晶圓級芯片,是未來

今天,大模型參數已經以「億」為單位狂飆。
本文引用地址:http://www.104case.com/article/202506/471845.htm僅僅過了兩年,大模型所需要的計算能力就增加了 1000 倍,這遠遠超過了硬件迭代的速度。目前支持 AI 大模型的方案,主流是依靠 GPU 集群。
但單芯片 GPU 的瓶頸是很明顯的:第一,單芯片的物理尺寸限制了晶體管數量,即便采用先進制程工藝,算力提升也逐漸逼近摩爾定律的極限;第二,多芯片互聯時,數據在芯片間傳輸產生的延遲與帶寬損耗,導致整體性能無法隨芯片數量線性增長。
這就是為什么,面對 GPT-4、文心一言這類萬億參數模型,即使堆疊數千塊英偉達 H100,依然逃不過「算力不夠、電費爆表」的尷尬。
目前,業內在 AI 訓練硬件分為了兩大陣營:采用晶圓級集成技術的專用加速器(如 Cerebras WSE-3 和 Tesla Dojo)和基于傳統架構的 GPU 集群(如英偉達 H100)。
晶圓級芯片被認為是未來的突破口。
晶圓級芯片,兩大玩家
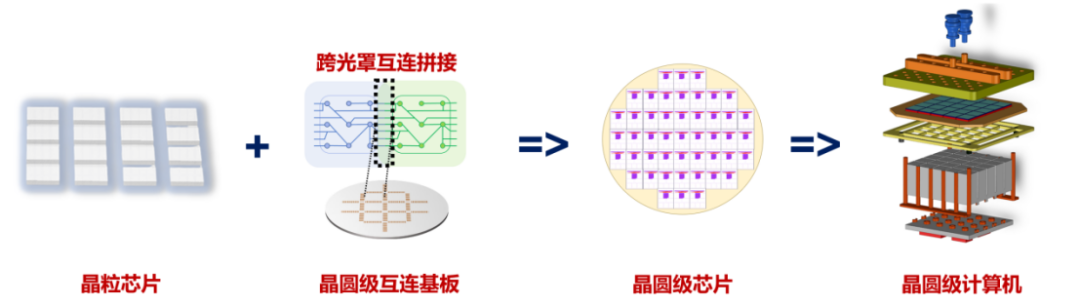
在常規的芯片生產流程中,一個晶圓會在光刻后被切割成許多小裸片(Die)并且進行單獨封裝,每片裸片在單獨封裝后成為一顆完整的芯片。
芯片算力的提升方式,是依靠增加芯片面積,所以芯片廠商都在不斷努力增加芯片面積。目前算力芯片的單 Die 尺寸大約是 26x33=858mm2,也就是接近曝光窗大小,但是芯片的最大尺寸無法突破曝光窗的大小。
曝光窗大小多年來一直維持不變,成為了制約芯片算力增長的原因之一。
晶圓級芯片則提供了另一種思路。通過制造一塊不進行切割的晶圓級互連基板,再將設計好的常規裸片在晶圓基板上進行集成與封裝,從而獲得一整塊巨大的芯片。
未經過切割的晶圓上的電路單元與金屬互連排列更緊密,從而形成帶寬更高、延時更短的互連結構,相當于通過高性能互連與高密度集成構建了更大的算力節點。所以,相同算力下,由晶圓級芯片構建的算力集群占地面積對比 GPU 集群能夠縮小 10-20 倍以上,功耗可降低 30% 以上。
全球有兩家公司已經開發出了晶圓級芯片的產品。
一家是 Cerebras。這家企業從 2015 年成立,自 2019 年推出了 WES-1,之后經過不斷迭代,目前已經推出到第三代晶圓級芯片——WES-3。
