x86架構和arm架構處理器分析

1.兩種cpu架構:馮洛伊曼和哈佛
本文引用地址:http://www.104case.com/article/201611/317813.htm2.x86架構和arm架構分析
3.x86架構和arm架構功耗探究
一.兩種cpu架構:
目前主流的cpu處理器都采用了馮洛伊曼架構或者哈佛架構,那么這和x86arm架構的關系是什么呢, 馮洛伊曼和哈佛這兩個架構指的是cpu架構,是控制數據和代碼存儲的架構. 而x86和arm架構指的的cpu控制指令的集合,每一個指令代表cpu內部設計的一個硬件電路實現.在具體分析x86和arm架構前先分析下cpu存儲架構:1.哈佛結構:
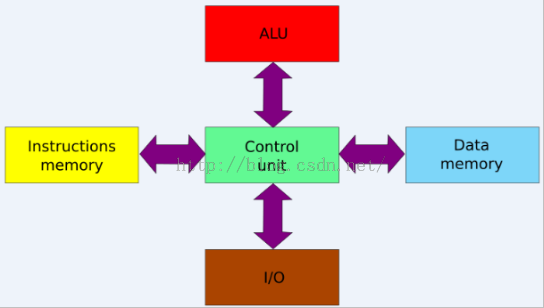
哈佛結構(英語:Harvard architecture):是一種將程序指令存儲和數據存儲分開的存儲器結構。中央處理器首先到程序指令存儲器中讀取程序指令內容,解碼后得到數據地址,再到相應的數據存儲器中讀取數據,并進行下一步的操作(通常是執行)。程序指令存儲和數據存儲分開,可以使指令和數據有不同的數據寬度,如Microchip公司的 PIC16芯片的程序指令是14位寬度,而數據是8位寬度.哈佛結構的微處理器通常具有較高的執行效率。其程序指令和數據指令分開組織和儲存的,執行時可以預先讀取下一條指令。
目前使用哈佛結構的中央處理器和微控制器有很多,除了上面提到的Microchip公司的PIC系列芯片,還有摩托羅拉公司的MC68系列、Zilog公司的Z8系列、ATMEL公司的AVR系列和安謀公司的ARM9、ARM10和ARM11,51單片機也屬于哈佛結構
2.馮·諾伊曼結構:
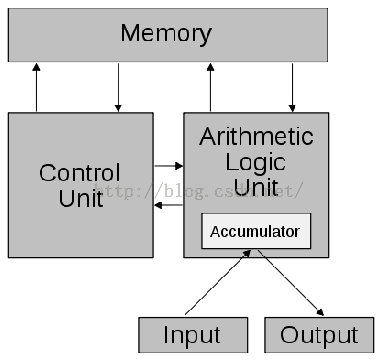
最早的計算機器僅內涵固定用途的程式。例如一個計算器僅有固定的數學計算程式,它不能拿來當作文書處理軟件,更不能拿來玩游戲。若想要改變此機器的程式,你必須更改線路、更改結構甚至重新設計此機器。而儲存程式型電腦的概念改變了這一切。借由創造一組指令集結構,并將所謂的運算轉化成一串程式指令的執行細節,讓此機器更有彈性。借著將指令當成一種特別型態的靜態資料,一臺儲存程式型電腦可輕易改變其程式,并在程控下改變其運算內容。馮·諾伊曼結構與儲存程式型電腦是互相通用的名詞,其用法將于下述。而哈佛結構則是一種將程式資料與普通資料分開儲存的設計概念,但是它并未完全突破馮.諾伊曼架構。
儲存程式型概念也可讓程式執行時自我修改程式的運算內容。本概念的設計動機之一就是可讓程式自行增加內容或改變程式指令的內存位置,因為早期的設計都要使用者手動修改。但隨著索引暫存器與間接位置存取變成硬件結構的必備機制后,本功能就不如以往重要了。而程式自我修改這項特色也被現代程式設計所棄揚,因為它會造成理解與除錯的難度,且現代中央處理器的管線與快取機制會讓此功能效率降低。
從整體而言,將指令當成資料的概念使得組合語言、編譯器與其他自動編程工具得以實現;可以用這些“自動編程的程式”,以人類較易理解的方式編寫程式[1];從局部來看,強調I/O的機器,例如Bitblt,想要修改畫面上的圖樣,以往是認為若沒有客制化硬件就辦不到。但之后顯示這些功能可以借由“執行中編譯”技術而有效達到。
此結構當然有所缺陷,除了下列將述的馮·諾伊曼瓶頸之外,修改程式很可能是非常具傷害性的,無論無意或設計錯誤。在一個簡單的儲存程式型電腦上,一個設計不良的程式可能會傷害自己、其他程式甚或是操作系統,導致當機。緩沖區溢位就是一個典型例子。而創造或更改其他程式的能力也導致了惡意軟件的出現。利用緩沖區溢位,一個惡意程式可以覆蓋呼叫堆棧(Call stack)并覆寫程式碼,并且修改其他程式檔案以造成連鎖破壞。內存保護機制及其他形式的存取控制可以保護意外或惡意的程式碼更動。
