Facebook宣布全面轉為神經網絡人工智能翻譯

語言翻譯是一股能夠讓人們組建群體和使世界更加緊密的力量。它可以幫助人們與在海外居住的家庭成員聯系起來,或者可以更好地了解講不同語言的人們的觀點。通過使用機器翻譯,自動翻譯文章和評論,以打破語言障礙,使得世界各地的人們可以相互溝通。
本文引用地址:http://www.104case.com/article/201708/362718.htm
即便體量大如Facebook,想要為20億使用的用戶創造無縫、高精確的翻譯體驗也是很困難的,這需要同時考慮上下文、俚語、打字錯誤、縮寫和語意。為了繼續提高翻譯質量,Facebook團隊最近宣布從基于短語的機器翻譯模型切換到基于神經網絡的翻譯模型,來支持所有的后端翻譯系統。每個翻譯系統每天翻譯超過2000個翻譯方向和45億個翻譯。這些新模型能夠提供更準確和更流暢的翻譯體驗,改善了人們在使用Facebook時,閱讀由非常用語言撰寫的內容時的閱讀體驗。雷鋒網(公眾號:雷鋒網)AI科技評論根據Facebook文章對相關情況編譯介紹如下。
使用上下文
Facebook以前使用的基于短語的統計技術確實有效,但它們也有局限性。基于短語的翻譯系統的一個主要缺點是它們將句子分解成單個單詞或短語,因此在生成翻譯時,他們每次只能考慮幾個單詞。這種方法導致當翻譯具有明顯不同字詞排序的語言時會出現翻譯困難的情況。為了彌補這個問題并構建神經網絡系統,Facebook開始使用一種被稱為序列到序列LSTM(longshort-termmemory)的循環神經網絡。這種網絡可以考慮源語句的整個上下文以及到目前為止生成的一切內容,以創建更準確和流暢的翻譯。這樣當遇到例如在英語和土耳其語之間翻譯字詞排列不同時,可以重新排序。當采用基于短語的翻譯模型從土耳其語翻譯到英語時,獲得以下翻譯:

與基于神經網絡的從土耳其語到英語的翻譯相比較:

