FPGA也能做RNN

導(dǎo)言:循環(huán)神經(jīng)網(wǎng)絡(luò)(RNNs)具有保留記憶和學(xué)習(xí)數(shù)據(jù)序列的能力。由于RNN的循環(huán)性質(zhì),難以將其所有計算在傳統(tǒng)硬件上實現(xiàn)并行化。當(dāng)前CPU不具有大規(guī)模并行性,而由于RNN模型的順序組件,GPU只能提供有限的并行性。針對這個問題,普渡大學(xué)的研究人員提出了一種LSTM在Zynq 7020 FPGA的硬件實現(xiàn)方案,該方案在FPGA中實現(xiàn)了2層128個隱藏單元的RNN,并且使用字符級語言模型進(jìn)行了測試。該實現(xiàn)比嵌入在Zynq 7020 FPGA上的ARM Cortex-A9 CPU快了21倍。
本文引用地址:http://www.104case.com/article/201807/383934.htmLSTM是一種特殊的RNN,由于獨特的設(shè)計結(jié)構(gòu),LSTM適合于處理和預(yù)測時間序列中間隔和延遲非常長的重要事件。標(biāo)準(zhǔn)的RNN可以保留和使用最近的過去信息,但是不能學(xué)習(xí)長期的依賴關(guān)系。并且由于存在梯度消失和爆炸的問題,傳統(tǒng)的RNN無法訓(xùn)練較長的序列。為了解決上述問題,LSTM添加了記憶控制單元來決定何時記住、遺忘和輸出。LSTM的單元結(jié)構(gòu)如圖1所示。其中⊙代表element-wise的乘法。

圖1
用數(shù)學(xué)表達(dá)式表示圖1如圖2所示。其中表示Sigmoid函數(shù),是層的輸入向量,是模型參數(shù),是記憶單元激活值,是候選記憶單元門,是層的輸出向量。下標(biāo)表示前一時刻,就是相應(yīng)的輸入、遺忘和輸出門。這些門決定何時記住或遺忘一個輸入序列,以及何時輸出。人們需要對模型進(jìn)行訓(xùn)練,從而得到所需的輸出參數(shù)。簡單來說,模型訓(xùn)練是一個迭代過程,其中訓(xùn)練數(shù)據(jù)被輸入,然后將得到的輸出與目標(biāo)進(jìn)行比較。模型通過BP算法進(jìn)行訓(xùn)練。由于添加了更多的層和更多的不同的功能,模型可以變得相當(dāng)復(fù)雜。 對于LSTM,每個模塊有四個門和一些element-wise的操作。 深層LSTM網(wǎng)絡(luò)具有多個LSTM模塊級聯(lián),使得一層的輸出是下一層的輸入。
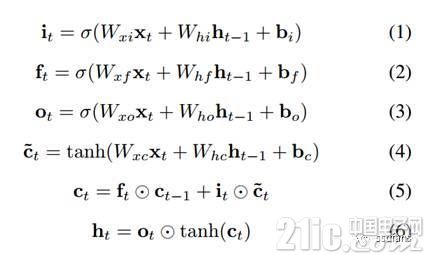
圖2
了解完了LSTM的特性后,如何設(shè)計LSTM在FPGA上的實現(xiàn)呢?下面我們來看一下實現(xiàn)方案。
1)硬件
硬件實現(xiàn)的主要操作就是矩陣向量乘法和非線性函數(shù)。
矩陣向量乘法由MAC單元計算, MAC單元需要兩個流:輸入向量流和加權(quán)矩陣的行向量流。將相同的矢量流與每個權(quán)重矩陣行相乘并累加,以產(chǎn)生與權(quán)重矩陣的高相同尺寸的輸出向量。在計算每個輸出元素之后,MAC被重置以避免累積先前的矩陣行計算。可以通過向權(quán)重矩陣的最后一列添加偏置向量來將偏置b添加到乘法累加中,同時為輸入向量增加一個額外的單位值。這樣就不需要為偏置添加額外的輸入端口,也可以向MAC單元添加額外的預(yù)配置步驟。 將MAC單元的結(jié)果加在一起。加法器的輸出是一個元素的非線性函數(shù),它是用線性映射來實現(xiàn)的。
非線性函數(shù)被分割成線性y = ax + b,其中x限于特定范圍。在配置階段,a,b和x范圍的值存儲在配置寄存器中。每個線性函數(shù)段用MAC單元和比較器實現(xiàn)。輸入值與線性范圍之間的比較決定是處理輸入還是將其傳遞給下一個線性函數(shù)段模塊。非線性函數(shù)分為13個線段,因此非線性模塊包含13個流水線段模塊。 實施設(shè)計的主要組成部分是如圖3所示的門模塊。
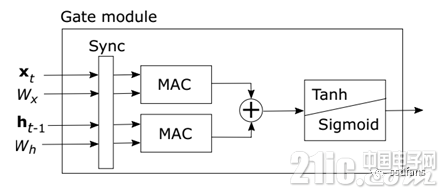
圖3
實現(xiàn)模塊使用直接存儲訪問(DMA)端口來進(jìn)行數(shù)據(jù)的讀入或?qū)懗觥S捎贒MA端口是獨立的,因此即使模塊同時激活端口,輸入流也不會同步。因此,需要流同步模塊。該同步塊用來緩存一些流數(shù)據(jù),直到所有端口都是流式傳輸。當(dāng)最后一個端口開始傳輸時,同步塊開始輸出同步流。這樣就能確保到MAC單元的向量和矩陣行元素對齊。另外,圖3中的門模塊還包含一個將32位值轉(zhuǎn)換為16位值的重分區(qū)塊。MAC單元執(zhí)行16位乘法,產(chǎn)生32位值。然后使用32位值執(zhí)行加法以保持精度。
圖2中的公式1,2,3,4都能用上述模塊實現(xiàn),剩下的只是計算公式5和6的一些element-wise的運算。為此,方案引入了如圖4所示的包含額外的乘法器和加法器的模塊。

