說話人語音特征子空間分離及識別應用

隨著電話銀行等網絡電子消費的普及,說話人識別作為一種有效的身份認證手段,其技術特點和優越性越來越明顯,在國防安全、司法和金融等各應用領域的價值越來越顯得重要。目前說話人識別的主要方法一般通過在語音特征觀察空間建立說話人模型進行,如基于VQ的碼本模型識別方法、基于GMM模型的識別方法以及其他一些方法,這些方法大都利用了說話人語音特征的統計特性。但是,說話人識別應用中存在的兩個主要問題是:(1)由于語音特征的時變性,模型訓練時期和實際識別時期語音特征發生變化而導致識別性能的下降,而目前這些方法只能在一定程度上處理這種變化;(2)實際應用中往往需要能通過較短的語音及時識別說話人身份,但目前這些方法一般需要輸入3秒以上的語音才能得到較高的識別率。
語音信號中包含語義和說話人個性這兩大特征,如果能夠較好地將這兩類特征進行分離,并依據個性特征建立說話人模型,則說話人識別性能將會得到提高并大大增強識別系統的魯棒性,但兩類特征的完全分離非常困難。統計方法建立的模型不可避免地需要較大的數據量進行訓練和識別,在短時測試語音下識別性能下降是必然的。如果能夠建立一種非純粹統計模型或在統計模型的基礎上結合結構性模型則可能會提高短時測試語音條件下的識別性能。
本文依據主元分析(PCA:Principal Component Analysis)原理和說話人語音特征在觀察空間的分布散度提取主要散度向量構造說話人語音特征子空間,將說話人語音特征子空間從觀察空間分離出來。實驗分析了基于特征子空間的說話人識別性能,結果證明了這種方法的有效性,特別是在小于3秒的短時測試語音情況下識別性能明顯優于VQ和GMM等方法。
2 特征子空間分離
基于語音特征子空間分離的說話人識別系統中,說話人模型由特征子空間表示,模式匹配部分則通過計算輸入測試語音特征矢量與子空間的距離進行。特征子空間根據說話人訓練語音提取的特征矢量在觀察空間的統計分布特性,依據PCA原理選取具有較大權值的散度向量構成。
設一個說話人訓練語音集合為{S1,S2,…,SN},每一個訓練語音樣本經過特征提取后形成特征矢量序列,即![]() 如果特征矢量具有P個參數,則特征矢量Vij表示P維觀察空間的一個點,所有的特征矢量
如果特征矢量具有P個參數,則特征矢量Vij表示P維觀察空間的一個點,所有的特征矢量![]() 在觀察空間形成具有一定統計分布特性的點集{V1,V2,…,VM},其中M是說話人所有訓練語音特征矢量的總數。描述說話人語音特征矢量在觀察空間分布的一個主要統計指標是分布散度,它可以由平均特征矢量和自協方差矩陣表示,如下:
在觀察空間形成具有一定統計分布特性的點集{V1,V2,…,VM},其中M是說話人所有訓練語音特征矢量的總數。描述說話人語音特征矢量在觀察空間分布的一個主要統計指標是分布散度,它可以由平均特征矢量和自協方差矩陣表示,如下:
![]()
公式(1)中平均特征矢量V反映說話人所有特征矢量在觀察空問的中心點。公式(2)中自協方差矩陣R是一個P×P正定對稱矩陣,它反映了說話人特征矢量各參數的平均偏離值,因此可以衡量特征矢量在觀察空間的分布散度。
求自協方差矩陣R的本征值{λ1,λ2,…,λP}和相應的本征向量{e1,e2,…,eP},則它們之間的關系如下式(3)~(5)所示。其中φ是由本征向量作為每一列構成的P×P矩陣,A是由本征值構成的對角矩陣。