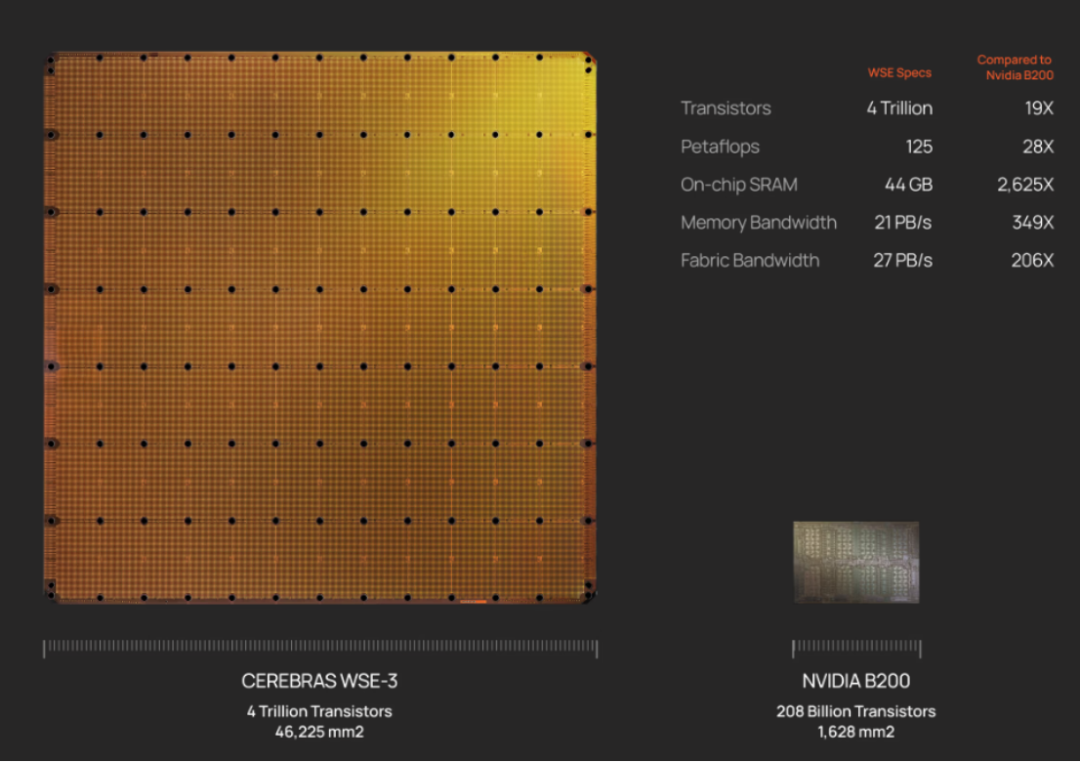
WES-3 采用臺積電 5nm 工藝,晶體管數量達到夸張的 4 萬億個,AI 核心數量增加到 90 萬個,緩存容量達到了 44GB,可以支持高達 1.2PB 的片外內存。
WES-3 的能力可以訓練比 GPT-4 和 Gemini 大 10 倍的下一代前沿大模型。四顆并聯情況下,一天內即可完成 700 億參數的調教,支持最多 2048 路互連,一天便可完成 Llama 700 億參數的訓練。
這些都是集成在一塊 215mm×215mm=46,225mm2 的晶圓上。
如果這個對比還不夠明顯,那可以這么看:對比英偉達 H100,WES-3 的片上內存容量是 H100 的 880 倍、單芯片內存帶寬是 H100 的 7000 倍、核心數量是 H100 的 52 倍,片上互連帶寬速度是 H100 的 3715 倍。

另一家是特斯拉。特斯拉的晶圓級芯片被命名為 Dojo。這是馬斯克在 2021 年就開始的嘗試。
特斯拉 Dojo 的技術路線和 Cerebras 不一樣。是通過采用 Chiplet 路線,在晶圓尺寸的基板上集成了 25 顆專有的 D1 芯粒(裸 Die)。
D1 芯粒在 645 平方毫米的芯片上放置了 500 億個晶體管,單個芯粒可以提供 362 TFlops BF16/CFP8 的計算能力。合起來的單個 Dojo 擁有 9Petaflops 的算力,以及每秒 36TB 的帶寬。
特斯拉的 Dojo 系統專門針對全自動駕駛 (FSD) 模型的訓練需求而定制。思路是從 25 個 D1 芯粒→1 個訓練瓦(Training Tile)→6 個訓練瓦組成 1 個托盤→2 個托盤組成 1 個機柜→10 個機柜組成 1 套 ExaPOD 超算系統,能夠提供 1.1EFlops 的計算性能。
晶圓級芯片與 GPU 對比
既然單芯片 GPU 和晶圓級芯片走出了兩條岔路,在這里我們以 Cerebras WSE-3、Dojo 和英偉達 H100 為例,對比一下兩種芯片架構對算力極限的不同探索。
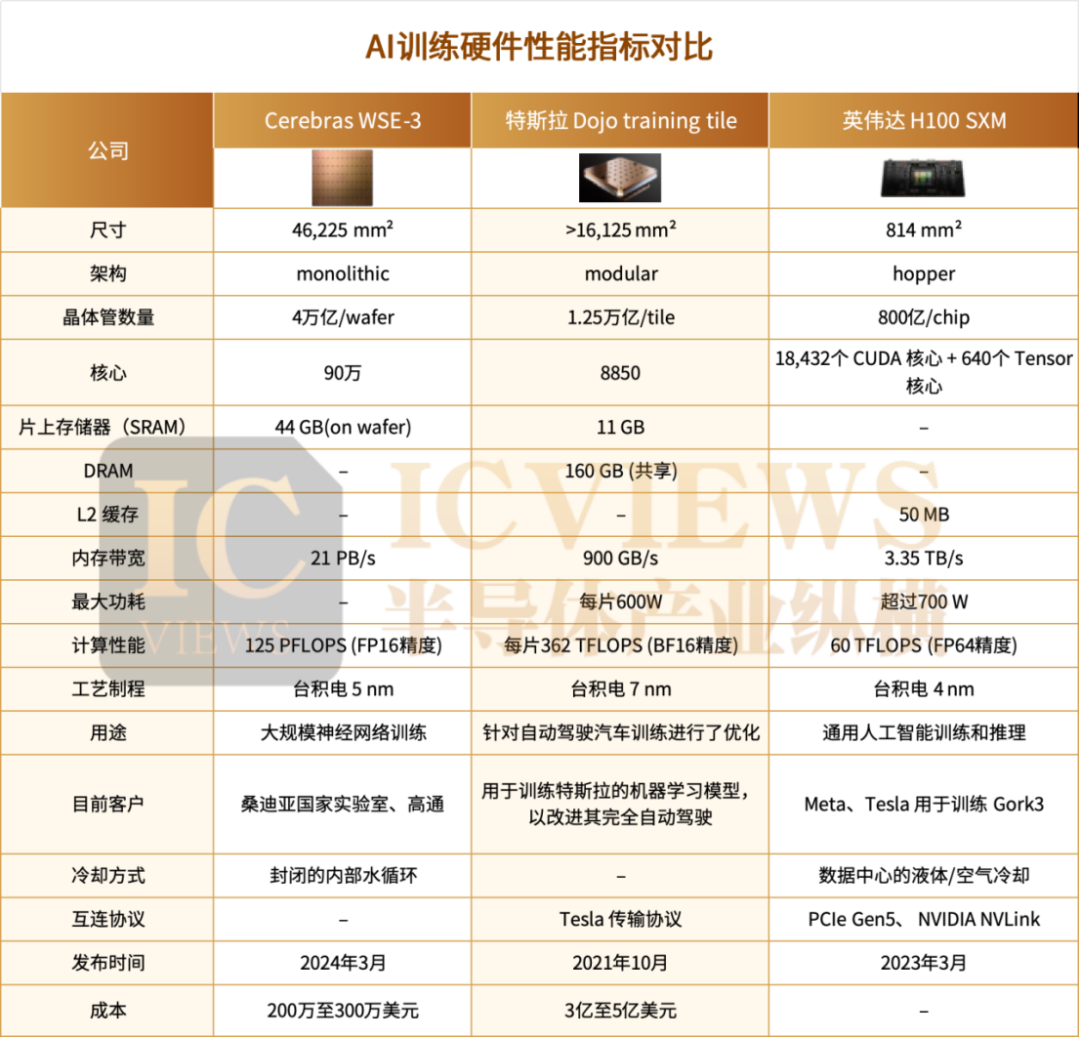
一般來說 AI 訓練芯片 GPU 硬件的性能通過幾個關鍵指標進行評估:每秒浮點運算次數 (FLOPS) ,表明 GPU 在深度學習中必不可少的矩陣密集型運算中的原始計算能力的強弱。內存帶寬,決定了訪問和處理數據的速度,直接影響訓練效率。延遲和吞吐量,能夠評估 GPU 處理大數據負載和模型并行性的效率,從而影響實時性能。
