基于聽(tīng)覺(jué)特性的聲紋識(shí)別系統(tǒng)的研究

聲紋識(shí)別技術(shù)(說(shuō)話人識(shí)別技術(shù))是一種生物認(rèn)證技術(shù),也是一項(xiàng)根據(jù)說(shuō)話人波形反映其生理和行為特征的語(yǔ)音參數(shù)來(lái)自動(dòng)識(shí)別測(cè)試的說(shuō)話人身份的技術(shù)。
本文引用地址:http://www.104case.com/article/201609/303780.htm在未來(lái)的生活中,說(shuō)話人識(shí)別將會(huì)以它自身獨(dú)特的便捷性,實(shí)惠性和精準(zhǔn)性受人矚目,并且逐漸普及在生物認(rèn)證技術(shù)領(lǐng)域。
說(shuō)話人識(shí)別首要錄制聲音樣本和提取語(yǔ)音特征參數(shù),再把它們保存在數(shù)據(jù)庫(kù)中,最后把準(zhǔn)備驗(yàn)證的聲音和數(shù)據(jù)庫(kù)中的語(yǔ)音特征相匹配,利用匹配結(jié)果相似度來(lái)獲得說(shuō)話人的身份。
1 常用語(yǔ)音庫(kù)
目前,世界各國(guó)都很重視建設(shè)語(yǔ)音數(shù)據(jù)庫(kù)。最具代表的是美國(guó)建立的LDC(Linguistic Data Consortium)和OGI(Oregon Graduate Inst itute),以及歐洲國(guó)家建立的ELRA(European Language Resollces Association)組織。這些組織都是長(zhǎng)期研究語(yǔ)音信號(hào)處理技術(shù)的。他們開(kāi)發(fā)出規(guī)模巨大的語(yǔ)音研究資源。
第一個(gè)高質(zhì)、大容量、高可信度的聲音數(shù)據(jù)庫(kù)是YOHO數(shù)據(jù)庫(kù)。表1是YOHO說(shuō)話人數(shù)據(jù)庫(kù)。它是經(jīng)過(guò)數(shù)字化的數(shù)據(jù)庫(kù),其輸入特征參照了第三代安全終端單位(STU—III)的安全語(yǔ)音電話。設(shè)計(jì)了與文本有關(guān)的說(shuō)話人確認(rèn)系統(tǒng),此系統(tǒng)是會(huì)提示用戶說(shuō)什么話,在YOHO中使用的是:“合成塊”短語(yǔ)的語(yǔ)法。
這個(gè)數(shù)據(jù)庫(kù)的環(huán)境是“辦公環(huán)境”。另一方面,它還滿足在噪聲的環(huán)境和遠(yuǎn)距離麥克風(fēng)的條件下對(duì)語(yǔ)音做測(cè)試。而這些均滿足了消費(fèi)者的消費(fèi)需要。
國(guó)內(nèi),浙江大學(xué)CCNT實(shí)驗(yàn)室提出和建立了面向移動(dòng)通信環(huán)境的說(shuō)話人識(shí)別語(yǔ)音庫(kù)SRMC(speaker recognition in mobile communicatio n)。
生活中,如果要采集語(yǔ)音的話,就會(huì)常常使用計(jì)算機(jī),麥克風(fēng),還有錄音功能電話機(jī),此外還要有相應(yīng)的調(diào)制解調(diào)器。這些錄音設(shè)備都很普通且常見(jiàn)。