圖4
最終形成的實現(xiàn)LSTM的方案如圖5所示。該方案使用圖3中的三個模塊和圖4中的一個。門被預(yù)配置為具有非線性函數(shù)(tanh或S形)。內(nèi)部模塊由狀態(tài)機(jī)控制以執(zhí)行一系列操作。實現(xiàn)的設(shè)計使用四個32位DMA端口。由于操作以16位完成,每個DMA端口可以傳輸兩個16位流。權(quán)重和連接在主存儲器中以利用該特征。然后根據(jù)要執(zhí)行的操作將流路由到不同的模塊。
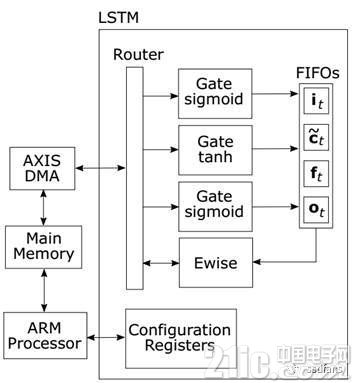
圖5
2)驅(qū)動軟件
控制和測試軟件用C代碼實現(xiàn)。該軟件將權(quán)重值和輸入向量放入主存儲器,并使用一組配置寄存器控制硬件模塊。權(quán)重矩陣的每行結(jié)尾是相應(yīng)的偏置值。輸入向量包含一個額外的單位值,使得矩陣向量乘法僅添加矩陣行的最后一個元素。零填充用于匹配矩陣行尺寸和向量尺寸,這使流同步更容易。
由于LSTM的循環(huán)性質(zhì),每次循環(huán)c和h都被覆蓋。這樣做可以最大限度地減少CPU完成的內(nèi)存復(fù)制次數(shù)。為了實現(xiàn)多層LSTM,將上一層的輸出復(fù)制到下一層的位置,以便在層之間保留以進(jìn)行錯誤度量。此外,控制軟件還需要通過在控制寄存器中設(shè)置不同的存儲位置來更改不同層的權(quán)重。
實驗和實驗結(jié)果
實驗實現(xiàn)了一個字符級語言模型,它預(yù)測了給定前一個字符的下一個字符。根據(jù)字符,模型生成一個看起來像訓(xùn)練數(shù)據(jù)集的文本,它可以是一本書或大于2 MB字的大型互聯(lián)網(wǎng)語料庫。本實驗選取莎士比亞的一部分作品進(jìn)行了訓(xùn)練。實驗實現(xiàn)了一個隱藏層大小為128的2層LSTM模型。
該方案在包含Zynq-7000 SOC XC7Z020的Zedboard上實現(xiàn)。它包含雙ARM Cortex-A9 MPCore,該實驗采用的C代碼LSTM的實現(xiàn)在Zedboard的雙ARM Cortex-A9處理器上運行,時鐘頻率為667 MHz。在FPGA上的實現(xiàn)運行的時鐘頻率為142 MHz的。芯片總功率為1.942 W,硬件利用率如表1所示。

表1
圖6展示了不同嵌入式平臺上的前饋LSTM字符級語言模型的執(zhí)行時間,時間越越好。我們看到,即使是在142MHz的時鐘頻率下,該實現(xiàn)依然比嵌入在Zynq 7020 FPGA上的ARM Cortex-A9 CPU的實現(xiàn)快了21倍。
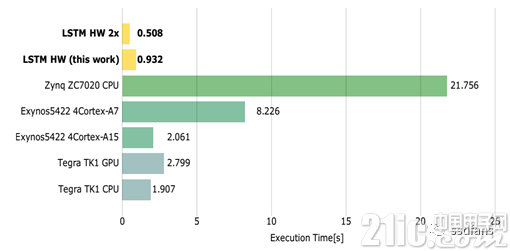
圖6
圖7展示了不同嵌入式平臺的單位功耗性能(值越大表示性能越好)。從圖中結(jié)果可以看出,F(xiàn)PGA的實現(xiàn)單位功耗性能遠(yuǎn)超其他平臺,這進(jìn)一步說明了FPGA實現(xiàn)的優(yōu)越性。
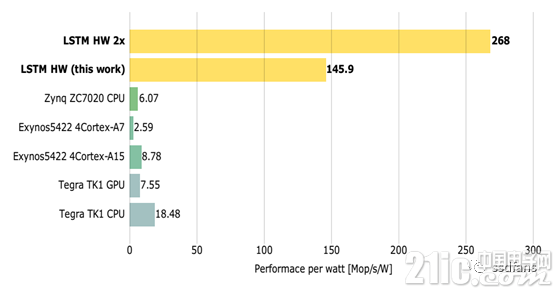
圖7





評論