基于VxWorks的多路高速串口的通信方法設計

信號經過1:10功分器,分給10個RF接收模塊,完成RF接收,輸出串行信號,每路串口為串行信號的最大速率115.2kbps,RF接收模塊每20ms發一個數據包,一個數據包最大為30bit。之后串行信號經過3片OX16C954(每片有4路UART)轉換成并行總線信號,輸出給MPC860T(CPU)。每片OX16C954設置有128B的環形緩沖區,所以經過時間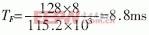 緩沖區就會被寫滿。為了保證不丟失數據,應該在8.8ms內完成對10個終端接收模塊進行一次接收。OX16C954中斷門限設為64B,當接收緩沖超過64B時,OX16C954產生接收中斷。在OX16C954還設置有超時中斷,當從接收最后一個停止位中心開始計時,在四個符號周期內沒有接收新的信息,即
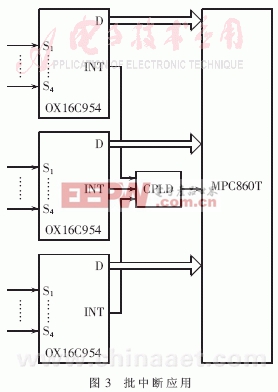
緩沖區就會被寫滿。為了保證不丟失數據,應該在8.8ms內完成對10個終端接收模塊進行一次接收。OX16C954中斷門限設為64B,當接收緩沖超過64B時,OX16C954產生接收中斷。在OX16C954還設置有超時中斷,當從接收最后一個停止位中心開始計時,在四個符號周期內沒有接收新的信息,即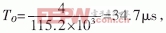 就產生超時中斷。批中斷的應用如圖3。多個串口通過CPLD共享一個中斷源,在中斷頻繁,多個串口同時產生中斷的情況下,實現了批中斷,節約了中斷資源,提高了中斷效率。
就產生超時中斷。批中斷的應用如圖3。多個串口通過CPLD共享一個中斷源,在中斷頻繁,多個串口同時產生中斷的情況下,實現了批中斷,節約了中斷資源,提高了中斷效率。
本系統的設計基于VxWorks操作系統。VxWorks操作系統提供對多種處理器的廣泛支持,具有完善的開發環境、開放的軟件接口、優異的實時性能和全面可靠的網絡功能及良好的可裁剪性,適用于各種嵌入式環境的開發。
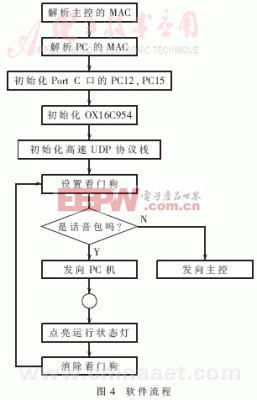
程序實現過程:系統加電待操作系統啟動之后,應用程序首先根據主控和PC機的IP地址,得到它們的MAC地址,為以后進行UDP數據傳送做準備;初始化MPC860T的Port C口,把PC12、PC15初始化為數據輸出口,分別用于點亮運行時的狀態燈和設置/清除硬件看門狗;初始化OX16C954,打開10路串口,接收終端模塊的數據;同時向終端模塊發送數據,初始化UDP協議棧;最后,進入無限循環中,從各個串口收集數據,解開數據包,以UDP的方式,把話音包發給PC機,把非話音包發給主控;同時,從網絡上接收來自主控的UDP數據,根據端口號,把數據轉發給各個終端模塊。PC機不直接向DPM發送UDP數據,只有主控向各個終端發送數據,故由DPM至PC機的數據為單向。管理看門狗,每循環一次,開關一次看門狗,處理一次狀態燈。整個程序的流程如圖4所示。
在10路都沒有數據的極限情況下測量輪詢開銷VP。在這種極限情況下,應用全中斷的方式,10路串口沒有數據不會產生中斷,中斷開銷為0;應用全輪詢的方式,CPU每次只查詢外部寄存器但不接收數據,所以每次CPU都是空轉,測量出來的為輪詢的固定開銷VP=163.84μs。在這種情況下,中斷顯然要優于輪詢。
3.1 均衡負載
在多路負載均衡的情況下,測量中斷吞吐率OI=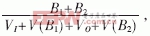 B1為達到OX16C954中斷門限后,觸發的接收中斷所接收的數據量(B1≥64B);B2為產生超時中斷時所接收的數據量(B2≤64B)。輪詢吞吐率OP=
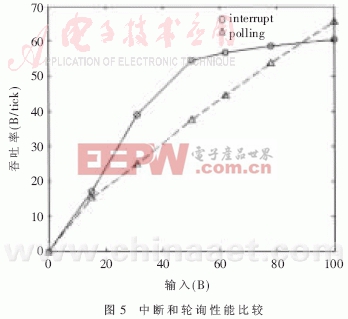
B1為達到OX16C954中斷門限后,觸發的接收中斷所接收的數據量(B1≥64B);B2為產生超時中斷時所接收的數據量(B2≤64B)。輪詢吞吐率OP=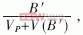 B′為輪詢接收的數據量。如圖5所示,在VxWorks系統中1tick=1/8000(s)。因為設置了中斷門限,所以中斷在數據量低的時刻有一個躍變;輪詢的躍變由輪詢的周期設置,如果改變輪詢周期,躍變點將發生轉移。輪詢的吞吐率隨輸入數據量的增加而呈線性增長;在數據量低時中斷要優于輪詢,隨著數據量的增長輪詢就要優于中斷,在兩者相交的時刻,通過實驗可以找到γ和PUMAX的值。
B′為輪詢接收的數據量。如圖5所示,在VxWorks系統中1tick=1/8000(s)。因為設置了中斷門限,所以中斷在數據量低的時刻有一個躍變;輪詢的躍變由輪詢的周期設置,如果改變輪詢周期,躍變點將發生轉移。輪詢的吞吐率隨輸入數據量的增加而呈線性增長;在數據量低時中斷要優于輪詢,隨著數據量的增長輪詢就要優于中斷,在兩者相交的時刻,通過實驗可以找到γ和PUMAX的值。
3.2 非均衡負載情況
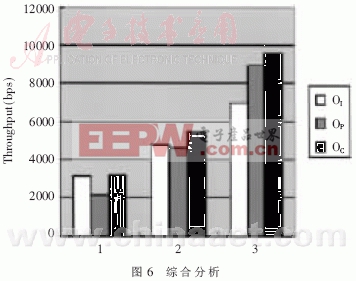
非均衡負載情況,即m1路數據負載大、m2路數據負載小的情況(m1+m2=10)下,測量OI、OP和OC(中斷和輪詢相結合的吞吐率)。如圖6所示,在橫坐標為1處,為m1=3,m2=7的情況,由于應用了批中斷,中斷的效率要優于輪詢,中斷和輪詢相結合的方法要略優于中斷;在橫坐標為2處,為m1=5,m2=5的情況,相結合的方法要略優于中斷和輪詢;在橫坐標3處為m1=7,m2=3的情況,相結合的方法近似輪詢,要優于中斷。
本文在綜合分析各種串口接收方式不足的基礎上,提出了中斷和輪詢相結合的方法。實驗結果表明,在滿足系統實時性要求的前提下,改進后的高速多串口系統吞吐率比應用單一的中斷或輪詢方式在多路高速串口系統中、各串口負載不均衡的情況下,得到了明顯的提高。



評論