基于并行計(jì)算的木馬免疫算法研究

實(shí)驗(yàn)1:設(shè)定其他的參數(shù)不變,在不同的自體規(guī)模(即Ns)下進(jìn)行實(shí)驗(yàn),仿真結(jié)果如表2所示。本文引用地址:http://www.104case.com/article/193037.htm
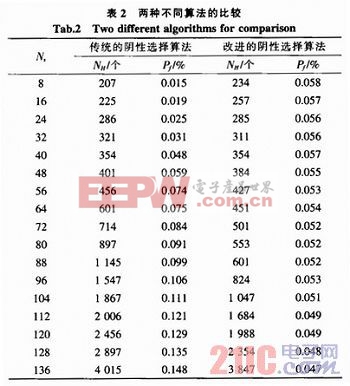
由表2可以看出,當(dāng)自體規(guī)模從8增加到136的時(shí)候,傳統(tǒng)算法產(chǎn)生的候選檢測(cè)器數(shù)量大大增加,從207個(gè)增加到了4 015個(gè),增加了18倍。而檢測(cè)失敗率也從0.015%增加到了0.148%,增加了將近9倍;而用本文改進(jìn)的算法所產(chǎn)生的候選檢測(cè)器數(shù)量只從234個(gè)增加到3 847個(gè),增加了15倍,而失敗率反而從0.058%降低到了0.047%,檢測(cè)失敗率下降了17%;雖然在自體規(guī)模只有8個(gè)的時(shí)候,改進(jìn)算法產(chǎn)生了234個(gè)候選檢測(cè)器,多于傳統(tǒng)算法,這是因?yàn)楦倪M(jìn)算法較復(fù)雜,可能會(huì)增加冗余的檢測(cè)器,但是隨著自體規(guī)模的增加,候選檢測(cè)器的數(shù)量能保持較少的增長(zhǎng)率,說明改進(jìn)算法的收斂性較小,收斂效果較好,而且也提高了檢測(cè)成功率。
實(shí)驗(yàn)2:設(shè)定隨機(jī)字符串長(zhǎng)度L和自體規(guī)模Ns不變,改變匹配位數(shù)r的長(zhǎng)度,對(duì)比兩種算法產(chǎn)生的候選檢測(cè)器數(shù)目NH和檢測(cè)時(shí)間t,結(jié)果如表3所示。
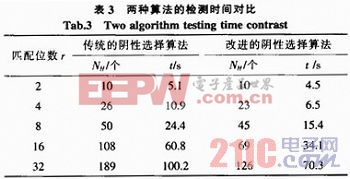
由表3可以看出,在字符串L位數(shù)和自體規(guī)模Ns不變的情況下,當(dāng)匹配位數(shù)r增加,傳統(tǒng)算法所產(chǎn)生的候選檢測(cè)器數(shù)目大大增加,增加了將近18倍,檢測(cè)時(shí)間增加了18倍,效率明顯降低;采用文中的多屬性特征區(qū)域匹配方式,候選檢測(cè)器集合數(shù)目增加了只有11倍,并且改進(jìn)算法引入了并行計(jì)算的方式,檢測(cè)時(shí)間增加了14倍,而且低于傳統(tǒng)算法的檢測(cè)時(shí)間。從這里可以看出,新算法在匹配位數(shù)r增加的情況下,系統(tǒng)效率影響較小,能有效改善系統(tǒng)性能。
3 結(jié)束語
陰性選擇算法隨著匹配位數(shù)r的增加和字符串L的增加,匹配次數(shù)呈指數(shù)形式增加,匹配效率明顯不足,并且會(huì)產(chǎn)生大量的候選檢測(cè)器,使得該算法時(shí)間復(fù)雜度太大,論文提出一種改進(jìn)的陰性選擇算法,把字符串分為多個(gè)特征區(qū)域,每個(gè)特征區(qū)域之間采用r連續(xù)位匹配方式再次匹配,同時(shí)采用并行計(jì)算,實(shí)驗(yàn)結(jié)果表明改進(jìn)的陰性選擇算法在匹配位數(shù)和隨機(jī)字符串位數(shù)增加時(shí),候選檢測(cè)器增加速度較平緩,系統(tǒng)負(fù)擔(dān)增加較緩慢,因此具有較好的檢測(cè)效率。


評(píng)論