評論:
哈佛結構和馮.諾依曼結構都是一種存儲器結構。哈佛結構是將指令存儲器和數據存儲器分開的一種存儲器結構;而馮.諾依曼結構將指令存儲器和數據存儲器合在一起的存儲器結構。哈佛結構與馮·諾依曼結構的最大區別在于馮·諾依曼結構的計算機采用代碼與數據的統一編址,而哈佛結構是獨立編址的,代碼空間與數據空間完全分開。
二.x86架構和arm架構差異點分析:
英文縮寫:
ISA指令集架構,Instruction Set Architecture
CISC復雜指令集計算機,Complex Instruction Set Computer
RISC精簡指令集計算機,Reduced Instruction Set Computer
EPIC顯性并行指令計算,Explicitly Parallel Instruction Computing
MMX多媒體擴展指令集,Multi Media Extended
SSE單指令多數據流擴展,Streaming-Single instruction multiple data-Extensions
1>硬件的功能邏輯實現不同:
什么是架構,我們要明白CPU是一個執行部件,它之所以能執行,也是因為人們在里面制作了執行各種功能的硬件電路,然后再用一定的邏輯讓它按照一定的順序工作, 這樣就能完成人們給它的任務。也就是說,如果把CPU看作一個人,首先它要有正常的工作能力(既執行能力),然后又有足夠的邏輯能力(能明白做事的順 序),最后還要聽的懂別人的話(既指令集),才能正常工作。而這些集中在一起就構成了所謂的“架構”,它可以理解為一套“工具”、“方法”和“規范”的集 合。不同的架構之間,工具可能不同,方法可能不同,規范也可能不同,這也造成了它們之間的不兼容——你給一個意大利泥瓦匠看一份中文寫成的烹飪指南,他當 然不知道應該干什么了。
2>CISC和RISC
cpu對于機器碼的每一個bit的解釋都不同,arm是類risc中比較成功的一種,指令集簡單,所有指令都是32位或者16位的,而cisc的x86不等長,所以指令預測都比risc要難做一些。如果還看不懂,沒關系,我們繼續。從CPU發明到現在,有非常多種架構,從我們熟悉的X86,ARM,到不太熟悉的MIPS,IA64,它們之間的差距都 非常大。但是如果從最基本的邏輯角度來分類的話,它們可以被分為兩大類,即所謂的“復雜指令集”與“精簡指令集”系統,也就是經常看到的“CISC”與 “RISC”。屬于這兩種類中的各種架構之間最大的區別,在于它們的設計者考慮問題方式的不同。我們可以繼續舉個例子,比如說我們要命令一個人吃飯,那么 我們應該怎么命令呢?我們可以直接對他下達“吃飯”的命令,也可以命令他“先拿勺子,然后舀起一勺飯,然后張嘴,然后送到嘴里,最后咽下去”。從這里可以 看到,對于命令別人做事這樣一件事情,不同的人有不同的理解,有人認為,如果我首先給接受命令的人以足夠的訓練,讓他掌握各種復雜技能(即在硬件中實現對 應的復雜功能),那么以后就可以用非常簡單的命令讓他去做很復雜的事情——比如只要說一句“吃飯”,他就會吃飯。但是也有人認為這樣會讓事情變的太復雜, 畢竟接受命令的人要做的事情很復雜,如果你這時候想讓他吃菜怎么辦?難道繼續訓練他吃菜的方法?我們為什么不可以把事情分為許多非常基本的步驟,這樣只需 要接受命令的人懂得很少的基本技能,就可以完成同樣的工作,無非是下達命令的人稍微累一點——比如現在我要他吃菜,只需要把剛剛吃飯命令里的“舀起一勺 飯”改成“舀起一勺菜”,問題就解決了,多么簡單。
