大熱的麥克風陣列語音識別系統的設計和輕松實現,提供軟硬件解決方案

摘要:
在非近距離語音識別中,由于衰減、干擾、混響等因素的影響,使語音識別率顯著降低。使用麥克風陣進行語音識別的好處是通過提高信噪比來提高語音識別率。而本項目與傳統的麥克風陣進行語音識別的方法又有不同,它將語音接收端與語音識別部分組成一個反饋系統,通過優化接收端濾波器的系數,使跟語音識別密切相關的倒譜域似然比最大,來提高語音識別準確率。在進行Matlab仿真之后,將算法應用到FPGA中。FPGA開發板暫定為Xilinx公司的Nexys 3 Spartan-6 FPGA Board。
1、研究方案
1.1 總統研究方案
當前基于隱馬爾可夫模型(HMM)的麥克風陣語音識別系統,主要包括陣列信號處理和特征識別兩個階段,原理圖如圖1.1所示:
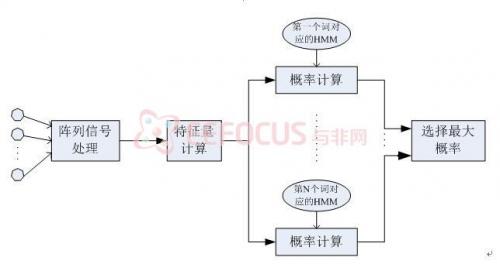
圖1.1 基于HMM的麥克風陣語音識別系統結構
其中前端的陣處理主要是為了進行語音增強,目的是在提取語音參數之前,盡量減小信號波形的失真。這一做法基于的假設是,對波形質量得到改善的信號進行特征識別能夠提高識別性能,即先后單獨進行陣處理和特征識別操作,如圖1.2所示:
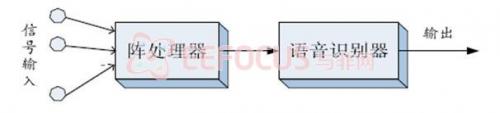
圖1.2 常規的麥克風陣語音識別系統框架
本項目采用的處理方法,對陣元接收的信號進行濾波求和,其目的并不是為了改善信號波形質量,而是在于直接提高識別過程中正確假設的似然概率,進而提高識別率。這一方案需要將陣處理和識別過程聯合起來考慮,框架如圖1.3所示:

