說話人語音特征子空間分離及識別應用

![]()
4 實驗分析
需要通過實驗分析的問題包括:(1)基于特征子空間識別方法的有效性?(2)子空間維數與識別性能的關系?并確定一個最佳子空間維數。(3)不同子空間距離測度下識別性能的比較分析(4)不同特征參數,例如LPCC、MFCC情況下識別性能分析?(5)不同長度測試語音輸入時,說話人識別性能的變化趨勢?(6)在相同訓練語音數據、實驗環境和條件下,子空間方法和VQ、GMM等其他方法的識別性能比較分析。
4.1 實驗數據與條件
語音數據選擇SD2002一D2數據庫,該數據庫中包含了在普通實驗室環境下通過計算機聲音系統采集得到的40個說話人的280條語音片段,其中,男聲26人,女聲14人,每人分別有7段語音,每段語音包括停頓間隙長度為12秒。語音采樣率為11025Hz,16位量化,單聲道輸入。實驗中,每說話人的前4段語音用于模型訓練,后3段用于測試。
在模型訓練和識別測試中,預處理部分首先消除輸入語音信號的背景噪聲,保留純語音數據,并進行權重系數為0.97的高頻提升。短時分析采用27ms哈明窗,幀移步長18ms。特征參數LPCC和MFCC為16階,其中,LPCC由16階LPC線性預測系數推導得到,MFCC是基于Mel頻率尺度的倒譜系數,通過計算Mel頻率域均勻分布的19個三角濾波器組的DFT輸出,并經DCT變換得到,實驗中選取第l~16個系數作為特征參數。實驗中,特征子空間采用說話人的前4段語音信號進行訓練,其純語音成分的長度平均為32秒。測試實驗采用每說話人的后3段語音。
4.2 不同距離測度和特征參數下子空間維數與識別性能關系分析
根據PCA原理,特征子空間可以選擇較大散度本征值對應的本征向量為基底,這樣可以提高子空間之間的非相關性。但是,選擇的基向量不能過少,否則可能引起子空間不能充分表示語音特征的分布結構。因此,需要在實驗分析子空間維數與識別性能關系的基礎上確定一個最佳子空間維數。
