ARM Thumb Thumb-2指令集

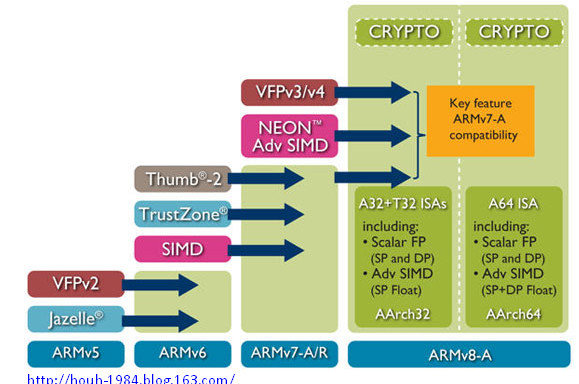
圖1. ARM體系結構演進圖
ARM指令集(A32)
ARM指令集為32位指令集,指令地址必須對齊在4字節邊界,可以實現ARM架構下所有功能。大多數ARM數據處理指令采用的是3地址格式(除了64位乘法指令外),即兩個源操作數和一個結果操作數。
ARM指令分為以下幾種: 一、ARM 存儲器訪問指令 二、ARM 數據處理指令 三、乘法指令 四、跳轉指令 五、ARM協處理器指令 五、ARM 雜項指令 | |||||||||||
所有異常都會使微處理器返回到ARM模式狀態,并在ARM的編程模式中處理。由于ARM微處理器字傳送地址必須可被4整除(即字對準),半字傳送地址必須可被2整除(即半字對準)。而Thumb指令是2個字節長,而不是4個字節,所以,由Thumb執行狀態進入異常時其自然偏移與ARM不同。
Thumb指令集
對于ARM指令來說,所有的指令長度都是32位,并且執行周期大多為單周期,指令都是有條件執行的。每條Thumb指令有相同處理器模型所對應的32位ARM指令。而THUMB 指令的特點如下:
- 不會經常條件執行使用指令:除了跳轉指令 B 有條件執行功能外,其它指令均為無條件執行
- 源寄存器與目標寄存器經常是相同的以減少操作數
- 可用寄存器數量少
- 常數的值比較小
- 不經常用內核中的桶式移位器(barrel shifter)
Thumb指令集是對32位ARM指令集的擴充,它的目標是為了實現更高的代碼密度。Thumb指令集實現的功能只是32位ARM指令集的子集,它僅僅把常用的ARM指令壓縮成16位的指令編碼方式。在指令的執行階段,16位的指令被重新解碼,完成對等的32位指令所實現的功能。與全部用ARM指令集的方式相比,使用Thumb指令可以在代碼密度方面改善大約30%。但是,這種改進是以代碼的效率為代價的。盡管每個Thumb指令都有相對應的ARM指令,但是,相同的功能需要更多的Thumb指令才能完成。因此,當指令預取需要的時間沒有區別時,ARM指令相對Thumb指令具有更好的性能。與ARM指令集相比較,Thumb指令集中的數據處理指令的操作數仍然是32位,指令地址也為32位,但Thumb指令集為實現16位的指令長度,舍棄了ARM指令集的一些特性,若使用32位的存儲器,ARM代碼比Thumb代碼快約40%,若使用16位的存儲器,Thumb代碼比ARM代碼快約40%~50%.顯然,ARM指令集和Thumb指令集各有其優點,若對系統的性能有較高要求,應使用32位的存儲系統和ARM指令集,若對系統的成本及功耗有較高要求,則應使用16位的存儲系統和Thumb指令集。當然,若兩者結合使用,充分發揮其各自的優點,會取得更好的效果。 在編寫Thumb指令時,先要使用偽指令CODE16聲明,編寫ARM指令時,則可使用CODE32偽指令聲明。Thumb 指令集沒有協處理器指令,信號量指令以及訪問 CPSR 或 SPSR 的指令,沒有乘加指令及 64 位乘法指令等,且指令的第二操作數受到限制;大多數 Thumb 數據處理指令采用2地址格式.Thumb指令集與 ARM 指令的區別一般有如下幾點: | |
Thumb-2指令集(T32)
THUMB-2指令集是介紹ARM CPU中的THUMB的擴展,新指令對性能和代碼密度的改進,從而提供低功耗,高性能的最優設計,更好的平衡代碼性能和系統成本,Thumb-2是混合的16-bit和32-bit指令格式,其16位指令在運行時被轉換為32-bit指令執行。Thumb-2指令集在Thumb指令的基礎上做了如下的擴充:增加了一些新的16位Thumb指令來改進程序的執行流程,增加了一些新的32位Thumb指令以實現一些ARM指令的專有功能32位的ARM 指令也得到了擴充,增加了一些新的指令來改善代碼性能和數據處理的效率給Thumb指令集增加32位指令就解決了之前Thumb指令集不能訪問協處理器、特權指令和特殊功能指令的局限。新的Thumb指令集現在可以實現所有的功能,這樣就不需要在ARM/Thumb狀態之間反復切換了,代碼密度和性能得到顯著的提高。Thumb-2的出現使開發者只使用一套指令集就享有高性能、高代碼密度,不再需要在不同指令之間反復切換了。開發者只需要關注對整體性能影響最大的那部分代碼,其他的部分可以使用缺省的編譯配置就可以了。
新的Thumb-2技術可以帶來很多好處:
可以實現ARM指令的所有功能
增加了12條新指令,可以改進代碼性能和代碼密度之間的平衡
代碼性能達到了純ARM代碼性能的98%
相對ARM代碼,Thumb-2代碼的大小僅有其74%
代碼密度比現有的Thumb指令集更高:代碼大小平均降低5%;代碼速度平均提高2-3%
