CNN模型壓縮與加速算法綜述

XNOR-Net中一個典型的卷積單元如圖6所示,與傳統單元不同,各模塊的順序有了調整。為了減少二值化帶來的精度損失,對輸入數據首先進行BN歸一化處理,BinActiv層用于對輸入做二值化,接著進行二值化的卷積操作,最后進行pooling。
本文引用地址:http://www.104case.com/article/201807/383798.htm
圖5 BWN訓練過程

圖6 傳統卷積單元與XNOR-Net卷積單元對比
3.3 實驗結果
表5 ImageNet上二值網絡與AlexNet結果對比
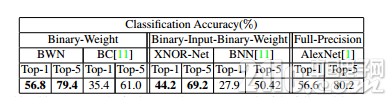
與ALexNet相比,BWN網絡能夠達到精度基本不變甚至略好,XNOR-Net由于對輸入也做了二值化,性能稍降。
四、Distilling
Distilling算法是Hinton等人在論文Distilling the Knowledge in a Neural Network中提出的一種類似網絡遷移的學習算法。
4.1 基本思想
Distilling直譯過來即蒸餾,其基本思想是通過一個性能好的大網絡來教小網絡學習,從而使得小網絡能夠具備跟大網絡一樣的性能,但蒸餾后的小網絡參數規模遠遠小于原始大網絡,從而達到壓縮網絡的目的。
其中,訓練小模型(distilled model)的目標函數由兩部分組成
1) 與大模型(cumbersome model)的softmax輸出的交叉熵(cross entropy),稱為軟目標(soft target)。其中,softmax的計算加入了超參數溫度T,用以控制輸出,計算公式變為
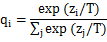
溫度T越大,輸出的分布越緩和,概率zi/T越小,熵越大,但若T過大,會導致較大熵引起的不確定性增加,增加了不可區分性。
至于為何要以soft target來計算損失,作者認為,在分類問題中,真值(groundtruth)是一個確定性的,即one-hot vector。以手寫數字分類來說,對于一個數字3,它的label是3的概率是1,而是其他數值的概率是0,而對于soft target,它能表征label是3的概率,假如這個數字寫的像5,還可以給出label是5的一定概率,從而提供更多信息,如
| 數字 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 真值 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 軟目標 | 0 | 0 | 0 | 0.95 | 0 | 0.048 | 0.002 | 0 | 0 | 0 |
2)與真值(groundtruth)的交叉熵(T=1)
訓練的損失為上述兩項損失的加權和,通常第二項要小很多。
4.2 實驗結果
作者給出了在語音識別上的實驗結果對比,如下表
表6 蒸餾模型與原始模型精度對比[8]
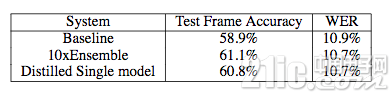
上表顯示,蒸餾后的模型的精確度和單字錯誤率和用于產生軟目標的10個模型的性能相當,小模型成功地學到了大模型的識別能力。
4.3 速度考量
Distilling的提出原先并非針對網絡加速,而最終計算的效率仍然取決于蒸餾模型的計算規模,但理論上蒸餾后的小模型相對原始大模型的計算速度在一定程度上會有提升,但速度提升的比例和性能維持的權衡是一個值得研究的方向。
五、MobileNet
MobileNet是由Google提出的針對移動端部署的輕量級網絡架構。考慮到移動端計算資源受限以及速度要求嚴苛,MobileNet引入了傳統網絡中原先采用的group思想,即限制濾波器的卷積計算只針對特定的group中的輸入,從而大大降低了卷積計算量,提升了移動端前向計算的速度。
5.1 卷積分解
MobileNet借鑒factorized convolution的思想,將普通卷積操作分成兩部分:
Depthwise Convolution
每個卷積核濾波器只針對特定的輸入通道進行卷積操作,如下圖所示,其中M是輸入通道數,DK是卷積核尺寸:

