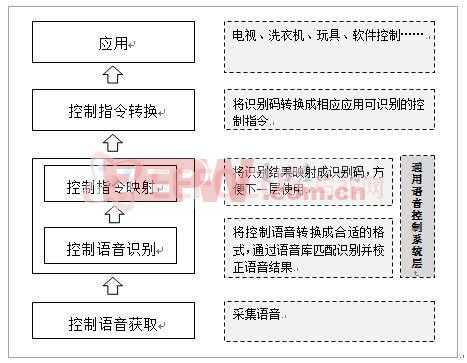
基于聽覺特性的聲紋識別系統的研究


在本文的實驗系統中,語音特征參數依次使用了12階LPCC以及12階MFCC。最后選定12階MFCC參數。本課題建立的是與文本有關的聲紋身份確認系統,用于測試模型是連續CHMM模型。
實驗中我們用的是30 ms的漢明窗,依次計算它的特征參數,分別使用了12階LPCC和12階MFCC(24個Mel濾波器,語音信號的幀長度為256,信號的采樣頻率為8 000 Hz)和由此推導出的一階MFCC差分參數。LPCC特征和MFCC特征識別率比較如表4所示。

表4顯示了在測試人數為10人時,在相同的幀長下,MFCC特征的識別性能高于LPCC特征。這個結論又一次證明了倒譜特征的可區分性測度優于LPCC特征。
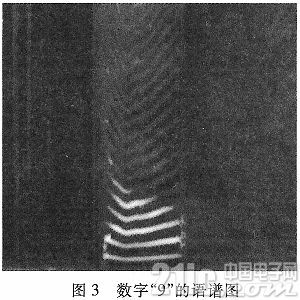
實驗中,我們把第一個說話人的語音“9”,作為實驗研究樣本。圖2是數字“9”的語音波形圖,圖3是數字“9”的語譜圖。

MFCC參數是按幀計算的,在這里語音幀長度是256,信號采樣頻率是8 kHz,采用24個濾波器,MFCC特征階數是12。MFCC的優點是在噪聲的環境下,可以表現出對環境更強的魯棒性。接下來一步要做的是對語音特征矢量序列進行矢量量化,矢量量化的數據壓縮效果相當好,因此進行語音處理經常要用到。在本文的實驗中,采用LBG法聚類生成碼書。矢量量化之后這些語音特征參數就轉變成語音模型。緊接著可以開始進行下一步的操作。
在訓練階段,對數字1~9建立HMM模型,就要對10個人進行每個數字10遍訓練。第一天訓練,第二天檢測。每天一遍,一共兩遍,首先把語音信號做端點檢測,然后根據特征量計算出MFCC系數序列后,這里要用Baum-Welch算法建立各個說話人的HMM模型庫。測試階段,先保持和訓練階段一樣,提取說話人測試語音中的特征矢量,然后根據維特比算法,并以各個說話人的HMM模板為參照,計算出來該輸入序列的生成概率,根據最大的輸出概率進行判決結果。對于本課題研究的身份確認系統,把概率值與判決門限相比較,其值大于或等于判決門限的聲音作為受測者本人的聲音被接受,小于門限的被拒絕。
2.2 實驗結果分析
本文的實驗是與文本有關的說話人身份確認系統。在實驗中,分別按照不同人數進行訓練,但是測試語音數保持不變。任意抽3個人朗讀數字,在隨后的實驗中我們依次確定實驗人數為5,7和10時,這時可以看出識別率會有一些大的差異。其結果如表5所示。
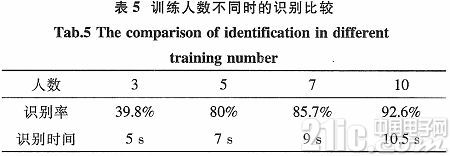
實驗中的語音特征是MFCC,所用模型是連續CHMM,每一數字模型有4個狀態。在這個身份確認系統中,在二值判定的前提下,確認受測者是否是之前所認定的某人。從表5可以看到識別的時間比較短,當有10個人訓練時,識別率最大。為了訓練出可靠的參數模型,必須加大訓練集的數據。本實驗由于條件限制,實驗語音模板庫比較小,訓練數據不太充足,影響系統的一定性能。當訓練數據足夠大時,得修改補充一下程序的流程。本實驗中系統的識別率達到了90%以上。
3 結論
本文的實驗達到了預期的實驗效果,基本完成了身份確認的目標。但是針對語音的特征提取和模式匹配,在實驗中難免會出現一些誤差,出現誤認識和拒認識的偏差。對于說話人確認系統,雖然說從理論上來說,識別率和登錄的說話者量無關,但是實際上對于二值判定的說話人確認系統也會隨著登錄人數的增減而有所改變,怎么樣才能確保有足夠多的登錄者,登錄到說話人確認系統中,而它的識別率問題仍然是一個很大的課題。



評論