基于MML電子病歷存儲模型研究

設計實現對象一關系數據庫時,每個對象都要考慮采用何種類型,是否使用用戶自定義類型(UDT)。對每個對象可能有的查詢/操作認真分析,據此設計用戶自定義函數(UDF)。例如,通過名字Bob Smith查詢病人電話列表,下面列出對象一關系的SQL語句:SELECT o.phoneFROM oo.person o WHERE o.hasName('Bob','Smith');這里必須為oo.person對象設計該hasName自定義方法,不然將無法進行此查詢。在對象一關系模型中需要設計大量自定義方法。在傳統關系型模型,該查詢可以通過下列語句實現:SELECT o.phone FROM person p,person-name n person-phom o WHERE n.name='Bob Smith'AND n.id=p.id AND o.id=p.id;需要連接3個表。
對象一關系模型中表的查詢/操作比傳統的關系型模型簡單直觀,但是需要編程實現大量的自定義函數。此外由于N∶M關系是通過在對象中添加嵌套表或數組實現的,設計人員必須認真考慮應該將其添加到該關系相關的哪個對象上。
4.2 時延分析
對兩個均包含100份MML電子病歷的對象一關系數據庫和傳統關系型數據庫進行比較。選取下面4組典型的數據庫操作分別在2個數據庫上運行,以比較性能:
(1)使用簡單搜索規則對單個病人進行數據檢索,例如通過名字檢索病人數據;
(2)多病人數據檢索查詢;
(3)檢索MML emr tab表數據(不是病人數據);
(4)增、刪和更新數據。
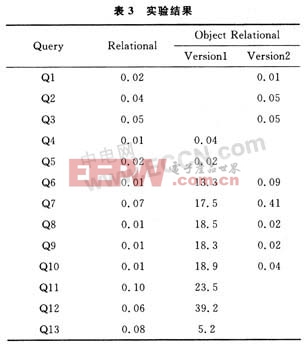
使用Oracle9i實現2個數據庫,共進行13組操作,每組運行5次取平均時間。實驗結果表3所示,對象一關系模型包含2列,2個版本的差別在于版本二只在必須的情況下使用用戶自定義函數(UDF)。Q1到Q3屬于分組一,在兩種數據庫中都沒有使用UDF。Q4到Q6屬于分組二,分別對oo_person_tab,oo_organization和oo_MML表進行多病人數據檢索查詢。以Q4為例,該查詢需要掃描整個oo_person_tab表以便執行hasName()。Q4的時間復雜度為O(n)。使用類似hasName(),hasID()等UDF的查詢依賴于表的行數。關系型數據庫采用優化技術,時間復雜度為O(log(n)),對對象一關系數據庫的優化由于UDF非常復雜,難于優化。Q7,Q8和Q9屬于分組三,在對象一關系數據庫的2個實現中也同樣發現,版本二由于只在必須時使用UDF,執行時延得以大幅縮短。分組四同樣是使用UDF的緣故,執行效率傳統關系型數據明顯高于對象一關系型。
5 結 語
設計層次上,對象一關系模型因為表的數量比較少而顯得比較簡潔,但設計的過程不如關系型模型直觀,設計人員需要認真考慮對象間的關系應當如何表示。實現層次上,對象一關系模型需要提供支持多值屬性和關系的搜索方法的具體實現,可以使用嵌套表或數組表示;關系型模型則采用獨立表,不需要設計人員編寫代碼。
查詢和執行方面,在對象一關系模型上的查詢表達式簡潔直觀,但需要事先編程實現對象方法。傳統關系型模型的數據庫操作效率要高過對象一關系模型。綜上,因為基于MML的電子病歷系統的原型非常復雜,使用對象一關系型存儲模型可以簡化數據庫的設計和實現,縮短開發周期;同時可以結合傳統關系型的優點,只在必須用用戶自定義方法的時候才使用UDF,一方面可以提高執行效率;另一方面可以盡量避免因為沒有提供必要的UDF而不能執行電子病歷靈活多樣的數據庫查詢操作。
更多醫療電子信息請關注:21ic醫療電子頻道

