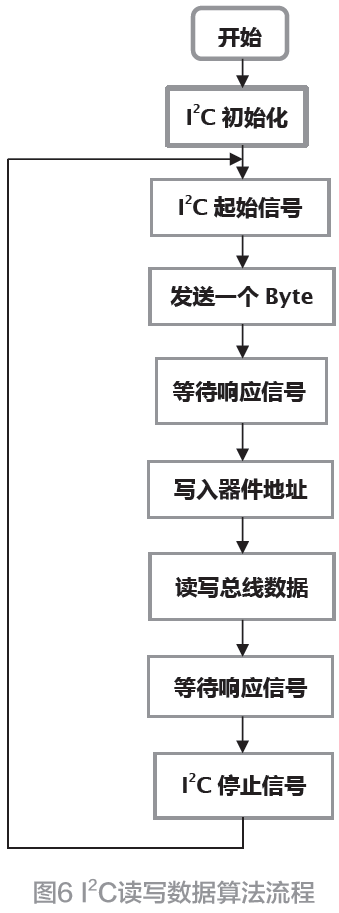
學貫中西(6):闡述ML分類器的工作流程

1 天字第一號ML模型:分類器
在上一期里,曾經在Excel 畫面的幕后,設計了一個分類器(Classifier)模型,將各< 詩句> 歸類到各自所屬的< 作品>。此時,把一個作品名稱(如靜夜思),當作一個類(Class)。于是,這種ML 模型,就通稱為:分類器。在ML(機器學習)領域中,分類器就是天字第1 號模型。
在本專欄的前面幾期里,曾經介紹過分類器的幕后實踐技術。在本期里,就來把去年介紹過的技術,與華夏的藝術、文化創作,連結起來,讓您能夠貫通ML 的知識體系及其實現技術,請您回憶上一期的范例(見圖1)。

圖1 基本范例示意
這是ML 模型的基本技能,它透過機器學習而記住了< 詩句> 與< 作品名稱> 之間的關系,也就是分類關系。于是我們就可以把某個< 詩句> 輸入給這模型,由它來預測(推論)出其所屬的< 作品名稱>(參見圖2)。

圖2 典型的ML分類器模型
這是典型的ML 分類器模型。我們可以建立更多這樣的模型,來表達各式各樣的事物之間的復雜關系。
2 分類器的學習流程
剛才已經說明了,分類器是一種AI 模型。顧名思義,它經過機器學習,就能在人們的指引下,認識不同種類的圖像,或其他事物。換句話說,它就具有分辨出不同種類事物的智慧能力。現在來舉例說明其學習流程。
2.1 收集數據
于此,敘述分類器的工作(學習)流程。例如,它就具有分辨出八大山人與畢加索,兩種不同畫作的風格。首先,收集兩個類的畫作圖像,如圖3。

圖3 畫作圖像示意
這些圖像是用來訓練一個分類器模型。訓練完畢之后,它就具有分辨出八大山人與畢加索,兩種不同畫作的風格。由于分類器是屬于監督式學習(Supervised learning),我們先進行分類,并且對各類來貼上標簽(Label)。貼上類的標簽:[1]代表<Picasso> 類,而以[0]代表< 八大山人> 類(見圖4)。
分類器是屬于監督式學習(Supervised learning),我們先進行分類,并且對各類來貼上標簽(Label)。貼上類的標簽:[1] 代表<Picasso> 類,而以[0]代表< 八大山人> 類。接下來,就來定義這個分類器的架構,包括它的各項參數來配合這些畫作圖像的大小(即多少像素)。

圖4 類標簽及分類器
現在,訓練數據(Training data)準備好了,模型也定義好了,就可以展開< 機器學習> 了;也就是,開始訓練這個分類器模型。
2.2 展開機器學習
● 步驟1:拿第1 筆數據來訓練
首先從Picasso 類取出一筆數據(即一張畫作),以X 表示之,輸入給分類器。同時,把Picasso 類的標簽,提供給分類器,做為目標值(Target),簡稱:T 值(見圖5)。

