設計大吞吐量、實時SoC系統的最佳實踐

現代SoC軟件通常包括多種應用,從汽車發動機控制等硬件實時應用,到HD視頻流等大吞吐量應用。隨著現代SoC向大吞吐量系統的快速發展,處理器內核數量不斷增加,寬帶互聯也越來越多,導致混合系統設計成為挑戰。在這類系統中實現硬件實時—μs量級響應,抖動不到1μs,需要仔細的綜合考慮分析和系統劃分。隨著SoC的復雜度越來越高,將來的驗證策略也必須納入考慮范圍。
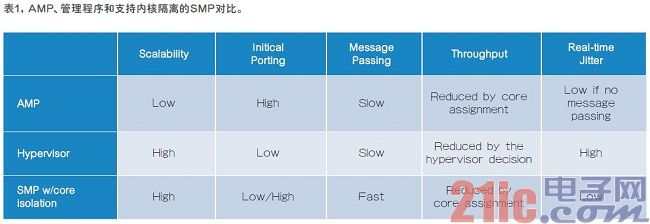
本文引用地址:http://www.104case.com/article/201610/308406.htm這類系統設計主要有三種方法—非對稱多處理(AMP)、管理程序,以及支持內核隔離的對稱多處理(SMP)(主要的對比見表1),系統設計人員可以從中選擇一種方法來優化混合SoC系統。
非對稱多處理
AMP實際是基于物理上不同的處理器內核的多操作系統(OS)端口。一個例子是,在第一個內核上運行專門用于處理實時任務的裸金屬OS,在其他內核上運行嵌入式Linux等完整的OS。很多時候,最初將OS導入到內核中非常簡單,但是,在啟動代碼和資源管理上很容易出錯,例如,存儲器、高速緩存和外設等。當多個OS訪問相同的外設時,行為會是不確定的,調試起來可能非常耗時。通常要求仔細的保護ARM TrustZone等體系結構不受影響。
更復雜的是,在OS之間傳遞消息要求存儲器共享,一起采用其他保護手段進行管理。不同的OS之間通常不會共享高速緩存。要通過非高速緩存區來傳遞消息,對于總體性能而言,增加了延時和抖動。從可擴展角度看,隨著內核數量的增加,需要進行多次重新導入,使軟件體系結構較差。
監控程序
管理程序是直接在硬件上運行的底層軟件,在其上可管理多個獨立的OS。最初的導入與AMP相似,而其優勢在于管理程序隱藏了資源管理和消息傳遞中不重要的細節。缺點是由于吞吐量和實時性能要求,增加了額外的軟件層,導致出現性能開銷。
對稱多處理
支持內核隔離的SMP在多個內核上運行一個OS,支持在內部劃分內核。一個例子是讓SMP OS在第一個內核上分配實時應用程序,在其他的內核上運行非實時應用程序。隨著內核數量的增加,SMP OS可以設計無縫導入,因此,這一方法的可擴展性比較好。所有內核都是由一個OS管理的,因此,內核之間可以在L1數據高速緩存級上傳遞消息,通信速度更快,抖動 更低。
通過內核隔離,可以保留一個內核用于硬件實時應用,以屏蔽其他大吞吐量內核的影響,保持了低抖動和實時數據響應。這樣,設計人員可以考慮使用哪一個OS,而不用重新設計容易出錯的底層軟件來管理多個OS。因此,這一般是很好的軟件體系結構決定。如果從多個OS開始,最初的導入會需要一些付出。但是,從一個SMP體系結構開始會省很多事。
通過SMP優化大吞吐量、實時SoC
基于對各種方法的分析,支持內核隔離的SMP是最好的體系結構,優化了大吞吐量、實時SoC系統。我們考慮的體系結構與圖3的系統相似,其中,I/O數據輸入到SoC中,處理器對其進行計算,送回至I/O,滿足低抖動和低延時實時響應要求。此外,SoC包括了多個內核,可同時運行其他吞吐量較大的應用程序。
首先,需要理解一個實時響應(循環時間)由哪些組成:
1.從一個I/O,將新數據傳送至系統存儲器(DMA)。
2.處理器探測系統存儲器中的新數據 (內核隔離)。
3.將數據復制到私有存儲器(memcpy)。
4.對數據進行計算。
5.將結果復制回系統存儲器(memcpy)。