為了提高處理壓縮數據結構的效率,新的ARM架構為Thumb-2指令集和ARM指令集增加了一些新的指令來實現比特位的插入和抽取。為了增加處理常數的靈活性,新架構中為Thumb-2指令集和ARM指令集增加了兩條新的指令。MOVW可以把一個16-bit常數加載到寄存器中,并用0填充高比特位;另一條指令MOVT可以把一個16-bit常數加載到寄存器高16比特中。這兩條指令組合使用就可以把一個32-bit常數加載到寄存器中。通常在訪問外設寄存器之前會把外設的基址加載到寄存器中,這時就會需要把32-bit常數加載到寄存器中。在之前的架構中需要通過literal pools來完成這樣的操作,對32位常量的訪問一般通過PC相對尋址來實現。Literal pools可以保存常量并簡化訪問這些常量的代碼,但是,在Harvard架構的處理器中會引起額外的開銷。這些開銷來自于需要額外的時鐘周期來使數據端 口能夠對指令流進行訪問;這種訪問可能是需要把指令流加載的數據緩存中,或者從數據端口直接訪問指令存儲器。將32位常量分成16比特的兩個部分保存在兩條指令中,意味著數據直接在指令流中,不再需要通過數據端口來訪問了。相對于literal pool方式,這種解決辦法可以消除通過數據端口訪問指令流的額外開銷,進而提高性能,降低功耗。
ARM/Thumb狀態切換
在基于ARM 處理器的嵌入式開發中,為了增強系統的靈活性以及提高系統的整體性能經常需要使用16 位的Thumb 指令,所以需要在ARM 和Thumb 狀態之間來切換(Interworking)微處理器狀態。只要遵循ATPCS調用規則,Thumb子程序和ARM子程序就可以互相調用。首先介紹切換(Interwoking)的基本概念及切換時的子函數調用。
ARM處理器總是從ARM狀態開始執行。因而,如果要在調試器中運行Thumb程序,必須為該Thumb程序添加一個ARM程序頭,然后再切換到Thumb狀態,調用該Thumb程序。
- Thumb狀態 BX Rn
- ARM狀態 BX
Rn
其中Rn可以是寄存器R0—R15中的任意一個。指令可以通過將寄存器Rn的內容拷貝到程序計數器PC來完成在4Gbyte地址空間中的絕對跳轉,而狀態切換是由寄存器Rn的最低位來指定的,如果操作數寄存器的狀態位Bit0=0,則進入ARM狀態,如果Bit0=1,則進入Thumb狀態。在非Interworking函數調用中,調用函數使用BL(Branch with Link)指令,即將返回地址保存在連接寄存器LR中,同時跳轉到被調用的子函數程序入口。從子函數返回時執行指令 MOV PC, LR(當然也可能是其他形式的指令,如出棧指令)將LR值直接放入PC中,從而返回到調用函數中的下一條指令的地址,然后繼續執行程序。在Interworking函數的調用中,需要在編譯時對此函數所在的源程序指定編譯開關選項:-apcs / interwork ,即保證程序遵守ARM/Thumb程序混合使用的ATPCS規則。一般來說,這時生成的目標代碼會增加2%左右。這樣在編譯器(compiler)處理這個函數時就會用BX 指令取代MOV PC,LR指令,而且連接器(linker)會自動的產生一小段代碼(veneers)來改變處理器狀態(ARM/Thumb),對于C/C++程序來說,當編譯時如果增加 –apcs/interwork 選項,那就是告訴連接器自動增加一小段代碼(veneer)來實現函數調用時ARM/Thumb的狀態切換。但是對于使用C程序中的Interwork選項,需要注意的是:
- 對于一個C /C++源程序中不能同時包含ARM/Thumb指令;
- 如果C/C++程序間接的調用另一種指令系統下的子程序,編譯該程序時需要增加-apcs/interwork選項;
- 編譯用于交互工作的ARM C代碼: armcc -apcs/interwork
- 編譯用于交互工作的Thumb C代碼:tcc -apcs/interwork
- 如果調用程序和被調用程序是不同的指令,而被調用程序是Non-Interworking代碼,這時不要使用函數指針來調用該被調用程序。
對于匯編程序來說,如果本代碼是被調用的函數,則需按照以下步驟處理:
- 編譯時增加-apcs/interwork 選項;ARM匯編armasm -32 -apcs /interwork;Thumb匯編代碼:armasm -16 -apcs /interwork;
- 在入口處保護返回地址(lr)以及寄存器(r0-r7,r8-r12(ARM))
- 返回前恢復保護的寄存器
- 用BX來返回;
- EXPORT本函數名;
如果本代碼是調用函數,那就只需要用BL指令來實現子函數的調用即可,也就是正常的處理。當然,用戶也可以自己來編寫這些狀態切換程序,這樣執行代碼的效率會更高些。對于C/C++程序和匯編程序的相互調用同樣需要遵守以上的規則。另外,在實際應用中,如果要在ARM/Thumb狀態間來切換程序,最好的辦法是所有的函數在編譯時都增加 -apcs/interwork選項。關于匯編代碼,也可在程序中使用CODE32或CODE16命令明確告知匯編程序下面的代碼是ARM代碼還是Thumb代碼,這樣在匯編時則無需使用-32、-16選項;當然也可在單個匯編原文件中混合使用ARM以及Thumb代碼,這是需要使用CODE32以及CODE16命令,并且需要注意狀態的切換,使用BX Rn,根據Rn的Bit[0]來確定目標是ARM代碼還是Thumb代碼。如AREA Init,CODE,READONLY CODE32;通知編譯器其后的指令為32位的ARM指令。