這就是“復雜指令集”和“精簡指令集”的邏輯區別。可能有人說,明顯是精簡指令集好啊,但是我們不好去判斷它們之間到底誰好誰壞,因為目前他們兩種指令集 都在蓬勃發展,而且都很成功——X86是復雜指令集(CISC)的代表,而ARM則是精簡指令集(RISC)的代表,甚至ARM的名字就直接表明了它的技 術:Advanced RISC Machine——高級RISC機。
這就是RISC和CISC之間不好直接比較性能的原因,因為它們之間的設計思路差異太大。這樣的思路導致了CISC和RISC分道揚鑣 ——前者更加專注于高性能但同時高功耗的實現,而后者則專注于小尺寸低功耗領域。實際上也有很多事情CISC更加合適,而另外一些事情則是RISC更加合 適,比如在執行高密度的運算任務的時候CISC就更具備優勢,而在執行簡單重復勞動的時候RISC就能占到上風,比如假設我們是在舉辦吃飯大賽,那么 CISC只需要不停的喊“吃飯吃飯吃飯”就行了,而RISC則要一遍一遍重復吃飯流程,負責喊話的人如果嘴巴不夠快(即內存帶寬不夠大),那么RISC就 很難吃的過CISC。但是如果我們只是要兩個人把飯舀出來,那么CISC就麻煩得多,因為CISC里沒有這么簡單的舀飯動作,而RISC就只需要不停喊 “舀飯舀飯舀飯”就OK。
這就是CISC和RISC之間的區別。但是在實際情況中問題要比這復雜許許多多,因為各個陣營的設計者都想要提升自家架構的性能。這里面最普遍的就是所謂 的“發射”概念。什么叫發射?發射就是同時可以執行多少指令的意思,例如雙發射就意味著CPU可以同時拾取兩條指令,三發射則自然就是三條了。現代高級處 理器已經很少有單發射的實現,例如Cortex A8和A9都是雙發射的RISC,而Cortex A15則是三發射。ATOM是雙發射CISC,Core系列甚至做到了四發射——這個方面大家倒是不相上下,但是不要忘了CISC的指令更加復雜,也就意 味著指令更加強大,還是吃飯的例子,CISC只需要1個指令,而RISC需要5個,那么在內存帶寬相同的情況下,CISC能達到的性能是要超過RISC的(就吃飯而言是5倍),而 實際中CISC的Core i處理器內存帶寬已經超過了100GB/s,而ARM還在為10GB/s而苦苦奮斗,一個更加吃帶寬的架構,帶寬卻只有別人的十分之一,性能自然會受到非 常大的制約。為什么說ARM和X86不好比,這也是很重要的一個原因,因為不同的應用對帶寬需求是不同的。一旦遇到帶寬瓶頸,哪怕ARM處理器已經達到了 很高的運算性能,實際上根本發揮不出來,自然也就會落敗了。
說到這兒大家應該也已經明白CISC和RISC的區別和特色了。簡而言之,CISC實際上是以增加處理器本身復雜度作為代價,去換取更高的性能,而 RISC則是將復雜度交給了編譯器,犧牲了程序大小和指令帶寬,換取了簡單和低功耗的硬件實現。但如果事情就這樣發展下去,為了提升性能,CISC的處理 器將越來越大,而RISC需要的內存帶寬則會突破天際,這都是受到技術限制的。所以進十多年來,關于CISC和RISC的區分已經慢慢的在模糊,例如自 P6體系(即Pentium Pro)以來,作為CISC代表的X86架構引入了微碼概念,與此對應的,處理器內部也增加了所謂的譯碼器,負責將傳統的CISC指令“拆包”為更加短小 的微碼(uOPs)。一條CISC指令進來以后,會被譯碼器拆分為數量不等的微碼,然后送入處理器的執行管線——這實際上可以理解為RISC內 核+CISC解碼器。而RISC也引入了指令集這個就邏輯角度而言非常不精簡的東西,來增加運算性能。正常而言,一條X86指令會被拆解為2~4個 uOPs,平均來看就是3個,因此同樣的指令密度下,目前X86的實際指令執行能力應該大約是ARM的3倍左右。不過不要忘了這是基于“同樣指令密度”下 的一個假設,實際上X86可以達到的指令密度是十倍甚至百倍于ARM的。