將散度本征值按大小順序排列,并選取前面幾個較大本征值所對應的本征向量作為子空間的基向量進行分析。圖2顯示了采用LPCC特征參數以及兩種不同子空間距離測度情況下系統誤識率隨子空間維數變化的情況,其中測試語音長度為3秒。可以看到,第二種子空間距離測度總體上比第一種距離測度更優越,但兩種測度下都顯示當子空間維數為6時系統的誤識率最低。圖3顯示了采用第二種子空間距離測度時,兩種特征參數LPCC和MFCC所對應的識別性能隨維數變化的情況,其測試語音長度也是3秒。可以看到,MFCC參數相對而言比LPCC要優越些,但差距并不大。另外,從圖3同樣可以看到當子空間維數為6時系統具有最佳識別性能。
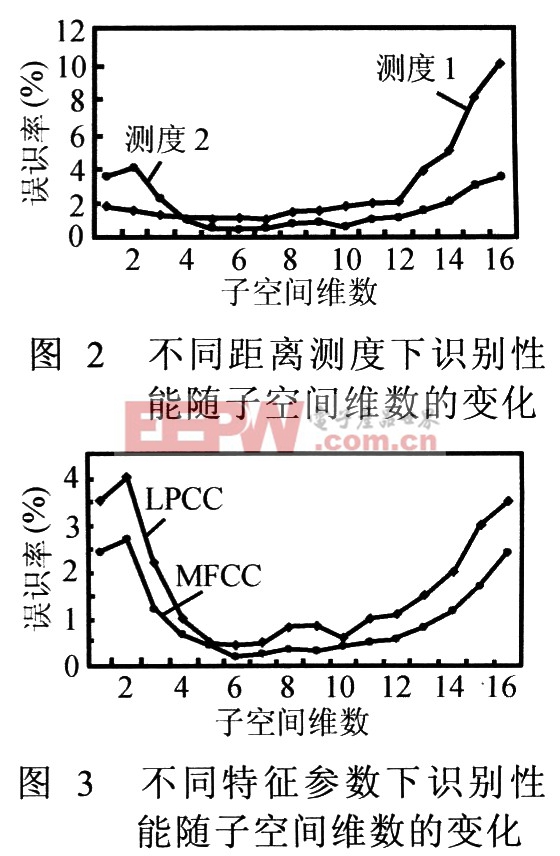
根據以上實驗結果可以得出這樣得結論:基于子空間分離的說話人識別方法是有效的,但其識別性能隨子空間維數是變化的,當維數為6時識別性能達到最佳,誤識率僅為0.189%。因此,在以下的實驗分析中子空間維數均采用6。
4.3 不同特征參數下識別性能與測試語音長度關系分析
實際應用中,測試語音的長度不是固定的。因此,衡量一個說話人識別系統的識別性能必須針對不同的測試語音長度進行分析。
圖4顯示了當采用兩種特征參數LPCC和MFCC時,不同測試語音長度下系統的識別性能情況。其中,子空間距離的計算采用第二種測度,即d2(Vt,SF)。
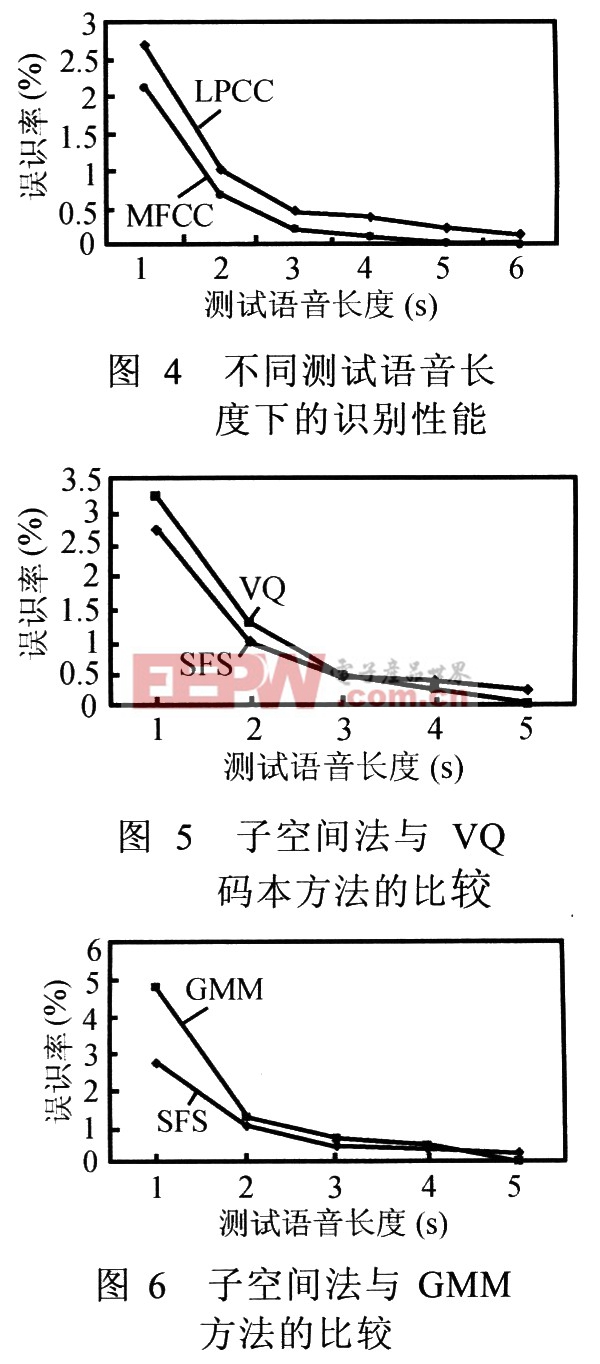
從圖4可以看到,所有測試語音長度下系統都能夠得到較好的識別性能,誤識率均在3%以下,當測試長度達到5秒時,MFCC對應的誤識率趨于零,但LPCC對應的誤識率下降趨勢慢一些。另外可以看到,采用MFCC作為特征參數時的識別性能比LPCC時優越,但差距并不大。
4.4 子空間方法與其他方法的比較分析
說話人識別的根本性問題是模型和特征參數,即用怎樣的方法去描述說話人的語音特征以及采用什么樣的參數表示說話人語音特征的問題。但到目前為止,還沒有提出專門用于說話人識別的語音特征參數和模型,常用的文本無關說話人模型有GMM和VQ。