算力性能
Cerebras WSE-3 憑借單片架構,在 AI 模型訓練中展現獨特潛力。
一般來講,每秒浮點運算次數 (FLOPS) 能夠表明 GPU 在深度學習中必不可少的矩陣密集型運算中的原始計算能力。WSE-3 的 FP16 訓練峰值性能達到 125 PFLOPS,支持訓練高達 24 萬億參數的 AI 模型,且無需進行模型分區處理。這個功能就特別適合以精簡高效的方式處理超大模型。
與依賴分層內存架構(可能造成處理瓶頸)的傳統 GPU 不同,WSE 的設計使 850 個核心可獨立運行,并直接訪問本地內存,這樣就有效提升了計算吞吐量。
在這方面,英偉達 H100 采用的是模塊化和分布式方法。單個 H100 GPU 可為高性能計算提供 60 TFLOPS FP64 計算能力,八個互連的 H100 GPU 組成的系統,可實現超 1 ExaFLOP 的 FP8 AI 性能。
但分布式架構就存在數據傳輸問題,雖然 NVLink 和 HBM3 內存能降低延遲,但在訓練超大型模型時,GPU 間通信仍會影響訓練速度。
在 AI 訓練的表現中,Cerebras WSE-3 會更加擅長處理超大型模型。2048 個 WSE-3 系統組成的集群,訓練 Meta 的 700 億參數 Llama 2 LLM 僅需 1 天,相比 Meta 原有的 AI 訓練集群,速度提升達 30 倍。
延遲與吞吐量
從數據傳輸來看,WSE-3 的單片架構避免了多芯片間的數據傳輸,顯著降低延遲,支持大規模并行計算和核心間低延遲通信。速度快是單片的優勢,與傳統 GPU 集群相比,WSE-3 可將軟件復雜度降低高達 90%,同時將實時 GenAI 推理的延遲降低 10 倍以上。
特斯拉 Dojo Training Tile 屬于晶圓級集成,當然也能夠大幅降低通信開銷。由于是從 Die 到 Die 之間傳遞,在跨區塊擴展時仍會產生一定延遲。目前,Dojo 能實現 100 納秒的芯片間延遲,并且針對自動駕駛訓練優化了吞吐量,可同時處理 100 萬個每秒 36 幀的視頻流。