3>采用不同指令集
最后一個需要考慮的地方就是指令集。這個東西的引入,是為了加速處理器在某些特定應用上性能而設計的,已經有了幾十年的歷史了。而實際上在目前的應用環境 內,起到決定作用的很多時候是指令集而不是CPU核心。X86架構的強大,很多時候也源于指令集的強大,比如我們知道的ATOM,雖然它的X86核心非常 羸弱,但是由于它支持SSE3,在很多時候性能甚至可以超過核心性能遠遠強大于它的Pentium M,這就是指令集的威力。目前X86指令集已經從MMX,發展到了SSE,AVX,而ARM依然還只有簡單而基礎的NEON。它們之間不成比例的差距造成 了實際應用中成百上千倍的性能落差,例如即便是現今最強大的ARM內核依然還在為軟解1080p H.264而奮斗,但一顆普通的中端Core i處理器卻可以用接近十倍播放速度的速度去壓縮1080p H.264視頻。至少在這點上,說PC處理器的性能百倍于ARM是無可辯駁的,而實際中這樣的例子比比皆是。這也是為什么我在之前說平均下來ARM只有 X86幾十分之一的性能的原因。打了這么多字,其實就是為了說明一點,雖然現在ARM很強大,但它距離X86還是非常遙遠,并沒有因為這幾年的進步而縮短,實際上反而在被更快的拉大。畢 竟它們設計的出發點不一樣,因此根本不具備多少可比性,X86無法做到ARM的功耗,而ARM也無法做到X86的性能。這也是為什么ATOM一直以來都不 成功的原因所在——Intel試圖用自己的短處去和別人的長處對抗,結果自然是不太好的,要不是Intel擁有這個星球上最先進的半導體工藝,ATOM根 本都不可能出現。而ARM如果嘗試去和X86拼性能,那結果自然也好不到哪兒去,原因剛剛也解釋過了。不過這也不意味著ARM以后就只能占據低端,畢竟任 何架構都有其優點,一旦有應用針對其進行優化,那么就可以揚長避短。X86的繁榮也正是因為整個世界的資源都針對它進行了優化所致。只要能為ARM找到合 適的應用與適合的領域,未來ARM也未必不可以進入更高的層次
4>尋找方式不同尋址方式也不一樣,這個就得看各個架構的reference manual了。這方面一個比較大的區別是x86使用了分段(實際上在linux中,繞過了分段模式,但是cpu確實是分段的),而arm是分頁。
至于是否馮諾依曼或者哈佛,這個沒有太多爭論的必要,目前為止我所接觸過的純粹哈佛結構的只有51系列的單片機。在arm9以上的帶獨立 icache/dcache的cpu中,從cache的角度來看確實是哈佛結構的,因為icache和dcache和外部總線的接口是截然分離的,而從實 際的外部總線系統設計來看,你依然可以認為是馮諾依曼的,因為代碼和數據共用了外部的amba總線,并且都在一個地址空間中,并沒有真正分離。這樣的設計對于當前的操作系統來說是最合理,最方便的
三.ARM和X86功耗差別:
ARM和X86功耗的差別一直是個很熱的話題.ARM可以做的很低,甚至1瓦都不到.而X86服務器的芯片可以達到100-200瓦,就算是嵌入式處理器 Atom系列也需要幾瓦.很多人說這是指令集的關系.ARM采用精簡指令集,X86采用復雜指令集,前者每條功能簡單,單挑指令耗電低.而后者每條指令復 雜,單個指令耗電高.但是這種解釋很模糊.如果大家都做同樣的事情,完成一個大功能,精簡指令集需要指令較多,而復雜指令集需要指令少,加起來到底誰耗電 多呢.還有,現在處理器普遍采用微指令,大的指令會被拆分成更小的指令,以達到更高的流水線效率.簡單指令集的單條微指令和復雜指令集的單條微指令相比的 話,情況就更復雜.我手頭沒有關于比較的具體數據,但是至少前文所列出關于功耗和指令集相關的解釋不是很有說服力.
