ARM體系結構之:流水線

2.2 流水線
2.2.1 流水線的概念與原理
處理器按照一系列步驟來執行每一條指令。典型的步驟如下:
① 從存儲器讀取指令(fetch);
② 譯碼以鑒別它是屬于哪一條指令(dec);
③ 從指令中提取指令的操作數(這些操作數往往存在于寄存器中)(reg);
④ 將操作數進行組合以得到結果或存儲器地址(ALU);
⑤ 如果需要,則訪問存儲器以存儲數據(mem);
⑥ 將結果寫回到寄存器堆(res)。
并不是所有的指令都需要上述每一個步驟,但是,多數指令需要其中的多個步驟。這些步驟往往使用不同的硬件功能,例如,ALU可能只在第4步中用到。因此,如果一條指令不是在前一條指令結束之前就開始,那么在每一步驟內處理器只有少部分的硬件在使用。
有一種方法可以明顯改善硬件資源的使用率和處理器的吞吐量,這就是當前一條指令結束之前就開始執行下一條指令,即通常所說的流水線(Pipeline)技術。流水線是RISC處理器執行指令時采用的機制。使用流水線,可在取下一條指令的同時譯碼和執行其他指令,從而加快執行的速度。可以把流水線看作是汽車生產線,每個階段只完成專門的處理器任務。
采用上述操作順序,處理器可以這樣來組織:當一條指令剛剛執行完步驟①并轉向步驟②時,下一條指令就開始執行步驟①。圖2.1說明了這個過程。從原理上說,這樣的流水線應該比沒有重疊的指令執行快6倍,但由于硬件結構本身的一些限制,實際情況會比理想狀態差一些。
2.2.2 流水線的分類
從Acorn Computer公司在1983~1985年間開發的第一個3µm器件,到ARM公司在1990~1995年間開發的ARM6和ARM7,ARM整數處理器核的組織結構變化很小,這些處理器都是采用3級流水線,而這一時期CMOS工藝的發展,幾乎將特征尺寸減少了一個數量級。因此,核的性能提高很快,但基本的操作原理大部分沒有變化。
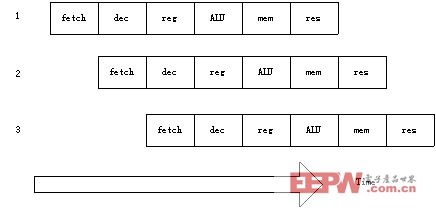
圖2.1 流水線的指令執行過程
從1995年以來,ARM公司推出了幾個新的ARM核。它們采用5級流水線和哈佛架構,獲得了顯著的高性能。例如,ARM9增加了存儲器訪問段和回寫段,這使得ARM9的處理能力可達到平均1.1 Dhrystone1 MISP/MHz,與ARM7相比,指令吞吐量提高了約13%。
| 注意 | 在許多高性能處理器內部,一級Cache一般都設置有兩個,其中,一個是指令Cache,另一個是數據Cache。這樣可以減少取指令和讀操作數的訪問沖突,這種結構被稱為哈佛架構。 把主存儲器分成兩個獨立編址的存儲器,一個專門存放指令,稱為指令存儲器,簡稱指存;另一個專門存放操作數,稱為數據存儲器,簡稱數存。兩個存儲器可以同時訪問,這樣就解決了取指令和讀操作數的沖突。如果在此基礎上規定在執行指令階段產生的運算結果只寫到通用寄存器中,不寫到主存,那么取指令、分析指令和執行指令就可以同時進行。 |
ARM10更是把流水線增加到6級。ARM10的平均處理能力達到1.3 Dhrystone MISP/MHz,與ARM7相比,指令吞吐量提高了約34%。
| 注意 | 雖然ARM9和ARM10的流水線不同,但它們都使用了與ARM7相同的流水線執行機制,因此ARM7上的代碼也可以在ARM9和ARM10上運行。 |

存儲器相關文章:存儲器原理






評論