6.將結果傳送回I/O(DMA)。
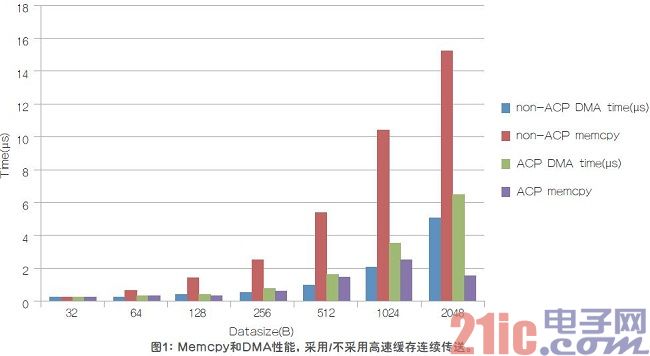
抖動和延時是6個步驟的累積,因此,需要優化每一個步驟。采用支持內核隔離的VxWorks等RTOS,可以在納秒范圍內完成輪詢/中斷響應(步驟2)。數據計算也是專用的,具有很好的可預測性(步驟4)。因此,我們的重點是綜合考慮直接存儲器訪問(DMA)和memcpy(步驟1/3/5/6)。主要有兩種方法來傳送數據:高速緩存連續傳送,以及不支持高速緩沖連續的傳送。這兩種方法在DMA和memcpy上的響應有很大的不同。如圖1所示,雖然高速緩存連續傳送(使用ARM高速緩存連續端口(ACP))導致DMA需要較長的通路,但處理器只需要訪問L1高速緩存就可以獲得所傳送的數據。因此,使用高速緩存連續傳送的memcpy時間要少很多,但是DMA性能會有些劣化。對于設計人員而言,由于是直接高速緩存訪問,因此,高速緩存連續傳送的延時更短,抖動 更小。
案例研究:SoC設計最佳實踐
可以使用Cyclone V SoC FPGA開發套件,通過參考設計來演示一個完整的系統。器件在一個芯片中包括了一個雙核32ARM Cortex-A9內核子系統(HPS)和一個28nm FPGA。下面總結了硬件和軟件體系結構,如圖2所示。
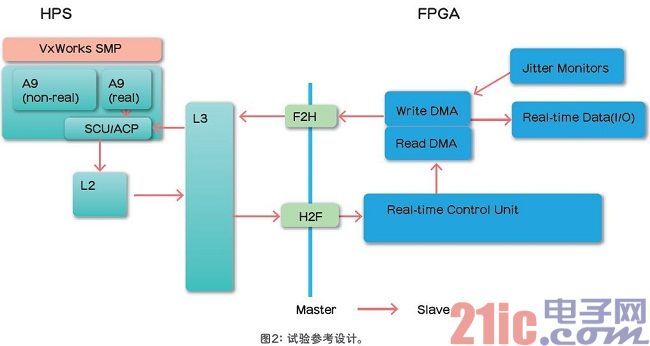
硬件體系結構
·兩個DMA,將數據從FPGA I/O傳送至ARM處理器,反之亦然。
·兩個DMA都連接至ACP,實現數據在ARM處理器高速緩存的直接傳送。
·實時控制單元IP,以盡可能快的方式啟動ARM處理器和DMA引擎之間的消息傳遞。
·抖動監視器直接探測DMA信號,采集實時性能和抖動,精度在±6.7ns以內。
軟件體系結構
·在雙核ARM處理器上的VxWorks實時OS運行在SMP模式下。
·內核隔離,用于在第一個內核上分配實時應用程序,在第二個內核上分配其他的非 實時應用程序。
·實時應用程序連續從I/O讀取數據,計算,然后將結果發送回I/O。
·當連續運行FTP傳輸并對數據加密時,非實時應用程序加重了對ARM內核和其它 I/O性能的要求。
結果
在長度不同的數據上運行實驗,長度從32 字節直至2,048字節。為了采集循環時間的直方圖,來分析抖動(最大和最小循環時間之間的不同),每一長度都要運行數百萬次。如圖3所示,即使是在第二個內核上運行數據流負載很大的FTP,經過數百萬次的測試,延時也在微秒級,而抖動不到300ps。長度不同,會有些抖動擺動,但是可控制在200ps內,并不明顯。
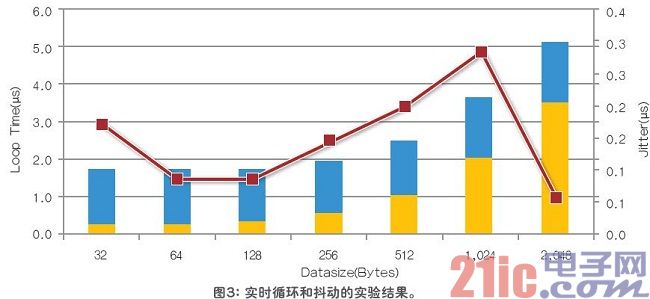
相同的FTP應用程序也運行在VxWorks SMP上,使用了兩個內核,速度提高了近2倍。因此,這一方法并沒有劣化吞吐量,是吞吐量和硬件實時應用程序的折中選擇。但是,由于對內核進行了硬件劃分,不能夠靈活的增加內核數,因此,AMP解決方案也同樣有一些劣化。
結論
設計一個支持大吞吐量和實時應用程序的均衡SoC系統需要進行很多綜合考慮,例如:
·DMA數據傳送。
·連續高速緩存。
·處理器內核與DMA之間的消息傳遞。
·OS劃分。
·軟件能夠隨著處理器內核數量的增加而進行擴展。
在此次實驗中,我們展示了一個“最佳實踐”系統設計,它使用了支持內核隔離和高速緩存連續傳送的SMP,實現了低延時、低抖動實時性能,同時軟件能夠擴展應用到未來幾代的SoC產品中。

評論