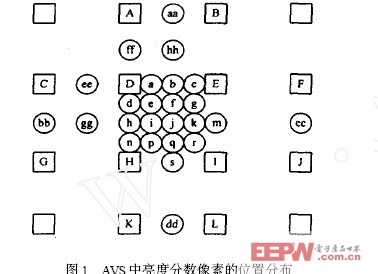 |
2 AVS 運動補償處理器的VLSI 結構設計
2. 1 運動補償處理器整體結構
分析AVS 的解碼算法,其運動矢量的計算,參考像素的讀取以及插值的計算三個部分計算量相當,于是該運動補償結構相應的包括三個主要功能模塊:MV Generation ,MC Controller 和Interpolation ,整個解碼器通過三個模塊的并行流水操作完成,從而實現了高清圖像的實時解碼。其中,MV Generation 根據Parser 解出的宏塊信息來產生運動補償過程所需要的運動矢量;MC Controller 根據得到的運動矢量從參考幀讀取相應的參考像素并總體控制運動補償的進行; Interpolation 完成非整數像素點的插值以及加權平均等一系列后處理操作,并將結果輸出給Reconstruct 模塊。
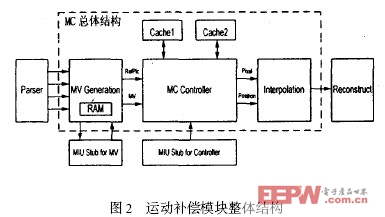 |
2. 2 MC Controller 的流水控制
在運動補償過程中,運動矢量的計算,MIU 訪問地址的轉換以及像素的插值之間具有嚴格的數據依賴特性,并且,運動矢量的生成時間以及向MIU 響應時間均無法確定,導致運動補償存在嚴重的等待問題。如果對每個宏塊都依次采用生成運動矢量、讀取參考像素、插值計算三個步驟,將會形成非常嚴重的時鐘浪費。
對此本文采用8 ×8 子塊級的流水線結構,通過握手機制對運動矢量的生成,參考像素的讀取,插值計算和加權進行調度,有效的降低了各模塊間因等待造成的時鐘浪費。
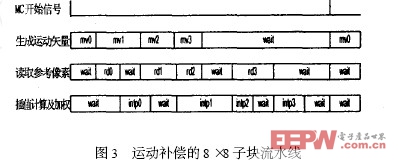 |
2. 3 MV Generation 的歸一化設計
AVS 支持16 ×16 ,16 ×8 ,8 ×16 和8 ×8 共四種宏塊劃分,靈活的宏塊劃分方式大大提高了AVS 的壓縮率。但由于當前宏塊及其相鄰宏塊的劃分均沒有一定的規律可循,如果依據常規宏塊的劃分規則進行運動矢量的存儲,則不僅要記錄當前宏塊的宏塊劃分,還要記錄其相鄰宏塊的宏塊劃分,增加了硬件的實現復雜度。
于是,將各種宏塊劃分的運動矢量均統一到8 ×8的塊上,對于運動矢量的生成和存儲均采用8 ×8 的塊為一個最小單位。對于16 ×16 ,16 ×8 ,8 ×16 的宏塊,令劃分在同一塊內的8 ×8 子塊共用一個計算結果,從而讀取參考塊的運動矢量時,可不必考慮相鄰宏塊的劃分類型,只需一套運動矢量生成電路就可以實現各種劃分方式的宏塊的運動矢量的計算和存儲,簡化了運動矢量生成電路的設計和控制,其總體結構如圖4 所示。
為了實現流水作業,這里對所有類型的宏塊中的四個8 ×8 塊按照左上、右上、左下和右下的順序從0 進行編號。首先,預處理模塊根據當前宏塊的宏塊類型和幀類型對宏塊的劃分類型進行判斷,頂層計數模塊給出當前解碼8 ×8 子塊的子塊號。
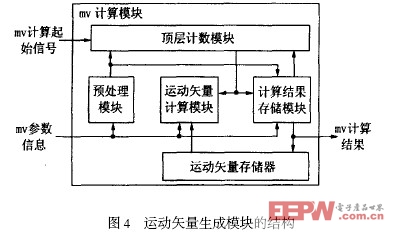 |
2. 4 1P4 像素亮度差值器
為了更加逼近實際圖像的運動效果,AVS 采用了特有的1P4 精度的亮度預測。但分數像素插值在提高圖像質量的同時,也大大增加了計算的復雜度,這在VLSI 實現時直接表現為成本的上升和功耗的增加。例如在解碼每秒30 幀,1 920 ×1 080 像素的高清碼流時,為了保證視頻播放的實時性,最壞情況 下每秒鐘需要對1 944 000 個8 ×8 像素的亮度塊進行插值操作。巨大的計算量給亮度插值器的VLSI實現帶來了一個難題,即如何在保證視頻解碼實時性的前提下,盡可能縮小芯片的面積并降低系統的時鐘頻率。