英偉達 H100 基于 Hopper 架構,是目前最強大的 AI 訓練 GPU 之一,配備 18,432 個 CUDA 核心和 640 個張量核心,并通過 NVLink 和 NVSwitch 系統實現 GPU 間高速通信。高速通信。雖然多 GPU 架構具備良好擴展性,但數據傳輸會帶來延遲問題,即便 NVLink 4.0 提供每個 GPU 900 GB/s 的雙向帶寬,延遲仍高于晶圓級系統。
盡管能夠憑借著架構特性實現單晶圓工作負載的低延遲和高吞吐量,但晶圓級系統如 WSE-3 和 Dojo 面臨著可擴展性有限、制造成本高和通用工作負載靈活性不足的問題。
誰更劃算?
從硬件購置成本來看,不同芯片的價格因架構和應用場景而異。
據報道,特斯拉單臺 Tesla Dojo 超級計算機的具體成本估計在 3 億至 5 億美元之間。技術路線上,Dojo 采用的是成熟晶圓工藝再加上先進封裝(采用了臺積電的 Info_SoW 技術集成),去實現晶圓級的計算能力,能夠避免挑戰工藝極限。這既能保證較高的良品率,又便于實現系統的規模化生產,芯粒的更新迭代也更為輕松。
Cerebras WSE 系統則因先進的制造工藝與復雜設計,面臨較高的初期研發和生產成本。據報道,Cerebras WSE-2 的每個系統成本在 200 萬至 300 萬美元之間。
相比之下,英偉達單 GPU 的采購成本比較低。以英偉達 A100 來說,40GB PCIe 型號價格約 8,000 - 10,000 美元,80GB SXM 型號價格在 18,000 - 20,000 美元。這使得許多企業在搭建 AI 計算基礎設施初期,更傾向于選擇英偉達 GPU。不過,英偉達 GPU 在長期使用中存在能耗高、多芯片協作性能瓶頸等問題,會導致運營成本不斷增加。
總體來看,雖然 WSE-2 能為超大規模 AI 模型提供超高計算密度,但對于需要在大型數據中心和云服務中部署多 GPU 可擴展方案的機構,A100 的成本優勢更為明顯。
結語
常規形態下,集群算力節點越多,則集群規模越大,花費在通信上的開銷就越大,集群的效率就越低。
這就是為什么,英偉達 NVL72 通過提升集群內的節點集成密度(即提高算力密度)。在一個機架中集成了遠超常規機架的 GPU 數量,使得集群的尺寸規模得到控制,效率才能實現進一步提升。
這是英偉達權衡了良率和成本之后給出的解決方案。但是如果英偉達繼續按照這種計算形態走下去,想要進一步提升算力密度,就會走到晶圓級芯片的路上。畢竟,晶圓級芯片的形態是目前為止算力節點集成密度最高的一種形態。
晶圓級芯片,潛力無限。


評論