谷歌TPU研究論文:專注神經網絡專用處理器

過去十五年里,我們一直在我們的產品中使用高計算需求的機器學習。機器學習的應用如此頻繁,以至于我們決定設計一款全新類別的定制化機器學習加速器,它就是 TPU。
本文引用地址:http://www.104case.com/article/201704/346340.htmTPU 究竟有多快?今天,聯合在硅谷計算機歷史博物館舉辦的國家工程科學院會議上發表的有關 TPU 的演講中,我們發布了一項研究,該研究分享了這些定制化芯片的一些新的細節,自 2015 年以來,我們數據中心的機器學習應用中就一直在使用這些芯片。第一代 TPU 面向的是推論功能(使用已訓練過的模型,而不是模型的訓練階段,這其中有些不同的特征),讓我們看看一些發現:
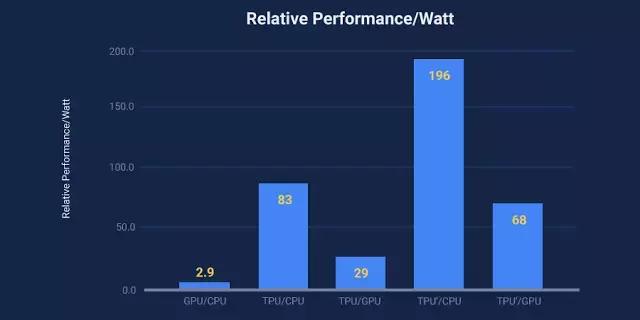
● 我們產品的人工智能負載,主要利用神經網絡的推論功能,其 TPU 處理速度比當前 GPU 和 CPU 要快 15 到 30 倍。
● 較之傳統芯片,TPU 也更加節能,功耗效率(TOPS/Watt)上提升了 30 到 80 倍。
● 驅動這些應用的神經網絡只要求少量的代碼,少的驚人:僅 100 到 1500 行。代碼以 TensorFlow 為基礎。
● 70 多個作者對這篇文章有貢獻。這份報告也真是勞師動眾,很多人參與了設計、證實、實施以及布局類似這樣的系統軟硬件。
TPU 的需求大約真正出現在 6 年之前,那時我們在所有產品之中越來越多的地方已開始使用消耗大量計算資源的深度學習模型;昂貴的計算令人擔憂。假如存在這樣一個場景,其中人們在 1 天中使用谷歌語音進行 3 分鐘搜索,并且我們要在正使用的處理器中為語音識別系統運行深度神經網絡,那么我們就不得不翻倍谷歌數據中心的數量。
TPU 將使我們快速做出預測,并使產品迅速對用戶需求做出回應。TPU 運行在每一次的搜索中;TPU 支持作為谷歌圖像搜索(Google Image Search)、谷歌照片(Google Photo)和谷歌云視覺 API(Google Cloud Vision API)等產品的基礎的精確視覺模型;TPU 將加強谷歌翻譯去年推出的突破性神經翻譯質量的提升;并在谷歌 DeepMind AlphaGo 對李世乭的勝利中發揮了作用,這是計算機首次在古老的圍棋比賽中戰勝世界冠軍。
我們致力于打造最好的基礎架構,并將其共享給所有人。我們期望在未來的數周和數月內分享更多的更新。
論文題目:數據中心的 TPU 性能分析(In-Datacenter Performance Analysis of a Tensor Processing Unit)

摘要:許多架構師相信,現在要想在成本-能耗-性能(cost-energy-performance)上獲得提升,就需要使用特定領域的硬件。這篇論文評估了一款自 2015 年以來就被應用于數據中心的定制化 ASIC,亦即張量處理器(TPU),這款產品可用來加速神經網絡(NN)的推理階段。TPU 的中心是一個 65,536 的 8 位 MAC 矩陣乘法單元,可提供 92 萬億次運算/秒(TOPS)的速度和一個大的(28 MiB)的可用軟件管理的片上內存。相對于 CPU 和 GPU 的隨時間變化的優化方法(高速緩存、無序執行、多線程、多處理、預取……),這種 TPU 的確定性的執行模型(deterministic execution model)能更好地匹配我們的神經網絡應用的 99% 的響應時間需求,因為 CPU 和 GPU 更多的是幫助對吞吐量(throughout)進行平均,而非確保延遲性能。這些特性的缺失有助于解釋為什么盡管 TPU 有極大的 MAC 和大內存,但卻相對小和低功耗。我們將 TPU 和服務器級的英特爾 Haswell CPU 與現在同樣也會在數據中心使用的英偉達 K80 GPU 進行了比較。我們的負載是用高級的 TensorFlow 框架編寫的,并是用了生產級的神經網絡應用(多層感知器、卷積神經網絡和 LSTM),這些應用占到了我們的數據中心的神經網絡推理計算需求的 95%。盡管其中一些應用的利用率比較低,但是平均而言,TPU 大約 15-30 倍快于當前的 GPU 或者 CPU,速度/功率比(TOPS/Watt)大約高 30-80 倍。此外,如果在 TPU 中使用 GPU 的 GDDR5 內存,那么速度(TOPS)還會翻三倍,速度/功率比(TOPS/Watt)能達到 GPU 的 70 倍以及 CPU 的 200 倍。
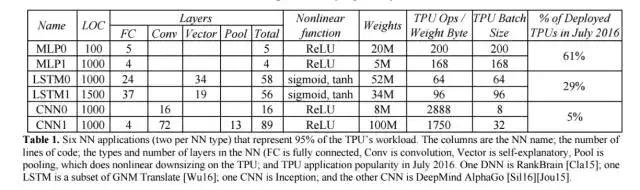
表 1:6 種神經網絡應用(每種神經網絡類型各 2 種)占據了 TPU 負載的 95%。表中的列依次是各種神經網絡、代碼的行數、神經網絡中層的類型和數量(FC 是全連接層、Conv 是卷積層,Vector 是向量層,Pool 是池化層)以及 TPU 在 2016 年 7 月的應用普及程度。RankBrain [Cla15] 使用了 DNN,谷歌神經機器翻譯 [Wu16] 中用到了 LSTM,Inception 用到了 CNN,DeepMind AlphaGo [Sil16][Jou15] 也用到了 CNN。
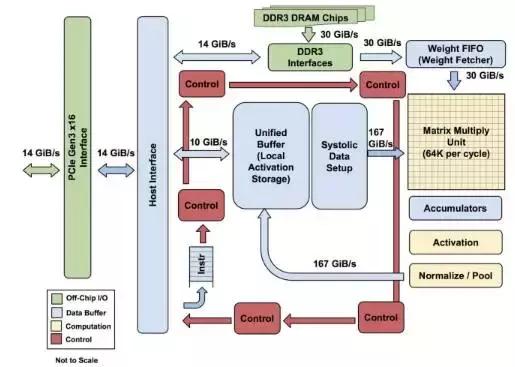
圖 1:TPU 各模塊的框圖。主要計算部分是右上方的黃色矩陣乘法單元。其輸入是藍色的「權重 FIFO」和藍色的統一緩存(Unified Buffer(UB));輸出是藍色的累加器(Accumulators(Acc))。黃色的激活(Activation)單元在Acc中執行流向UB的非線性函數。

評論