Nikko Strom揭秘語音識別技術:Alexa是怎樣煉成的?

Nikko Strom,現任亞馬遜首席科學家,是 Echo 和 Alexa 項目的創始成員,在語音識別技術相關領域有著資深的研究及從業經驗:
本文引用地址:http://www.104case.com/article/201703/345967.htm● 1997 年于瑞典皇家理工學院語音通信實驗室獲得博士學位,后擔任MIT計算機科學實驗室研究員;
● 2000 年加入語音技術初創公司 Tellme Networks;
● 2007 年隨著 Tellme Networks 被微軟收購,加入微軟,推進商業語音識別技術的前沿研究;
● 2011 年加入亞馬遜,擔任首席科學家,領導語音識別及相關領域的深度學習項目。
以下是 Nikko Strom 在本次大會上的演講。
先簡單介紹下我們的產品。如果你買了 Amazon Echo,意味著你可以通過 Alexa 語音識別系統控制它,并與它對話,而且不需要拿遙控器。左邊(下圖)是 Holiday Season,是我們新加入的白色Echo和Dot,相信在座應該有很多人比較偏愛白色的電子產品。
Echo 還可以與沒有內置 Alexa 系統的家電進行連接,如燈具、咖啡機、恒溫器等,只需要喚醒Alexa,就可以讓這些家電設備執行一些命令。此外,開發者還可以通過工具包 Alexa Skills Kit,打造個性化的功能。

現如今,Echo已經進入了數百萬用戶的家中,每天它都在被大量地使用著,也讓我們得到了無法想象的數據量。
深度學習基礎框架
事實上,人耳并非每時每刻都在搜集語音信息,真正在“聽”的時間大約只占 10%,所以一個人成長到 16歲時,他/她所聽到的語音訓練時間大概有 14016 個小時。

回到 Alexa,我們把數千個小時的真實語音訓練數據存儲到 S3 中,使用 EC2 云上的分布式 GPU 集群來訓練深度學習模型。

訓練模型的過程中發現,用 MapReduce 的方法效果并不理想,因為節點之間需要頻繁地保持同步更新,不能再通過增加更多的節點來加速運算。也可以這樣理解,就是GPU集群更新模型的計算速度非常之快,每秒都會更新幾次,每次的更新大約是模型本身的大小。也就是說,每一個線程(Worker)都要跟其它線程同步更新幾百兆的量,而這在一秒鐘的時間里要發生很多次。所以,MapReduce的方法效果并不是很好。

我們在 Alexa 里的解決方法就是,使用幾個逼近算法(Approximations)來減少更新規模,將其壓縮 3個量級。這里是我們一篇 2015 年論文里的圖表,可以看到,隨著GPU線程的增加,訓練速度加快。到 40 個 GUP 線程時,幾乎成直線上升,然后增速有點放緩。80 GPU 線程對應著大約 55 萬幀/秒的速度,每一秒的語音大約包含 100 幀,也就是說這時的一秒鐘可以處理大約90分鐘的語音。前面我提到一個人要花 16 年的時間來學習 1.4 萬小時的語音,而用我們的系統,大約 3 個小時就可以學習完成。
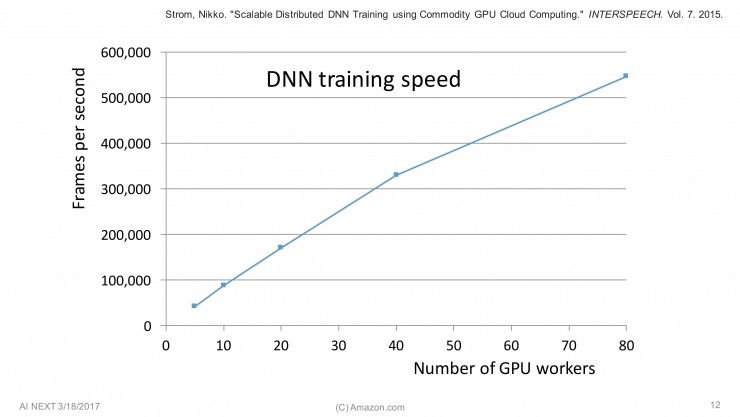
這就是 Alexa 大致的深度學習基礎架構。
聲學模型
大家都知道,語音識別系統框架主要包括四大塊:信號處理、聲學模型、解碼器和后處理。
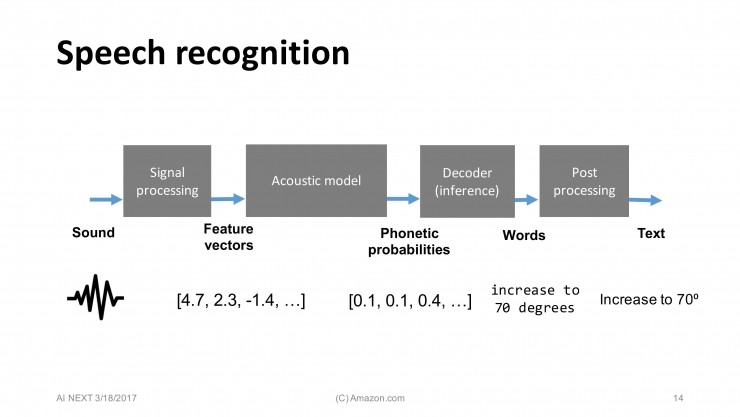
首先我們會將從麥克風收集來的聲音,進行一些信號處理,將語音信號轉化到頻域,從每 10 毫秒的語音中提出一個特征向量,提供給后面的聲學模型。聲學模型負責把音頻分類成不同的音素。接下來就是解碼器,可以得出概率最高一串詞串,最后一步是后處理,就是把單詞組合成容易讀取的文本。
在這幾個步驟中,或多或少都會用到機器學習和深度學習的方法。我今天主要講一下聲學模型的部分。




評論