圖7 Depthwise Convolution
Depthwise convolution的計算復雜度為 DKDKMDFDF,其中DF是卷積層輸出的特征圖的大小。
Pointwise Convolution
采用1x1大小的卷積核將depthwise convolution層的多通道輸出進行結合,如下圖,其中N是輸出通道數:
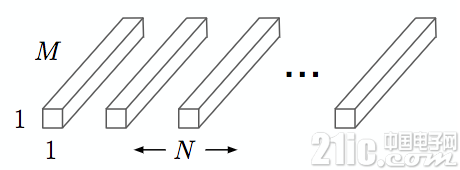
圖8 Pointwise Convolution[
Pointwise Convolution的計算復雜度為 MNDFDF
上面兩步合稱depthwise separable convolution
標準卷積操作的計算復雜度為DKDKMNDFDF
因此,通過將標準卷積分解成兩層卷積操作,可以計算出理論上的計算效率提升比例:
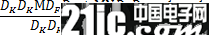
對于3x3尺寸的卷積核來說,depthwise separable convolution在理論上能帶來約8~9倍的效率提升。
5.2 模型架構
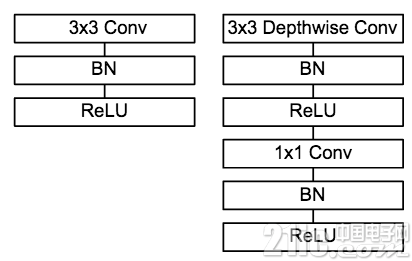
圖9 普通卷積單元與MobileNet 卷積單元對比
MobileNet的卷積單元如上圖所示,每個卷積操作后都接著一個BN操作和ReLU操作。在MobileNet中,由于3x3卷積核只應用在depthwise convolution中,因此95%的計算量都集中在pointwise convolution 中的1x1卷積中。而對于caffe等采用矩陣運算GEMM實現卷積的深度學習框架,1x1卷積無需進行im2col操作,因此可以直接利用矩陣運算加速庫進行快速計算,從而提升了計算效率。
5.3 實驗結果
表7 MobileNet與主流大模型在ImageNet上精度對比
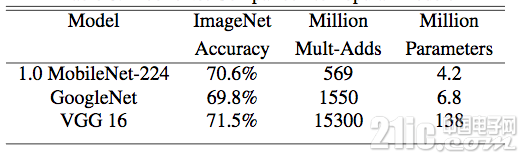
上表顯示,MobileNet在保證精度不變的同時,能夠有效地減少計算操作次數和參數量,使得在移動端實時前向計算成為可能。
六、ShuffleNet
ShuffleNet是Face++今年提出了一篇用于移動端前向部署的網絡架構。ShuffleNet基于MobileNet的group思想,將卷積操作限制到特定的輸入通道。而與之不同的是,ShuffleNet將輸入的group進行打散,從而保證每個卷積核的感受野能夠分散到不同group的輸入中,增加了模型的學習能力。
6.1 設計思想