前面所提到的內容是針對ARM微處理器內核為V4T架構時的切換情況,而對于V5TE架構的ARM內核,除了完全支持V4T架構的代碼(具有veneers)外,代碼在連接時不再增加veneers,而是使用新的指令BLX(Branch and Link with Exchang)來實現狀態切換。這條指令完成完成的任務是:在跳轉時將返回的指令地址保存在LR寄存器中,同時將PC中的最低位的值拷貝到CPSR寄存器中的T位,從而改變處理器狀態(Exchange)。一般來說,對于調用函數使用BLX指令即可,被調用函數則與V4T架構相同,也是使用BX指令來返回。
ARM/Thumb代碼性能比較
前面提到Thumb代碼所需的存儲空間約為ARM代碼的60%~70%;Thumb代碼使用的指令數比ARM代碼少約30%~40%;若使用32位的存儲器,ARM代碼比Thumb代碼速約40%;若使用16位的存儲器,Thumb代碼比ARM代碼速約40%~50%;與ARM代碼相比,使用Thumb代碼,存儲器的過耗會下降約30%。下面是arm-linux-gcc編譯器采用不同的編譯選擇對armv7-a,、thumb-2 和thumb-1指令集編譯CoreMark的測試結果,結果如下:
- 最好的編譯選項:-O3 -funroll-loops -marm -march=armv5te -mtune=cortex-a8
- armv7-a指令集最好的編譯選項:-O3 -funroll-loops -marm -march=armv7-a -mtune=cortex-a8 95.2%
- Thumb-2指令集最好的編譯選項:-O3 -funroll-loops -mthumb -march=armv7-a -mtune=cortex-a888.7%
- Thumb-1指令集最好的編譯選項:-O2 -mthumb -march=armv5te -mtune=cortex-a8 66.4%
- Cortex-A9是Cortex-A8的tune的99.5%
- 默認選項-O2 -mthumb -march=armv7-a 性能比為80.8%
Top of Form
Score | Optimisation | Unroll? | ISA | Arch | Tune | % of best |
5634.6 | -O3 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 100.0% |
5607.7 | -O3 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 99.5% |
5601.5 | -O2 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 99.4% |
5580.0 | -O3 | -marm | -march=armv5te | -mtune=cortex-a8 | 99.0% | |
5548.6 | -O3 | -marm | -march=armv5te | -mtune=cortex-a9 | 98.5% | |
5505.1 | -O2 | -marm | -march=armv5te | -mtune=cortex-a8 | 97.7% | |
5427.4 | -O2 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 96.3% |
5386.5 | -O3 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 95.6% |
5364.4 | -O3 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 95.2% |
5332.3 | -O2 | -marm | -march=armv5te | -mtune=cortex-a9 | 94.6% | |
5330.8 | -O3 | -marm | -march=armv7-a | -mtune=cortex-a8 | 94.6% | |
5283.7 | -O3 | -marm | -march=armv7-a | -mtune=cortex-a9 | 93.8% | |
5253.5 | -O2 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 93.2% |