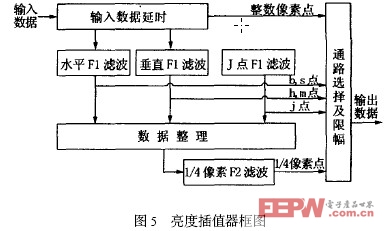 |
其中F1 和F2 均為4 抽頭濾波,F1 濾波系數為3 仿真試驗基于上述結構,本文完成了Verilog HDL 的RTL級描述,在modelsim5. 8 中對該運動補償模塊進行前仿,將testbench 中對MIU 的等待時間統一設為10 個時鐘周期,則P 幀每個宏塊需要120 到230 個時鐘周期不等,其中P skip 宏塊類型占用的時鐘最少,P8 ×8 宏塊占用的時鐘最多;B 幀中每個宏塊需要180 到490 個時鐘周期不等,其中B Direct 宏塊需要的時鐘最少,B8 ×8 雙向宏塊需要的時鐘最多。
另外,本文采用Synplify 為開發平臺對該運動補償設計進行綜合,選用Virtex4 XC4VLX80 器件,在速度選擇為- 10 的條件下,可綜合達到121. 1MHz ,共占用9 179個邏輯單元。可見本結構大大減少了視頻解碼過程中運動補償占用的時鐘周期,不僅充分滿足了實時解碼高清圖像的速度需求,而且有效的控制了硬件資源的使用量。
4 結束語
在視頻實時解碼芯片的設計中,處理速度和硬件資源的占用是影響芯片性能的兩個關鍵性問題。
本文在對AVS 運動補償算法進行合理分析的基礎上,提出以上結構,該結構既能夠高效的實現高清視頻的實時解碼,又合理的控制硬件資源的使用量。
參考文獻:
[1 ] 先進音視頻編碼標準[ S] . 2004.
[2 ] LI J H , LINGN. An efficient decoder design for MPEG- 2 MP@ML [C] . IEEE Int Conf . on Application - Specific Systems , Architectures and Processors. 1997 :509 - 518.
[3 ] MASAKI T , MORIMOTO Y, ONOYE T , et al . VLSI implementation of inverse discrete cosine transformer and motion compensator for MPEG- 2 HDTV video decoding[J ] . IEEE Trans. on Circuits and Systems for Video Technology , 1995 ,5(5) :387 - 395.
[4 ] 惠新葉,鄭志航,葉楠,MPEG- 2 運動補償的VLSI 設計[J ] . 上海交通大學學報,1999 ,7 :903 - 906.
[5 ] 劉龍,韓崇昭,王占輝. MPEG - 4 運動補償的VLSI 結構設計 [J ] . 通信學報,2005 (11) :117 - 124.
[6 ] Bhasker J . Verilog HDL 綜合實用教程[M] . 北京:清華大學出版社,2004.
[7 ] 高文,黃鐵軍. 心愿編碼標準AVS 及其在數字電視中的應用[J ] . 電視技術,2003 (11) :4 - 6.




評論