圖1.3 結合識別過程進行陣處理的語音識別系統框架
本方案在接收陣上引入一組FIR濾波器,通過優化濾波器系數,產生一組陣參數以最大化信號被正確識別的概率。此方案將識別系統的輸出結果反饋至前端的麥克風陣列,把識別系統的統計模型也考慮到前端陣處理中,是一種根據期望假設最大化而非期望信號最優化的自適應處理方法,以強化對于識別更為重要的信號分量,而之前的方法則是無分別地同等地加強所有的信號分量。
語音識別系統的工作原理在于從模板庫中找出最有可能產生特征觀察矢量序列的單詞作為識別結果輸出,即:對某一待識別的觀察矢量,詞庫中每個詞匯對應的HMM模板分別計算出相應的似然概率,選擇使似然概率最大的模板所對應的詞匯作為識別假設結果輸出。
本文采用FIR濾波器對麥克風陣接收的信號進行處理,然后從濾波得到的信號中提取語音特征矢量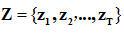 。定義一個濾波器參數矢量
。定義一個濾波器參數矢量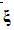 包含該FIR濾波器中所有的系數,識別假設的得出依照貝葉斯分類準則:
包含該FIR濾波器中所有的系數,識別假設的得出依照貝葉斯分類準則: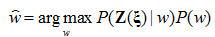 ,其中詞語的發生概率
,其中詞語的發生概率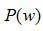 是基于語言模型的經驗值,而假設似然概率
是基于語言模型的經驗值,而假設似然概率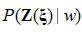 的計算則基于識別系統的統計模型。本文聯合空時處理和語音識別過程,目的就在于搜索出一組FIR濾波器參數矢量
的計算則基于識別系統的統計模型。本文聯合空時處理和語音識別過程,目的就在于搜索出一組FIR濾波器參數矢量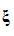 使得正確假設的似然概率
使得正確假設的似然概率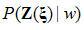 最大化,提高正確假設與非正確假設之間的概率差值,從而提高得到正確假設的概率。具體流程見圖1.4、圖1.5。其中圖1.4是訓練濾波器系數的框圖,圖1.5是利用已訓練完成的濾波器系數進行語音識別的框圖。
最大化,提高正確假設與非正確假設之間的概率差值,從而提高得到正確假設的概率。具體流程見圖1.4、圖1.5。其中圖1.4是訓練濾波器系數的框圖,圖1.5是利用已訓練完成的濾波器系數進行語音識別的框圖。
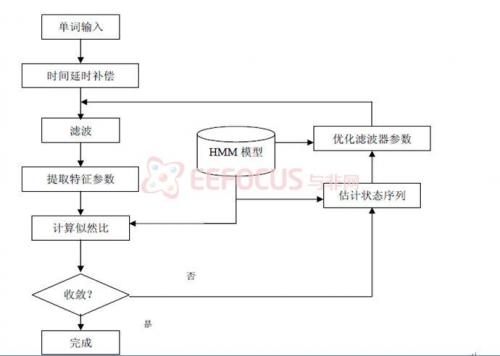
圖1.4 訓練FIR濾波器系數流程圖
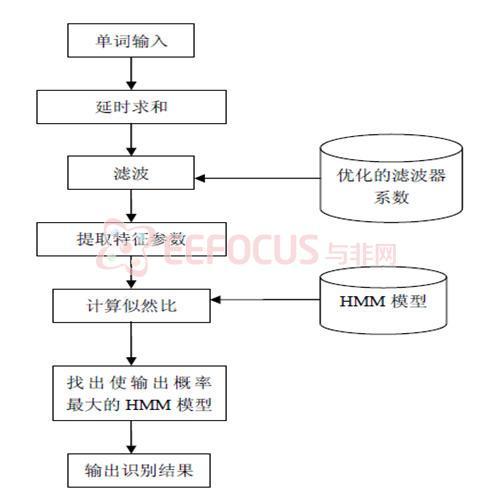
圖1.5 聯合FIR濾波的語音識別流程圖
1.2 關鍵算法
1.2.1延時求和
采用互相關法計算各路信號的時間延遲。假設有四路信號,分別為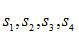 。以
。以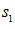 為參考信號,分別與
為參考信號,分別與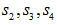 作互相關運算。以
作互相關運算。以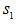 與
與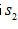 為例,與作互相關,
為例,與作互相關,
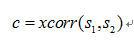
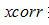 指代互相關運算。求出使
指代互相關運算。求出使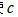 最大時,信號所處的時刻,再減去與中長度較長的那個信號的長度,就可以求得信號的相對時延了。即假設使互相關函數
最大時,信號所處的時刻,再減去與中長度較長的那個信號的長度,就可以求得信號的相對時延了。即假設使互相關函數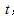 最大的時刻為t,
最大的時刻為t,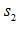 為其中長度較長的信號,其長度為
為其中長度較長的信號,其長度為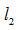 ,那么:
,那么:
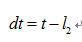
即為相對時延。若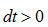 ,則信號
,則信號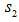 比信號
比信號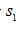 先到達,反之,則信號
先到達,反之,則信號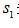 先到達。現在討論
先到達。現在討論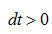 的情況,則要對信號進行延時補償,即將信號向左平移
的情況,則要對信號進行延時補償,即將信號向左平移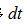 ,平移出的值舍去。
,平移出的值舍去。
根據以上兩路信號的討論,可以總結出四路信號進行延時補償的步驟:
- 以信號
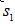 為參考信號,分別對其他三路信號作互相關運算;
為參考信號,分別對其他三路信號作互相關運算; - 記三個互相關函數分別為
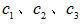 ;
; - 計算三路信號相對于信號
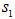 的時延,分別即為
的時延,分別即為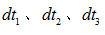 ;
; - 找出三個時延中值最大的那個,假設為
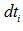 ;
; - 如果
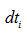 大于0,那么信號
大于0,那么信號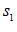 向左平移
向左平移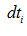 ,其他三路信號向左平移
,其他三路信號向左平移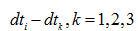 ;
; - 如果
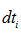 小于0,那么信號
小于0,那么信號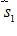 不用平移,其他三路信號向左平移
不用平移,其他三路信號向左平移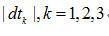
1.2.2 特征參數提取
其中特征參數的提取是采用Mel頻率倒譜系數,這是因為Mel刻度在對聲學測量時是最合理的頻率刻度。基于聽覺模型得到的Mel倒譜系數比基于聲道模型得到的LPC倒譜系數更符合人的聽覺特性,在有信道噪聲和頻譜失真的情況下,能產生更高的識別精度。所以本語音識別系統選擇MFCC做為特征提取的參數。MFCC的產生過程可用圖1.6表示。
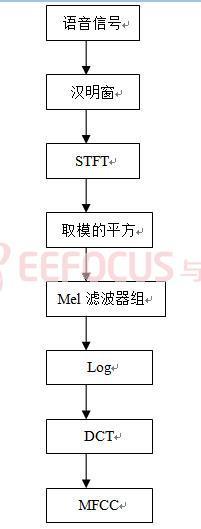
圖1.6 計算MFCC的流程圖
2、實驗設備及設計方案
本項目首先用Matlab仿真算法,采用一個六通道的音頻采集硬件系統,連接到PC上采集語音信號。該系統主要包括六只同型號的全指向性電容話筒,一個放大倍數可調的多通道低噪放,和一塊采樣頻率最高可達50KHz的數據采集卡,結構框圖如圖2.1所示,圖2.2是實物拍攝照片。實驗中,將六個麥克風排列成按照5.2cm的相鄰陣元中心間距排列成一均勻線陣進行數據采集,如圖2.3所示。
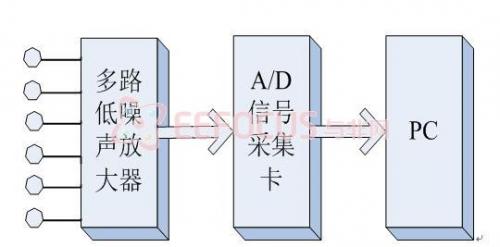
圖2.1 基于PC的音頻采集硬件系統框架