我們知道,卷積中的group操作能夠大大減少卷積操作的計算次數,而這一改動帶來了速度增益和性能維持在MobileNet等文章中也得到了驗證。然而group操作所帶來的另一個問題是:特定的濾波器僅對特定通道的輸入進行作用,這就阻礙了通道之間的信息流傳遞,group數量越多,可以編碼的信息就越豐富,但每個group的輸入通道數量減少,因此可能造成單個卷積濾波器的退化,在一定程度上削弱了網絡了表達能力。
6.2 網絡架構
在此篇工作中,網絡架構的設計主要有以下幾個創新點:
提出了一個類似于ResNet的BottleNeck單元
借鑒ResNet的旁路分支思想,ShuffleNet也引入了類似的網絡單元。不同的是,在stride=2的單元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷積操作,有效地減少了計算量和參數。單元結構如圖10所示。
提出將1x1卷積采用group操作會得到更好的分類性能
在MobileNet中提過,1x1卷積的操作占據了約95%的計算量,所以作者將1x1也更改為group卷積,使得相比MobileNet的計算量大大減少。
提出了核心的shuffle操作將不同group中的通道進行打散,從而保證不同輸入通道之間的信息傳遞。
ShuffleNet的shuffle操作如圖11所示。
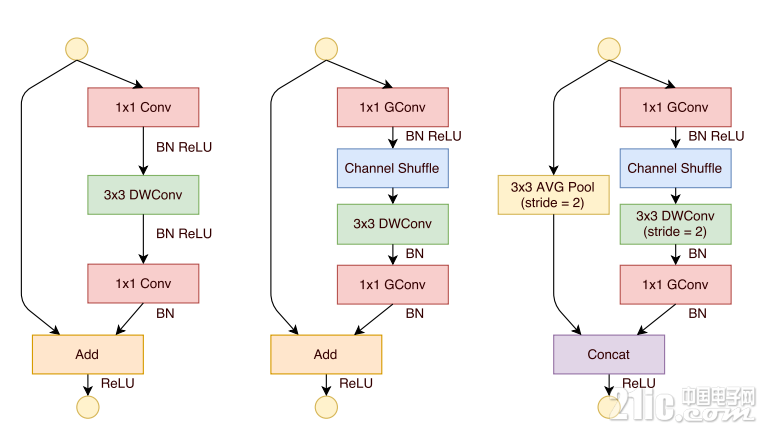
圖10 ShuffleNet網絡單元
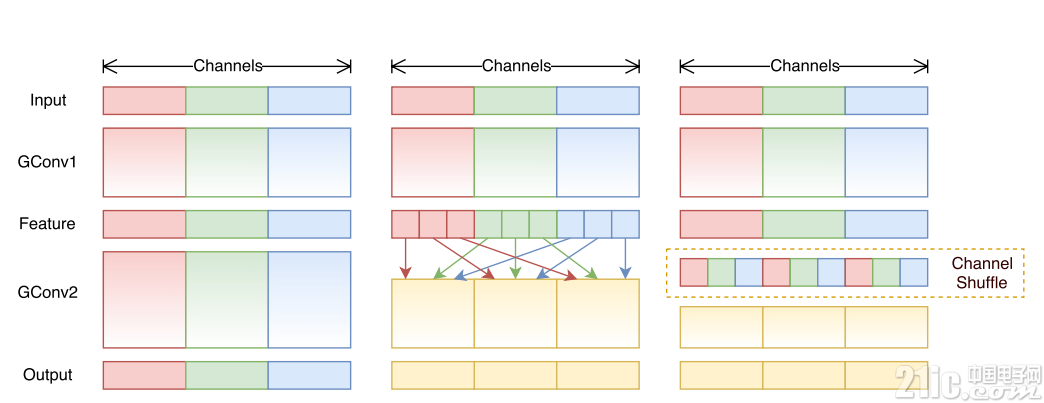
圖11 不同group間的shuffle操作
6.3 實驗結果
表8 ShuffleNet與MobileNet在ImageNet上精度對比
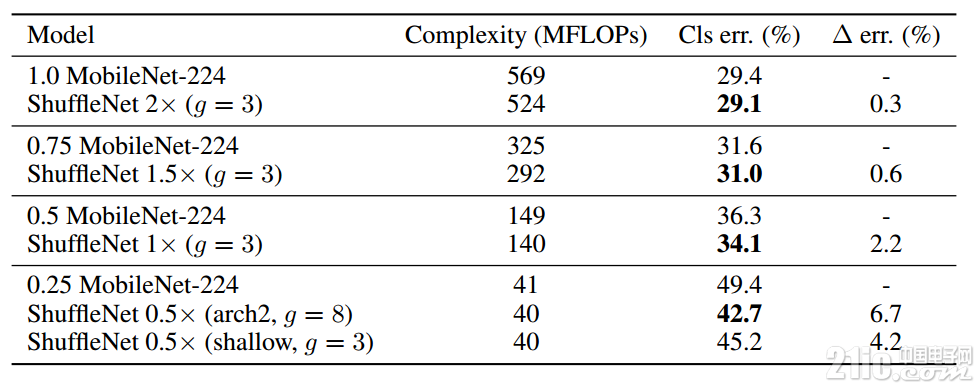
上表顯示,相對于MobileNet,ShuffleNet的前向計算量不僅有效地得到了減少,而且分類錯誤率也有明顯提升,驗證了網絡的可行性。
6.4 速度考量
作者在ARM平臺上對網絡效率進行了驗證,鑒于內存讀取和線程調度等因素,作者發現理論上4x的速度提升對應實際部署中約2.6x。作者給出了與原始AlexNet的速度對比,如下表。
表9 ShuffleNet與AlexNet在ARM平臺上速度對比 [10]

結束語
近幾年來,除了學術界涌現的諸多CNN模型加速工作,工業界各大公司也推出了自己的移動端前向計算框架,如Google的Tensorflow、Facebook的caffe2以及蘋果今年剛推出的CoreML。相信結合不斷迭代優化的網絡架構和不斷發展的硬件計算加速技術,未來深度學習在移動端的部署將不會是一個難題。





評論