今天碰到一個資深人士,總算找到一個比較合理的解釋.
首先,功耗和工藝制程相關. ARM的處理器,不管是哪家,主要是靠臺積電等專業制造商生產的.而Intel的是自己的工廠制造的.一般來說后者比前者的工藝領先一代,也就是2-3 年.如果同樣的設計,造出來的處理器因該是Intel的更緊湊,比如一個是22納米,一個是28納米,同樣功能肯定是22納米的耗電更少.
那為什么反而ARM的比X86耗電少得多呢.這就和另外一個因素相關了,那就是設計.
設計又分為前端和后端設計,前端設計體現了處理器的構架,精簡指令集和復雜指令集的區別是通過前端設計體現的.后端設計處理電壓,時鐘等問題,是耗電的直接因素.
先說下后端怎么影響耗電的.我們都學過,晶體管耗電主要兩個原因,一個是動態功耗,一個是漏電功耗.動態功耗是指晶體管在輸入電壓切換的時候產生的耗電, 而所有的邏輯功能的0/1切換,歸根結底都是時鐘信號的切換.如果時鐘信號保持不變,那么這部分的功耗就為0.這就是所謂的門控時鐘(Clock Gating).而漏電功耗可以通過關掉某個模塊的電源來控制(Power Gating).當然,其中任何一項都會使得時鐘和電源所控制的模塊無法工作.他們的區別在于,門控時鐘的恢復時間較短,而電源控制的時間較長.此外,如 果條單條指令使用多個模塊的功能,在恢復功能的時候,并不是最慢的那個模塊的時間,而可能是幾個模塊時間相加,因為這牽涉到一個上電次序(Power Sequence)的問題,也就是恢復工作時候模塊間是有先后次序的,不遵照這個次序,就無法恢復.而遵照這個次序,就會使得總恢復時間很長.所以在后端 這塊,可以得到一個結論,為了省電,可以關閉一些暫時不會用到的處理器模塊.但是也不能輕易的關閉,否則一旦需要,恢復的話會讓完成某個指令的時間會很 長,總體性能顯然降低.此外,子模塊的門控時鐘和電源開關通常是設計電路時就決定的,對于操作系統是透明的,無法通過軟件來優化.
再來看前端.ARM的處理器有個特點,就是亂序執行能力不如X86.換句話說,就是用戶在使用電腦的時候,他的操作是隨機的,無法預測的,造成了指令也無 法預測.X86為了增強對這種情況下的處理能力,加強了亂序指令的執行.此外,X86還增強了單核的多線程能力.這樣做的缺點就是,無法很有效的關閉和恢 復處理器子模塊,因為一旦關閉,恢復起來就很慢,從而造成低性能.為了保持高性能,就不得不讓大部分的模塊都保持開啟, 并且時鐘也保持切換.這樣做的直接后果就是耗電高.而ARM的指令強在確定次序的執行,并且依靠多核而不是單核多線程來執行.這樣容易保持子模塊和時鐘信 號的關閉,顯然就更省電.
此外,在操作系統這個級別,個人電腦上通常會開很多線程,而移動平臺通常會做優化,只保持必要的線程.這樣使得耗電差距進一步加大.當然,如果X86用在 移動平臺,肯定也會因為線程少而省電.凌動系列(ATOM)專門為這些特性做了優化,在一定程度上降低亂序執行和多線程的處理能力,從而達到省電.
此外,現在移動處理器都是片上系統(SoC)結構,也就是說,處理器之外,圖形,視頻,音頻,網絡等功能都在一個芯片里.這些模塊的打開與關閉就容易預測 的多,并且可以通過軟件來控制.這樣,整體功耗就更加取決于軟件和制造工藝而不是處理機結構.在這點上,X86的處理器占優勢,因為Intel的工藝有很 大優勢,而軟件優化只要去做肯定就可以做到.
以上原因我覺得較好的解釋了ARM和X86的功耗差別.

評論