圖2.2 音頻采集硬件實物

圖2.3 麥克風陣架子,架子長約65cm,寬約20cm
本實驗每個人錄制HMM模型庫中的十個單詞,分別為able、afraid、already、autumn、base、below、body、box、build、careful,錄制人離麥克風陣2.5米左右,麥克風間的距離約為5cm,這樣就能夠近似認為,說話人說出的語音信號是由平面波的形式到達麥克風陣的。錄制環境的信噪比大約為50dB。將這些錄制的單詞儲存在PC中,然后用Matlab程序進行訓練得到濾波器系數。之后采用圖1.5的流程進行語音識別。經過初步的研究發現,該算法具有較好的識別效果。
下一步就是將Matlab算法移植到FPGA中,如圖2.4。
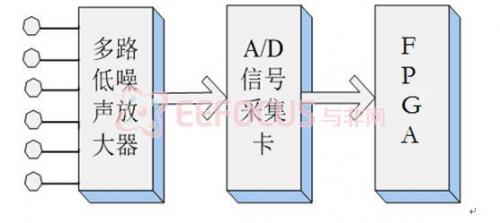
圖2.4 基于Nexys 3 Spartan-6 FPGA Board的音頻采集硬件系統框架
首先將訓練得到的濾波器系數及HMM模型存儲與Nexys 3 Spartan-6 FPGA Board的外部存儲器中,之后經多路低噪聲放大器,AD信號采集卡將測試者的語音信號輸入到FPGA。因為采集卡輸入的是串行的信號,FPGA需將六路語音信號進行時分復用采集,轉換為并行的信號,供后續處理。后續處理流程及算法參見圖1.5及1.2 關鍵算法。其中濾波器、乘法、FFT等等算法可以利用現有的IP核,以提高設計效率。識別完成后將識別結果在七段譯碼顯示器上顯示。為了簡便起見,可以將able、afraid、already、autumn、base、below、body、box、build、careful分別標定為1~10,然后將相應的數字顯示在七段譯碼顯示器上。
如果識別效果理想,可以將現有的十個單詞的庫提升到50個詞、100個詞,但是這都需要進一步的研究以及更高性能的硬件支持。





評論