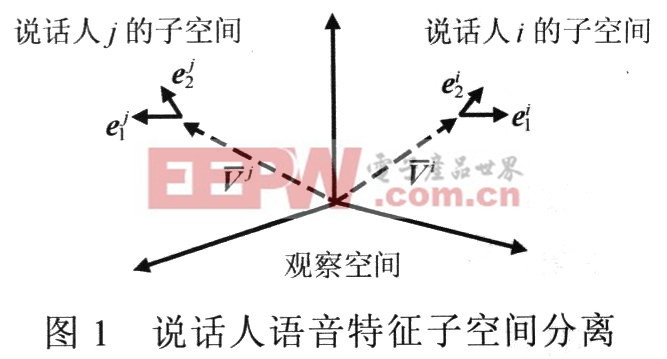
因為本征向量ei,i=1~P是從描述說話人語音特征矢量分布散度的自協方差矩陣計算得到,所以,從空間的角度看,說話人的語音特征分布完全可以由以平均特征矢量V為中心,本征向量ei,i=l~P為正交歸一化基底的子空間描述,如圖1所示。這樣,就從語音特征觀察空問將說話人語音特征子空間分離了出來,不同的說話人具有不同的特征子空間。
雖然計算得到的本征向量個數與觀察空間維數相同,但有些本征向量對應的本征值較小,在表示語音特征分布散度時影響較小。因此,實際應用中可以選擇具有較大散度權值(本征值)的向量構成子空間的基向量。圖1顯示了一個三維觀察空間中分離出的兩個二維說話人特征子空問例子,這些子空間的基底對應前兩個較大的散度權值。第4小節分析了選取不同散度權值本征向量構成子空間情況下的識別性能,結果表明子空間維數并非越多越好。
說話人語音特征子空間本質上是根據訓練語音特征矢量在觀察空間的統計分布特性分析得到的一種結構性說話人模型,各子空間的基底描述了說話人語音特征分布的框架結構。因此,可以認為子空間融合了說話人語音特征的統計特性和結構特性,可由下式(6)表示:
![]()
3 子空間距離測度與模式匹配
系統模式匹配對輸入測試語音與各說話人子空間的相關度進行分析,提供說話人身份的判別依據。設輸入測試語音St相應的特征矢量序列為![]() 則通過計算該特征矢量序列與說話人特征子空間的距離來分析測試語音與子空間的相關度,距離越小,相關度越大。最終的說話人識別判決可以依據最小距離準則進行,即測試語音說話人所對應的子空間應該與測試語音之間的距離最小,即相關度最大。
則通過計算該特征矢量序列與說話人特征子空間的距離來分析測試語音與子空間的相關度,距離越小,相關度越大。最終的說話人識別判決可以依據最小距離準則進行,即測試語音說話人所對應的子空間應該與測試語音之間的距離最小,即相關度最大。
輸入語音特征矢量Vt與子空間的距離測度采用子空問投影距離計算,如下式(7)所示。其中Q是子空間的維數,Q≤P。
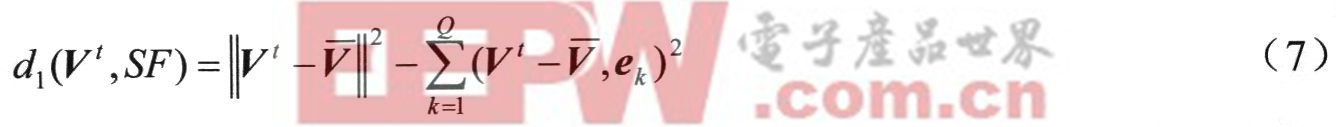
上式第一項是觀察空間特征矢量Vt與說話人語音特征子空間中心矢量V之差向量Vt一V的平方模;第二項是這個差向量Vt一V在子空間各維投影的平方和,代表了這個差向量在子空間上的投影長度的平方。兩項相減就是輸入測試語音特征矢量Vt與子空間的距離。
以上距離測度中采用了訓練語音的平均特征矢量V,使觀察空間特征矢量轉換為適合子空間處理的差向量形式。實際應用中,說話人語音特征是時變的,并引起特征矢量統計分布特性的變化,其表現之一是平均特征矢量隨時問的漂移。從子空間角度看,這個平均特征矢量的變化代表了說話人語音特征子空間的一種整體時變漂移,在計算子空間距離時如果不能及時反映這種變化,將可能引起一定程度的失真,為此,定義第二種距離測度如下:
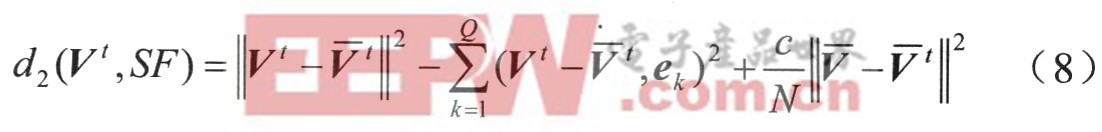
前面兩項的含義與第一種測度d1(Vt,SF)是一致的,但差向量不是根據訓練語音的平均特征矢量V形成,而是由輸入測試語音的平均特征矢量Vt形成。這樣,不僅使觀察空間特征矢量轉換為適合子空間處理的差向量形式,并且使形成差向量的兩個特征矢量在時間上一致起來。但是,子空間是根據訓練語音構造的,其中心特征矢量是訓練語音的平均特征矢量,距離測度中必須反映這一差異。所以,在第二種距離測度中增加第三項描述訓練語音和測試語音特征矢量的平均差異,兩者通過加權系數c結合,其中N是測試語音短時幀個數。因此,這一距離測度不僅描述了特征矢量與說話人特征子空間的距離,而且描述了測試語音特征與子空間所表示的說話人語音特征的平均距離,同時考慮了語音特征的結構性和統計特性差異。加權系數c的選擇使兩類距離對整個測度的影響保持平衡,可以通過各自的統計方差之比計算。
模式匹配通過計算整個輸入測試語音特征矢量序列與子空間的距離進行。利用以上距離測度,輸入測試語音St與說話人語音特征子空問的總距離如下:
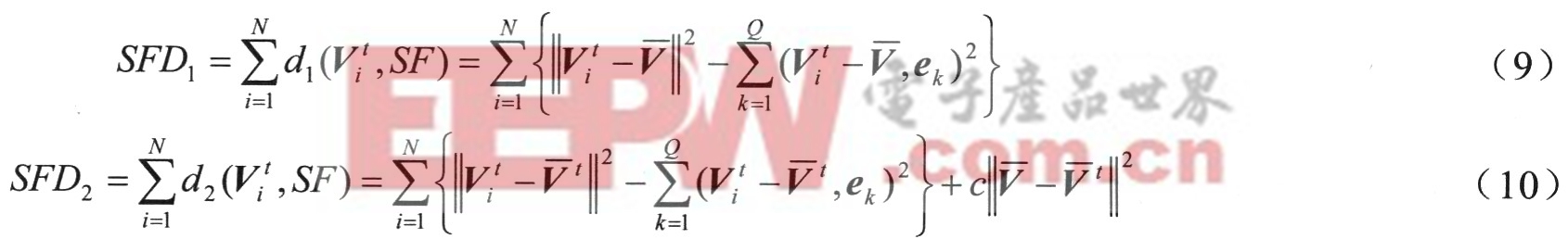



評論