關于stm32 HardFault_Handler 異常的處理 死機

一般來說運行操作系統
1.開始的時候給ucos分配的堆棧太小了,隨著項目做多了,這類問題一般很容易解決
#define TASK_IO_SIZE
#define TASK_IO_PRIO 6
OS_STK
比如修改300到 1000,做開發的時候 如果ram允許,盡量大些,免的麻煩
2.數組溢出
這類問題一般在通信中,接受數據的時候,特別是長度不定的時候
比如協議為
長度決定了后面的數據多少,在分配接受緩沖的時候
但是我們分配buffer[100],只定義了100,這樣數組就溢出了
所有在放數據之前要對長度進行判斷是否合理,以后 如果有長度 或者索引就要想到溢出。。
3.使用了非法的指針 ,比如空指針 ,編譯對的但是運行就錯了
u8 *p = null;
*p = 1;
4.使用 OS_ENTER_CRITICAL();
使用了 OS_ENTER_CRITICAL(); 卻忘了OS_EXIT_CRITICAL(); 退出臨界區
特別是在這個函數OS_ENTER_CRITICAL();
因此如果調用的話
常見的就上面幾種了,說說硬件異常了 怎么來發現,這個才是主要的
舉個例子:
a.仿真,運行程序的時候點紅色X進入異常
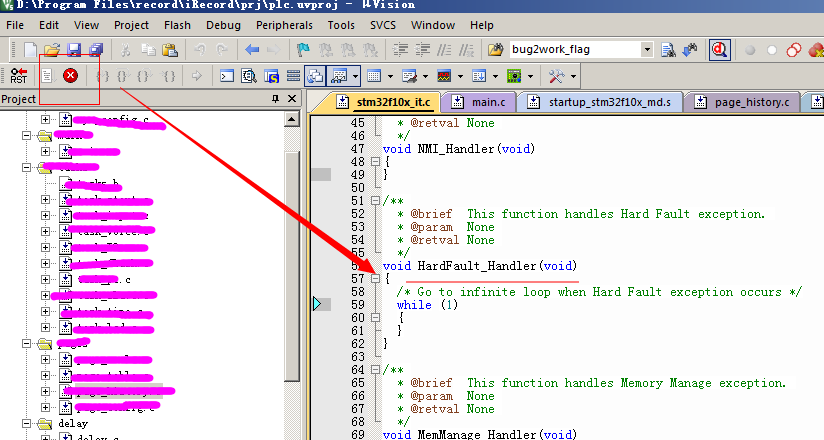
b.調出堆棧窗口,也就是黑匣子
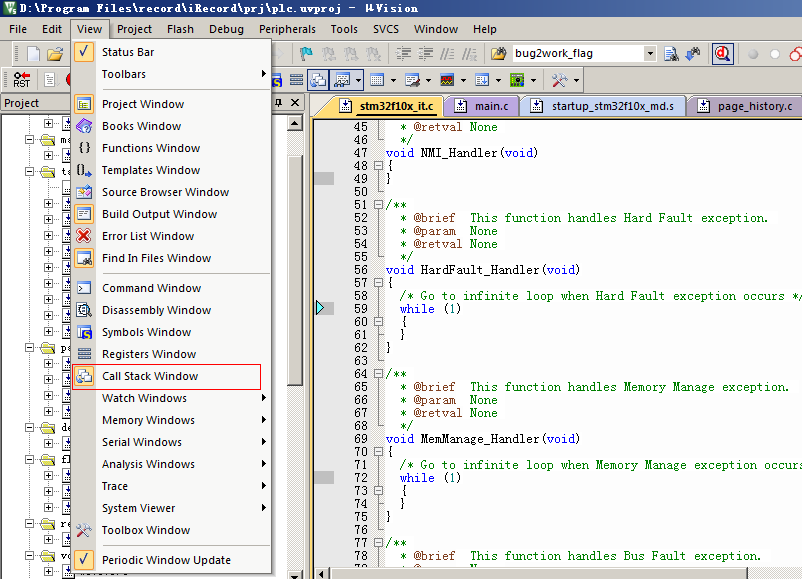
c.查找問題
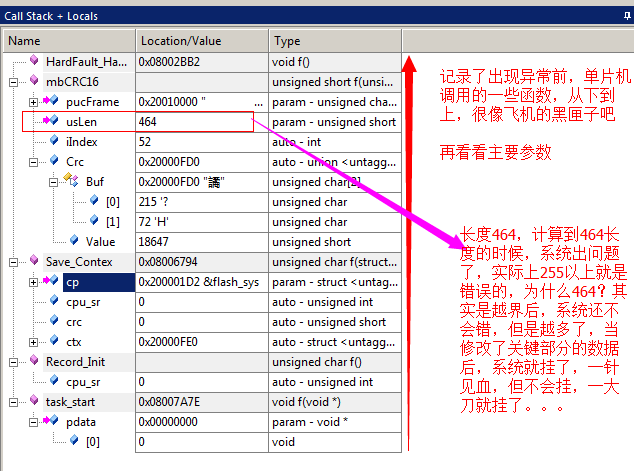
d.找出出錯的函數

e.解決問題
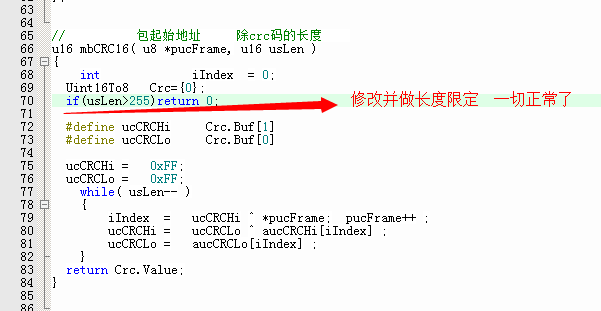
f
很久之前在研究stm32 庫源碼的時候
當然網上也有很多,檢查寄存器LR SP等地址 來反推出最后運行的匯編函數調用地址的,但是肯定沒有上面的直觀。

評論