圖5 目標值設定
此時,分類器模型就進行推論(Inference):從X計算出Z。并且計算出Z 與T 的誤差。也就是:T–Z =Error(見圖6)。

圖6 推論產生

圖7 分類器參數更新
然后,依據這項誤差值(即Error)來更新這分類器的參數,如圖7 所示。于是,更新了分類器的參數,讓分類器的智慧提升了。此時已經輸入第1 筆數據,并對分類器進行1 次迭代(Iteration)的訓練了。
● 步驟2:拿第2 筆數據來訓練
現在從八大山人類取出一筆數據(即一張畫作),以X表示之,輸入給分類器。同時,把八大山人類的標簽,提供給分類器,做為目標值(T)。此時,分類器模型就進行推論:從X 計算出Z,如圖8 所示。

圖8 推論Z的產生過程
接下來,就計算出Z 與T 的誤差。也就是:T–Z =Error。然后,依據這項誤差值(即Error)來更新這分類器的參數(見圖9)。

圖9 更新后的分類器參數
更新了分類器的參數,讓分類器的智慧提升了。此時已經輸入2 筆數據,并對分類器進行2 次迭代的訓練了。
● 步驟3:繼續拿下一筆數據來訓練
這是重復< 步驟1> 的學習流程,從Picasso 類取出另一筆數據(即另一張畫作),以X 表示之,輸入給分類器。同時,把Picasso 類的標簽,提供給分類器,做為目標值。此時,分類器模型就進行推論,計算出Z和誤差值(Error)。最后,依據這項誤差值來更新這分類器的參數。更新了分類器的參數,讓分類器的智慧提升了。此時已經輸入3 筆數據,并對分類器進行3 次迭代的訓練了。
● 步驟4:繼續拿下一筆數據來訓練
這是重復< 步驟2> 的工作流程,但是從八大山人類別取出另一筆數據(即另一張畫作),來輸入給分類器。同時,把八大山人類的標簽,提供給分類器,做為目標值(T)。此時,分類器模型就進行推論,計算出Z 和誤差值。最后,依據這項誤差值來更新這分類器的參數,讓分類器的智慧提升了。此時已經輸入4 筆數據,并對分類器進行4 次迭代的訓練了。
● 步驟5:繼續重復循環下去
然后,重復循環下去,直到Error 趨近于0 為止。以上是典型的機器學習流程,其中每1 次迭代都各輸入1 筆數據給分類器去進行學習(也是訓練),也更新1 次模型參數。這樣地重復循環下去,就會逐一地把各筆數據(畫作)都輸入給分類器去學習了。當我們把全部數據都輸入給模型去學習了,就稱為:學習一回合(Epoch)。
如果學習了一回合之后,發現其誤差值(Error)還蠻大的(不接近于0),表示學習得還不夠好。于是繼續重復下去,也就是進行另一回合的學習,重復循環下去,直到Error 趨近于0 為止。一般而言,機器學習都需要進行數千或數萬,或更多回合的學習(訓練)過程,Error 才會趨近于0。
3 學習的效果
于此,使用空間對應(Space-mapping)的觀念來解釋之。輸入空間(即X 空間)包含全部數據(畫作),經由推論(計算)之后,會對應到輸出空間(即Z 空間)。這種對應過程,就通稱為:模型推論,如圖10 所示。

圖10 模型推論
經過數百或數千,或更多回合的學習之后,這分類器就能把這些畫作,對應(Mapping)到它們各自所屬的類了。

圖11 關系的建立
一旦機器學習完成,圖11 里的關系建立起來了。計算機(ML 模型)就觀察畫作的風格,而推論出該幅畫作是來自畢加索或是來自八大山人了。
4 結語
前面提到了,分類器是ML 領域的天字第一號模型。為什么它具有這樣重要的角色呢? 請您仔細領會一下圖11 里的X(空間)與Z(空間)的關系。基于這項關系,ML 模型就觀察畫作的風格(結果),而推論出該幅畫作是來自畢加索(原因)或是來自八大山人了。
于是,X 空間里的事物或其特征,是我們所觀察到的結< 果>。而Z 空間里所表達的卻是這些結果幕后隱藏的原< 因>。一旦能找到眼前(現實)結果幕后藏的真正的因,我們就能針對此< 因> 而對癥下藥,就可以改變眼前的< 果> 了。這稱為:溯因(Abductive reasoning)推理。君不見,許多人類的科學性創新,大多來自于這項溯因(又稱果因)推理能力。請您期待本專欄的繼續解說ML 的更多魅力。
(本文來源于《電子產品世界》雜志2022年4月期)



評論