5066.5 | -O2 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 89.9% |
4996.6 | -O3 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 88.7% |
4995.6 | -O3 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 88.7% |
4947.2 | -O3 | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 87.8% | |
4858.3 | -O2 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 86.2% |
4774.8 | -O2 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 84.7% |
4763.8 | -O2 | -marm | -march=armv7-a | -mtune=cortex-a9 | 84.5% | |
4737.8 | -Os | -marm | -march=armv5te | -mtune=cortex-a8 | 84.1% | |
4731.1 | -O2 | -marm | -march=armv7-a | -mtune=cortex-a8 | 84.0% | |
4688.6 | -O3 | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 83.2% | |
4665.6 | -Os | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 82.8% |
4630.7 | -Os | -marm | -march=armv5te | -mtune=cortex-a9 | 82.2% | |
4595.6 | -Os | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 81.6% |
4562.7 | -Os | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 81.0% |
4551.7 | -O2 | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 80.8% | |
4521.5 | -Os | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 80.2% |
4519.8 | -Os | -marm | -march=armv7-a | -mtune=cortex-a8 | 80.2% | |
4500.8 | -Os | -marm | -march=armv7-a | -mtune=cortex-a9 | 79.9% | |
4237.6 | -O2 | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 75.2% | |
3739.7 | -O2 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 66.4% |
3730.6 | -O2 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 66.2% |
3658.8 | -Os | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 64.9% | |
3657.0 | -Os | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 64.9% |
3629.3 | -O2 | -mthumb | -march=armv5te | -mtune=cortex-a8 | 64.4% | |
3585.1 | -Os | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 63.6% | |
3580.8 | -Os | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 63.6% |
3522.2 | -O3 | -mthumb | -march=armv5te | -mtune=cortex-a8 | 62.5% | |
3473.0 | -O2 | -mthumb | -march=armv5te | -mtune=cortex-a9 | 61.6% | |