我們?cè)撛鯓尤ピu(píng)價(jià)和使用一個(gè)標(biāo)準(zhǔn)的語(yǔ)音數(shù)據(jù)庫(kù)?我們需要對(duì)評(píng)價(jià)下個(gè)定義。如評(píng)價(jià)的細(xì)節(jié)、訓(xùn)練和測(cè)試數(shù)據(jù)集的分割。在特定條件(如訓(xùn)練和測(cè)試采用不同的麥克風(fēng))下進(jìn)行系統(tǒng)性能評(píng)價(jià),需要有足夠的錄音數(shù)據(jù)。

2 聲紋識(shí)別系統(tǒng)
2.1 實(shí)驗(yàn)設(shè)計(jì)
由于實(shí)驗(yàn)條件的限制,本課題的語(yǔ)音庫(kù)是自己創(chuàng)建的,實(shí)驗(yàn)用來(lái)訓(xùn)練和測(cè)試的說(shuō)話人錄音,大部分是班級(jí)同學(xué)和同一實(shí)驗(yàn)室的同學(xué)。在這個(gè)實(shí)驗(yàn)中我們使用的是普通話,我們中每一個(gè)人說(shuō)話速度和音量都處于正常情況。實(shí)驗(yàn)語(yǔ)音是在兩天時(shí)間內(nèi)采集得到的。采集環(huán)境是實(shí)驗(yàn)室,一共有十個(gè)同學(xué)進(jìn)行錄音。男女比例是一比一。在本實(shí)驗(yàn)中,我們盡量保持實(shí)驗(yàn)室環(huán)境安靜,假設(shè)我們采集的聲音都是純音,沒(méi)有噪音。實(shí)驗(yàn)中用到的錄音軟件是cool edit 2000,用的錄音設(shè)備是普通的立體聲麥克風(fēng)和COMPAQ筆記本電腦,我們把采樣頻率定為8000Hz,每一幀的幀長(zhǎng)定為256個(gè)點(diǎn),幀之間的距離定為80點(diǎn),用16比特量化方式進(jìn)行量化。采樣之后,得到了標(biāo)準(zhǔn)化的數(shù)字語(yǔ)音,這個(gè)實(shí)驗(yàn)中,用到的語(yǔ)料是阿拉伯?dāng)?shù)字。包含之間的數(shù)字,每個(gè)人的語(yǔ)音是1個(gè)阿拉伯?dāng)?shù)字,每個(gè)人每一天要有9次朗讀機(jī)會(huì)。我們把獲得的所有的數(shù)據(jù)樣本存儲(chǔ)在計(jì)算機(jī)的硬盤(pán)中,拿出第一天的語(yǔ)音來(lái)進(jìn)行訓(xùn)練使用,把第二天的語(yǔ)音用來(lái)做測(cè)試。每一個(gè)數(shù)字錄音看做一個(gè)單位來(lái)進(jìn)行測(cè)試。本文的實(shí)驗(yàn)中利用阿拉伯?dāng)?shù)字1~9的語(yǔ)音單元構(gòu)成的隱馬爾可夫模型。建市了與文本有關(guān)的身份確認(rèn)系統(tǒng)。如圖1所示。
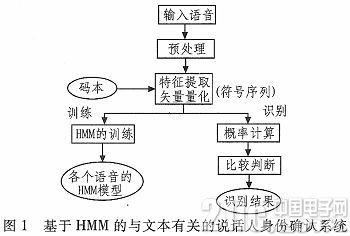
首先錄制語(yǔ)音,采集語(yǔ)音,建立語(yǔ)音模板庫(kù),在實(shí)驗(yàn)室環(huán)境下,采集參加訓(xùn)練和識(shí)別的說(shuō)話人語(yǔ)音。分別建立兩個(gè)數(shù)據(jù)庫(kù)。第一天錄音存儲(chǔ)為Xi,第二天錄音存儲(chǔ)為Ri。分別存儲(chǔ)在計(jì)算機(jī)的硬盤(pán)中的錄音DIY資料文件夾下。語(yǔ)音庫(kù)是用來(lái)存儲(chǔ)說(shuō)話人的語(yǔ)音。當(dāng)需要識(shí)別時(shí)可以用來(lái)識(shí)別說(shuō)話人身份。隨后將語(yǔ)音送至預(yù)處理功能模塊。