當使用新系統時,與基于短語的系統相比,BLEU平均相對增長了11%-BLEU是廣泛使用的用于判斷所有語言的機器翻譯準確性的度量標準。
處理未知詞
在許多情況下,源語句中的單詞在目標詞匯表中并沒有直接對應的翻譯。當發生這種情況時,神經系統將為未知詞生成占位符。在這種情況下,可以利用注意機制在源詞和目標詞之間產生的軟校準,以便將原始的源詞傳遞到目標句子。然后,從培訓數據中構建的雙語詞典中查找該詞的翻譯,并替換目標語句中的未知詞。這種方法比使用傳統字典更加強大,特別是對于嘈雜的輸入。例如,在從英語到西班牙語的翻譯中,可以將“tmrw”(明天)翻譯成“ma?ana”。雖然增加了一個詞典,BLEU得分只有小幅的改善,但是對于使用Facebook的人而言評分更高了。 詞匯量減少
典型的神經機器翻譯模型會計算目標詞匯中所有單詞的概率分布。在這個分布中包含的字數越多,計算所用的時間越多。通過使用一種稱為詞匯減少的建模技術,可以在訓練和推理時間上彌補這個問題。通過詞匯減少,可以將目標詞匯中最常出現的單詞與給定句子的單個單詞的一組翻譯候選相結合,以減少目標詞匯的大小。過濾目標詞匯會減少輸出投影層的大小,這有助于更快的計算,而且不會使過大的降低質量。
調整模型參數
神經網絡幾乎通常具有可調參數,可以通過這些參數調節和控制模型的學習速度。選擇超參數的最佳集合對于性能是非常有幫助的。然而,這對于大規模的機器翻譯提出了重大的挑戰,因為每個翻譯方向是由其自己的一組超參數的唯一模型表示。由于每個模型的最優值可能不同,因此必須分別對每個系統進行調整。Facebook團隊在數月內進行了數千次端對端翻譯實驗,利用FBLearnerFlow平臺對超參數進行微調,如學習率,注意力類型和總體大小。這些超參數對一些系統有重大影響。例如,僅基于調優模型超參數,就可以看到從英語到西班牙語系統的BLEU相對值提高了3.7%。
用Caffe2縮放神經機器翻譯
過渡到神經系統的挑戰之一是讓模型以Facebook上的信息規模所需的速度和效率運行。因此Facebook團隊在深入學習框架Caffe2中實現了翻譯系統。由于它的靈活性,因此能夠在GPU和CPU平臺上進行訓練和推理,來調整翻譯模型的性能。
關于培訓,該團隊實施了內存優化,如blob回收和blob重新計算,這有助于更大批量的培訓,并更快地完成培訓。關于推理,該團隊使用專門的向量數學庫和權重量化來提高計算效率。現有模式的早期基準表明,支持2000多個翻譯方向的計算資源將會非常高。然而,Caffe2的靈活性和該團隊使用的優化模型使計算提高了2.5倍的效率,因而能夠將神經機器翻譯模型應用到實際中去。
該團隊還遵循在機器翻譯中常用的在解碼時使用波束搜索的做法,以根據模型改進對最可能輸出的句子的估計。利用Caffe2中的循環神經網絡(RNN)抽象的一般性來實現波束搜索,直接作為單個前向網絡計算,這樣就實現了快速有效的推理。
在這項工作的過程中,該團隊還開發了RNN構建塊,如LSTM,乘法集成LSTM和注意。這項技術將作為Caffe2的一部分分享出來,并為研究和開源社區提供學習素材。
正在進行的工作
Facebook人工智能研究(FAIR)團隊最近發表了使用卷積神經網絡(CNN)進行機器翻譯的研究。Facebook代碼團隊與FAIR密切合作,在不到三個月的時間里,完成了將這項技術從研究到首次投入生產系統中使用的流程。他們推出了從英文到法文和從英文到德文翻譯的CNN模型,與以前的系統相比,BLEU的質量提升分別提高了12.0%(+4.3)和14.4%(+3.4)。這些質量改進讓該團隊看到CNN將成為一個令人興奮的新發展道路,后面他們還將將繼續努力,利用CNN推出更多的翻譯系統。
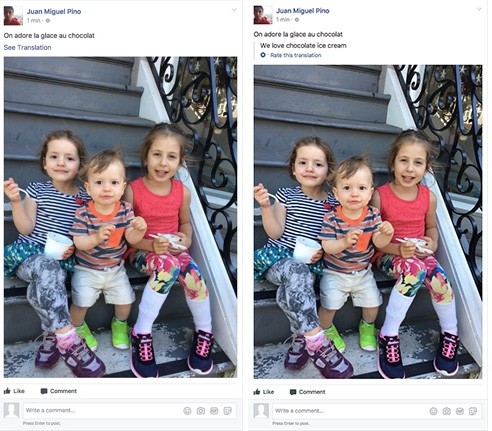
目前機器翻譯剛剛開始使用更多的翻譯語境。神經網絡開辟了許多與添加更多上下文相關的發展方向,以創建更好的翻譯,例如伴隨文章文本的照片。
該團隊也開始同時探索可以翻譯許多不同語言方向的多語種模式。這將有助于解決與特定語言對相關的每個系統的微調的挑戰,并且還可以通過共享培訓數據為某些翻譯方向帶來質量提高。
對Facebook而言,完成從短語到神經機器翻譯的過渡,是一個里程碑,代表了為所有人提供他們常用語言下的更優質的Facebook體驗。他們還將繼續推進神經機器翻譯技術,目的是為Facebook上的每個人提供人性化的翻譯。






評論