二維DCT編碼的DSP實現與優化

4 DSP實現與優化
無論是C語言還是匯編語言,程序流程均分為初始化、行變換、列變換和移位輸出四個步驟。行、列變換具有相似性,如果對行變換的結果矩陣轉置,則列變換程序跟行變換一樣。對于匯編而言,初始化部分主要初始化FP指針以指向前一函數地址,初始化數據和指針寄存器以保存返回數據等。由于DCT行變和列變換過程相似,且列變換是在行變換操作的基礎上進行的。則可利用多種索引尋址寄存器的靈活組合,把行變換結果直接以轉置方式存儲而不增加實際的存儲時間,這樣行列變換可使用同一代碼循環兩次實現,減小了實際代碼大小。圖2一維 DCT變換的流程圖。
由于DSP的小數乘法指令是先經過乘法運算后自動調整的,其運算時間比起整數運算要費時。因此,采用先倍乘CONST_SCALE,然后整數運算的方式來節省運算時間。運算的結果需要除以系數CONST_SCALE,這在程序運行時多帶來了兩次乘法,可以使用左右移位來實現。由于右移位同時會帶來移位誤差,因此在程序中使用了可選擇舍入運算方式。
為了達到更好的精度,在行變換時倍乘后再相加。這可使用Blackfin帶有預加/減比例的加法指令在一個指令周期內實現。
程序簡化行列變換的代碼如下:
B0 = R0;
B3 = R1;
B2 = R2; …
LSETUP (DCT_START, DCT_END) LC0 = P0;
DCT_START:…
LSETUP(ROW_START,ROW_END)LC1=P2;
ROW_START: …
ROW_END:…
B1 = B0;
B0 = B2;
DCT_END:B2 = B1;
程序初始時,R0指向輸入矩陣,R2指向中間矩陣,內層循環是行變換過程,該過程結束時,中間矩陣存儲著行變換結果的轉置。通過B0和B2的指針交換,把中間矩陣當作輸入進行行變換,這樣,把原輸入矩陣變成了輸出矩陣,并且矩陣中各元素位置不變。
比較式(1)和(3)發現,二維DCT 變換時結果為兩次無理數sqrt(8)相乘,產生了有理項,因此,在程序里首先多乘一次sqrt(8),然后在兩次DCT 變換結束以后,使用右移3位以達到正常輸出。
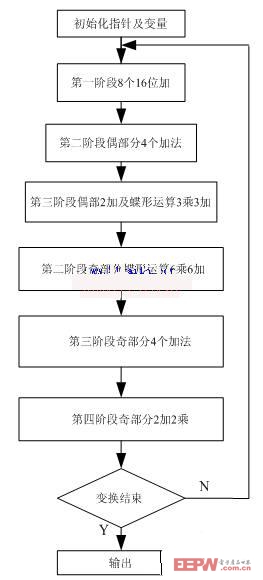
圖2 1維行DCT變換流程圖
為了評估優化后的效果,在ADSP—BF533 EZLITE平臺和VisualDSP4.5環境下,當BF533
工作在核心頻率594MHZ時,對一源圖像點陣灰度數據進行DCT處理。該灰度圖像為一個8×8的數組A[6],對A進行二維 DCT 調用,實際運行結果為:C語言代碼為392 bytes,執行時間為3.806397 μs;匯編語言代碼為248 bytes,執行時間為1.085859μs。顯然,與以C語言為主的二維DCT編碼相比,用匯編語言實現的二維DCT編碼在代碼大小、代碼執行時間上均得到了很大改善。
5 結論
本文創新之處在于能根據ADSP-BF533的結構和指令特點及視頻信號壓縮的實時性要求,使用匯編語言對視頻信號進行了二維DCT編碼及優化。實驗證明:在ADSP-BF533硬件平臺和VisualDSP4.5環境下,當 CPU運行在594MHZ時,使用匯編語言實現的DCT變換比C語言實現的DCT變換執行時間減小71.4%,代碼空間減小近30%。以標準CIF 測試序列為例,壓縮一張352×288的圖片能減少4.31ms,可見優化效果顯著。










評論