其次對(duì)數(shù)字化語(yǔ)音進(jìn)行預(yù)處理,此模塊的任務(wù)語(yǔ)音信號(hào)的數(shù)字化處理,把處理過(guò)的語(yǔ)音拿來(lái)端點(diǎn)檢測(cè)。預(yù)處理過(guò)程包含去除語(yǔ)音信號(hào)的噪聲、對(duì)信號(hào)進(jìn)行預(yù)加重、加窗、分幀等。經(jīng)過(guò)加窗這一步驟之后,得到了一幀幀的語(yǔ)音序列,然后進(jìn)行預(yù)加重處理。把信號(hào)做預(yù)加重處理是為了把信號(hào)中的高頻部分提取出來(lái),這樣做整個(gè)頻譜就會(huì)變得平坦起來(lái),然后在全部的頻帶中一直保持這種平坦,這個(gè)時(shí)候我們可以用相同的信噪比求得頻譜。這樣都完成之后就可以頻譜分析了。預(yù)加重濾波器的形式如:
H(z)=1-μz-1 (1)
式(1)中,μ的值在本實(shí)驗(yàn)中選取0.937 5。引進(jìn)了預(yù)加重參數(shù)μ,可以看出,有利于提高說(shuō)話人的識(shí)別率。表2中可以看到不同預(yù)加重參數(shù)下的識(shí)別率。
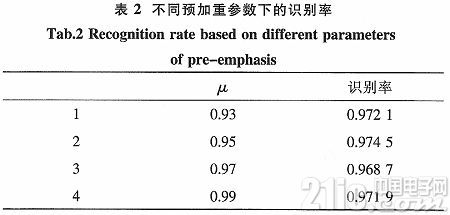
由表2可知,μ值改變,識(shí)別率也在改變。μ=0.95時(shí),識(shí)別率最高。本實(shí)驗(yàn)選取的預(yù)加重參數(shù)值在0.93~0.95之間。
接下來(lái)是對(duì)語(yǔ)音信號(hào)分幀加窗。因?yàn)檎Z(yǔ)音信號(hào)不是平穩(wěn)的信號(hào),假定語(yǔ)音信號(hào)在10~30 ms之間是平穩(wěn)的。為了得到短時(shí)的語(yǔ)音信號(hào),對(duì)語(yǔ)音信號(hào)進(jìn)行加窗計(jì)算。本課題主要選用的是漢明窗。漢明窗顯示了一個(gè)好的窗口的優(yōu)點(diǎn)。其在時(shí)域中波形細(xì)節(jié)不容易丟失,且能防止泄露。漢明窗函數(shù)式:
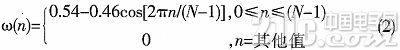
經(jīng)過(guò)前面的一些處理之后,采集的語(yǔ)音信號(hào)就被分割成一幀幀的短時(shí)的加窗信號(hào),把這些信號(hào)假設(shè)成隨機(jī)平穩(wěn)的信號(hào),然后提取語(yǔ)音特征參數(shù)。
提取出來(lái)的語(yǔ)音參數(shù),對(duì)其端點(diǎn)檢測(cè)。此時(shí),先設(shè)置門限,依據(jù)短時(shí)能量和過(guò)零率的公式,求出來(lái)短時(shí)能量值和過(guò)零率值。然后用手工方法在MATLAB上去除語(yǔ)音信號(hào)中的靜音段和噪音語(yǔ)段來(lái)進(jìn)行端點(diǎn)檢測(cè)。
對(duì)系統(tǒng)的輸入信號(hào)進(jìn)行判斷,準(zhǔn)確地找到語(yǔ)音信號(hào)的起始點(diǎn)和終止點(diǎn)的位置。除去語(yǔ)音中的雜亂語(yǔ)音段,只有這樣才能采集到真正的語(yǔ)音數(shù)據(jù),減少數(shù)據(jù)冗余和運(yùn)算量,并減少處理時(shí)間。如表3所示。在這里本課題用的是雙門限法。將短時(shí)平均能量和短時(shí)平均過(guò)零率結(jié)合起來(lái),進(jìn)行端點(diǎn)檢測(cè),可以很好的檢測(cè)語(yǔ)音是否開(kāi)始和結(jié)束。



評(píng)論