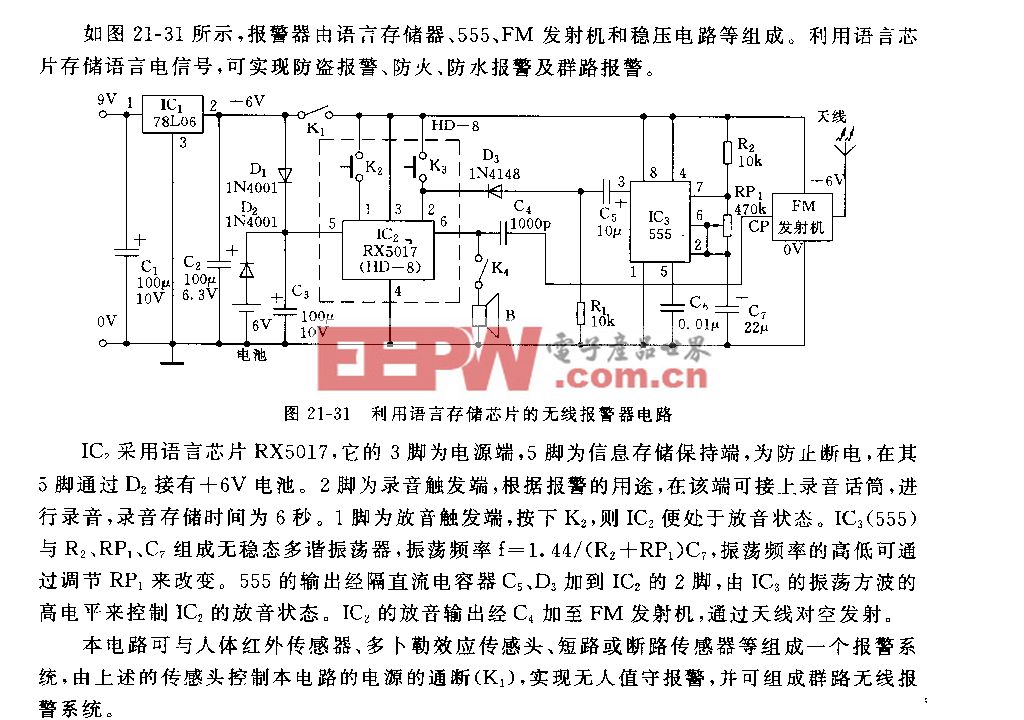

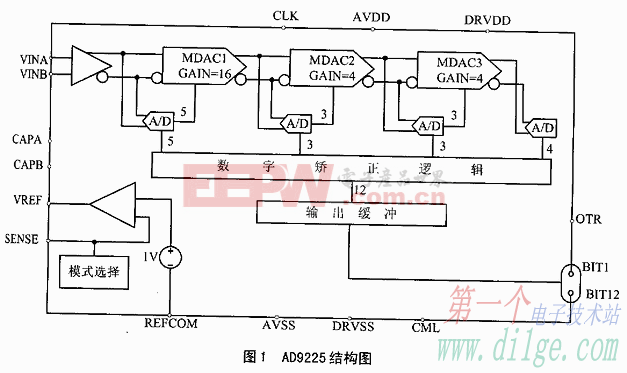

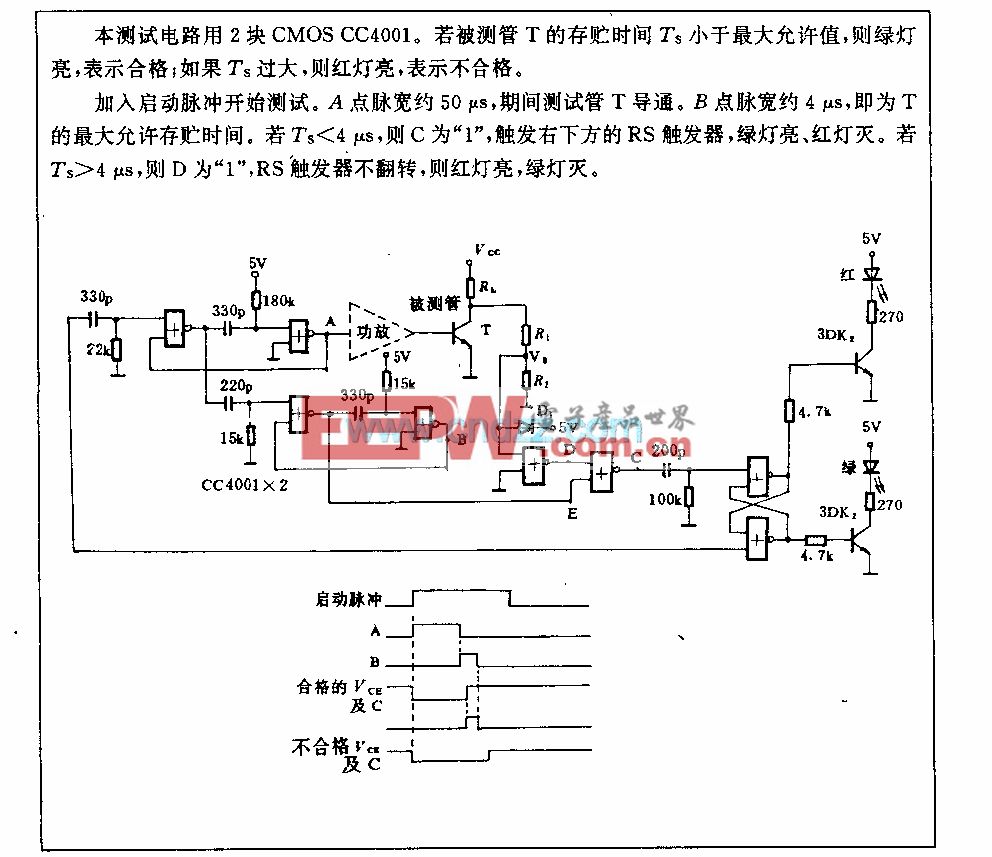
評論