七大統(tǒng)計(jì)模型詳解

四、判別分析
本文引用地址:http://www.104case.com/article/201812/395418.htm1、概述
判別分析是基于已知類別的訓(xùn)練樣本,對(duì)未知類別的樣本判別的一種統(tǒng)計(jì)方法,也是一種有監(jiān)督的學(xué)習(xí)方法,是分類的一個(gè)子方法!
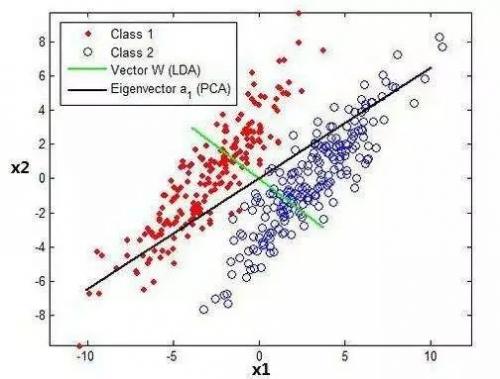
具體是:在研究已經(jīng)過分類的樣本基礎(chǔ)上,根據(jù)某些判別分析方法建立判別式,然后對(duì)未知分類的樣本進(jìn)行分類!
2、判別方法
根據(jù)判別分析方法的不同,可分為下面幾類:
(1) 距離判別法
(2) Fisher判別法
(3) Bayes判別法
(4) 逐步判別法
比較常用的是Bayes判別法和逐步判別法
3、 注意事項(xiàng):
判別分析主要針對(duì)的是有監(jiān)督學(xué)習(xí)的分類問題。這里重點(diǎn)注意其優(yōu)缺點(diǎn):
(1) 距離判別方法簡(jiǎn)單容易理解,但是它將總體等概率看待,沒有差異性;
(2) Bayes判別法有效地解決了距離判別法的不足,即:其考慮了先驗(yàn)概率——所以通常這種方法在實(shí)際中應(yīng)用比較多!
(3) 判別分析要求給定的樣本數(shù)據(jù)必須有明顯的差異,在進(jìn)行判別分析之前,應(yīng)首先檢驗(yàn)各類均值是不是有差異,如果檢驗(yàn)后某兩個(gè)總體的差異不明顯,應(yīng)將這兩個(gè)總體合為一個(gè)總體,再由剩下的互不相同的總體重現(xiàn)建立判別分析模型。
(4)Fisher判別法和bayes判別法的使用要求:兩者對(duì)總體的數(shù)據(jù)的分布要求不同,F(xiàn)isher要求對(duì)數(shù)據(jù)分布沒有特殊要求,而bayes則要求數(shù)據(jù)分布是多元正態(tài)分布,但實(shí)際中卻沒有這么嚴(yán)格!
五、主成分分析
1、概述
主成分分析是一種降維數(shù)的數(shù)學(xué)方法,具體就是,通過降維技術(shù)將多個(gè)變量化為少數(shù)幾個(gè)主成分的統(tǒng)計(jì)分析方法。
在建模中,主要用于降維,系統(tǒng)評(píng)估,回歸分析,加權(quán)分析等等。
2、分類(無)
3、注意事項(xiàng)
在應(yīng)用主成分分析時(shí)候,應(yīng)該注意:
(1) 綜合指標(biāo)彼此獨(dú)立或者不相互干涉
(2) 每個(gè)綜合指標(biāo)所反映的各個(gè)樣本的總信息量等于對(duì)應(yīng)特征向量的特征值。通常要選取的綜合指標(biāo)的特征值貢獻(xiàn)率之和應(yīng)為80%以上
(3) 其在應(yīng)用上側(cè)重于信息貢獻(xiàn)影響力的綜合評(píng)價(jià)
(4) 當(dāng)主成分因子負(fù)荷的符號(hào)有正也有負(fù)的時(shí)候,綜合評(píng)價(jià)的函數(shù)意義就不明確!
六、因子分析
1、概述
因子分析是將變量總和為數(shù)量較少的幾個(gè)因子,是降維的一種數(shù)學(xué)技術(shù)!
它和主成分分析的最大區(qū)別是:其是一種探索性分析方法,即:通過用最少個(gè)數(shù)的幾個(gè)不可觀察的變量來說明出現(xiàn)在可觀察變量中的相關(guān)模型,它提供了一種有效的利用數(shù)學(xué)模型來解釋事物之間的關(guān)系,體現(xiàn)出數(shù)據(jù)挖掘的一點(diǎn)精神!
2、分類
R型因子分析,即對(duì)變量的研究,此為常用
Q型因子分析,即對(duì)樣本的研究
3、因子分析和主成分分析的區(qū)別和聯(lián)系
(1) 兩者都是降維數(shù)學(xué)技術(shù),前者是后者的推廣和發(fā)展
(2) 主成分分析只是一般的變量替換,其始終是基于原始變量研究數(shù)據(jù)的模型規(guī)律;而因子分析則是通過挖掘出新的少數(shù)變量,來研究的一種方法,有點(diǎn)像數(shù)據(jù)挖掘中的未知關(guān)聯(lián)關(guān)則發(fā)現(xiàn)!
七、時(shí)間序列
1、概述
時(shí)間序列預(yù)測(cè)法是一種定量分析方法,它是在時(shí)間序列變量分析的基礎(chǔ)上,運(yùn)用一定的數(shù)學(xué)方法建立預(yù)測(cè)模型,使時(shí)間趨勢(shì)向外延伸,從而預(yù)測(cè)未來市場(chǎng)的發(fā)展變化趨勢(shì),確定變量預(yù)測(cè)值。
基本特點(diǎn)是:假定事物的過去趨勢(shì)會(huì)延伸到未來;預(yù)測(cè)所依據(jù)的數(shù)據(jù)具有不規(guī)則性;撇開市場(chǎng)發(fā)展之間的因果關(guān)系。
2、分類
時(shí)間序列的變動(dòng)形態(tài)一般分為四種:
長(zhǎng)期趨勢(shì)變動(dòng)
季節(jié)變動(dòng)
循環(huán)變動(dòng)
不規(guī)則變動(dòng)
方法分類:
(1) 平均數(shù)預(yù)測(cè)
(2) 移動(dòng)平均數(shù)預(yù)測(cè)
(3) 指數(shù)平滑法預(yù)測(cè)
(4) 趨勢(shì)法預(yù)測(cè)
(5) 季節(jié)變動(dòng)法


評(píng)論