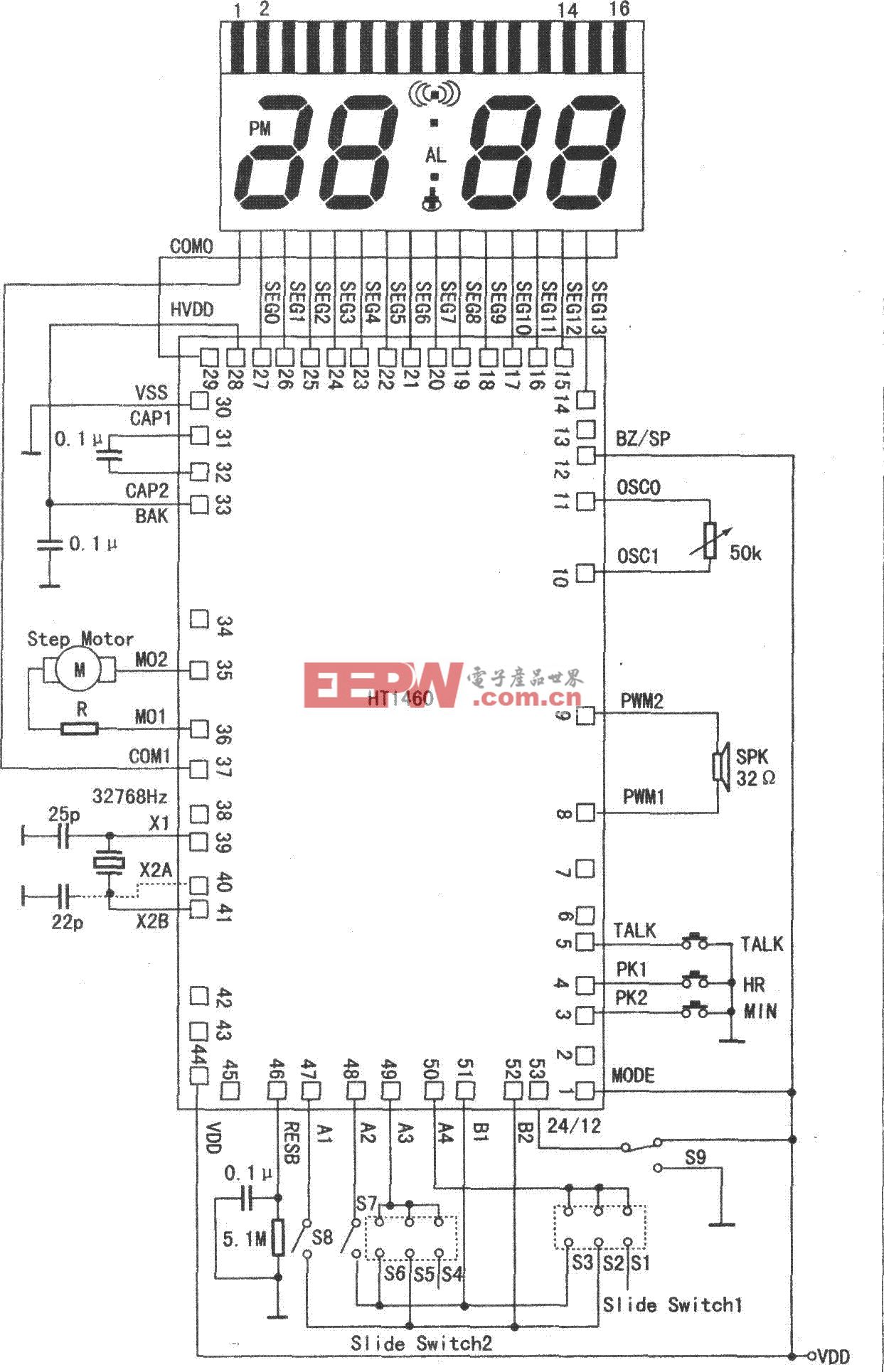
圖5和圖6分別顯示了子空間方法與VQ和GMM方法的比較。其中,VQ碼本的碼字數為128,GMM的混合分量數為16。可以看到,子空間方法在測試語音長度小于3秒時其識別性能優于其他方法,而在大于等于3秒時則相反。這個結果說明,GMM和VQ等完全基于統計聚類的方法由于運用了說話人語音的統計特性,所以對于較長的測試語音有較可靠的識別性能,但當測試語音較短時,由于無法提供可靠的統計特性進行匹配,誤識率就很快下降。而子空間方法是根據說話人語音特征的分布散度得到的一種空間結構性模型,由于不是完全依靠語音特征的統計特性,所以在較短的測試語音時也能夠得到較好的識別性能。
5 結論
依據PCA原理,從說話人語音特征觀察空間根據其分布散度特性分離出特征子空間作為說話人的一種結構性語音模型是有效的。當采用MFCC參數,測試語音長度為5秒時系統誤識率趨于零。特別是在小于3秒的短時測試語音情況下,其識別性能優于其他方法。另外,子空間方法在識別時的計算量明顯小于其他方法。
說話人識別和語音識別中存在同樣的核心問題,即沒有解決說話人個性特征和語義特征的提取和描述,這個問題極難。目前主要采用的特征參數LPCC、MFCC等反映了語音信號的頻譜特征,既包含語義特征信息,又包含個性特征信息,在具體應用中只是根據不同的識別任務進行語義特征或個性特征的歸一化處理,主要的歸一化處理通過語音模型訓練進行。顯然,這樣的傳統方法為了使語音模型很好地表示說話人的語音特征必須通過大量的語音樣本進行訓練,測試時需要的語音數據也比較多。但是,實際應用中系統往往沒有足夠的數據用于這類統計模型的訓練和識別,因此,在考慮如何提高說話人識別系統魯棒性的同時,需要研究少量語音數據前提下的訓練和識別問題。基于子空間分離的說話人識別方法在短測試語音長度下有一定優勢,但在較長測試語音情況下識別性能提高不快。因此,今后將考慮通過子空間映射,在子空間建立說話人統計模型的方法來提高總體識別性能,特別是較長測試語音長度下的識別性能。



評論