3338.9 | -O3 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 59.3% |
3219.1 | -O3 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 57.1% |
3170.6 | -O3 | -mthumb | -march=armv5te | -mtune=cortex-a9 | 56.3% | |
2753.7 | -Os | -mthumb | -march=armv5te | -mtune=cortex-a8 | 48.9% | |
2748.6 | -Os | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 48.8% |
2747.4 | -Os | -mthumb | -march=armv5te | -mtune=cortex-a9 | 48.8% | |
2743.7 | -Os | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 48.7% |
Bottom of Form
http://lion3875.blog.51cto.com/2911026/532719
http://www.cnx-software.com/2011/04/22/compile-with-arm-thumb2-reduce-memory-footprint-and-improve-performance/#ixzz1qTCwHRc4
https://wiki.linaro.org/MichaelHope/Sandbox/CoreMark1
http://blog.csdn.net/itismine/archive/2009/11/01/4753701.aspx
http://hi.baidu.com/yzx408/blog/item/a050741180944c1cb8127b79.html
http://houh-1984.blog.163.com/
32位RISC芯片ARM 體系結構支持兩種指令集:32位的ARM指令集執行效率高,對ARM體系架構所有功能的完整支持;16位的Thumb指令集是ARM指令集的子集并以良好的代碼密度著稱。如果拋開預取指令時間不計,ARM指令相對Thumb指令將有更好的運行性能(預取指令時需要根據指令地址偏移量來取指, ARM支持更大的地址偏移量而比較耗時)。最近ARM公司推出的的Thumb-2/Thumb2指令集據稱是上述兩種特性的綜合,是ARM指令集的性能和Thumb指令集的代碼密度的折中。號稱達到98%的ARM性能而又能降低代碼密度達30%。在目前的大多數ARM應用中依然采用ARM + Thumb代碼的混雜模式。ARM code對應的CPU(ARM處理器)工作狀態稱為ARM State,Thumb對應的稱之為Thumb State,這兩種狀態的不同主要通過CPSR[bit 5]區別。CPSR(當前程序狀態寄存器)保存了處理器的當前工作狀態,[bit 5]也被稱為T bit。對于所有帶有J標志的處理器核,比如ARM926EJ-S和ARM1136J-S,J(Jazelle)代表ARM核中集成了Jazelle技 術。CPSR[bit24]則被成為J bit,如果這位為1,則代表當前CPU工作在Java State下而CPU的取指和解碼都是直接操作Java操作數棧。當然要生成Jazelle支持的字節碼需要特殊的Java編譯器和JVM,一般由第三方 平臺軟件廠商提供,比如日本的Aplix公司。在ARM處理器的運行過程中,匯編指令BX以及BLX可以完成ARM State和Thumb State之間的切換(BXJ和BLXJ完成ARM/Thumb State和Java State之間的切換)。但如果程序有一部分工作在ARM工作狀態下,一部分工作在Thumb工作狀態下,而這兩段代碼卻有交互調用,則在編譯C/C++和匯編源文件時要 加上 -apcs /interwork選項。ARM公司的ADS(ARM Developer Suite,-apcs /interwork)和RealView的RVDS(RealView Developer Suite,--apcs /interwork) 都支持這樣的編譯選項,他們會在鏈接時自動檢測函數之間的調用關系和工作狀態提供粘合劑(Veneers)以便程序能夠在不同的工作狀態下切換。arm-linux-gcc編譯器個別版本不支持這個選項,所以在開發ARM + Linux平臺下使用的程序時應該注意到這個問題。最后比較了arm-linux-gcc編譯器下ARM(armv7-a)、Thumb-1、Thumb-2指令集以及armv5te、Cortex-A9與Cortex-A8的tune選項效率性能和代碼密度。

評論