基于TMS320VC5507的語音識別系統實現

摘要:語音識別片上系統可以實現簡單的人機交互和語音控制,在家電、玩具及各種人機交互系統中有著廣泛的應用前景。本文結合漢語語音特點,在TMS320VC5507芯片上實現了高性能特定人與非特定人中小詞匯量孤立詞識別系統。采用基于循環緩沖區的端點檢測算法,雙緩沖區的傳輸方式用于語音錄制和回放,分別采用降低特征維數的DTW算法和基于連續隱含馬爾可夫模型(CDHMM)的多級搜索算法作為核心識別算法,并給出實驗結果。
關鍵詞:特定人;非特定人;片上系統;德州儀器;直接存儲訪問
1 語音識別片上系統概述
隨著數字信號處理技術的發展,語音識別片上系統已成為人們研究的熱點。然而,復雜的系統與硬件需求的矛盾,一定程度上限制了它的應用和推廣。本文針對上述問題,采用相應的識別策略[1],合理安排算法流程,完成了高性能特定人與非特定人識別系統的片上實現。
2 硬件平臺
DSP選型時需綜合考慮運算速度、成本、功耗、硬件資源和程序可移植性等因素。本系統采用美國德州儀器(TI)生產的TMS320VC5507定點DSP作為核心處理器[2],并配合使用PLL時鐘發生器、JTEG標準測試接口、異步通信串口、DMA控制器、通用輸入輸出GPIO端口以及多通道緩沖串口(McBSPs)等主要片內外設。系統硬件平臺如圖1所示。
VC5507 DSP芯片采用先進的多總線結構,內含64 K16 bit的片上RAM和64 KB的ROM;片內可屏蔽ROM固化有引導轉載程序(Bootloader)和中斷向量表等;采用流水線結構提高指令執行的整體速度。與C54x系列DSP不同的是,VC5507DSP的存儲空間包括統一的數據、程序空間和I/O空間,尋址空間可達16 MB;片內包含兩個算術邏輯單元(ALUs),在最高時鐘頻率200 MHz下,指令周期可達5 ns,最高速度可達400 MIPS。
存儲器采用三菱公司生產的M5M29GB/T320VP系列Flash芯片。全片容量2 MW,分為128個扇區,通過外部存儲器接口(EMIF)方式與讀寫時序接入DSP;采用2.7 V~3.6 V單電源供電。該系列Flash支持塊編程操作[3],讀寫速度要快得多,有利于實時性的改善。
基金項目:國家自然科學基金資助項目60572083
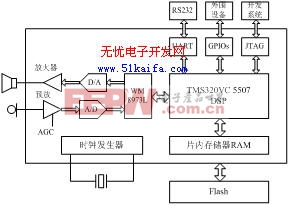
圖1 語音識別系統硬件框圖
A/D、D/A轉換器采用英國Wolfson公司生產的WM8973L芯片。該芯片支持16位A/D、D/A轉換,具有可編程輸入輸出增益控制,可通過軟件設置8~96 KHz的多種采樣頻率[4]。
3 軟件結構
3.1 系統概述
特定人識別系統采用12維MFCC參數作為識別引擎的特征參數,訓練與識別都是在片上實時實現的,系統框架如圖2(a)所示。在訓練階段,由片上實時提取每個詞條的特征參數存放到Flash中作為模板庫。在識別階段,將待識別詞條實時提取特征參數、端點檢測以后,利用動態時間規整(DTW)算法與模板庫中的所有模板進行匹配,選擇失真度最小的模板作為識別結果。當詞表改變時,只需調整Flash存儲方式,算法本身無需改動。

(a) 特定人系統
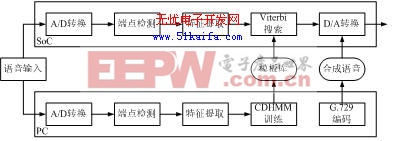
(b) 非特定人系統
圖2 識別系統框架
非特定人識別系統的輸入特征矢量為27維,包括12維MFCC、12維MFCC一階差分、一階對數能量、一階差分能量以及二階差分能量。系統以基于因素的CDHMM模型為基本識別框架,采用Viterbi解碼的幀同步搜索算法進行識別。HMM模型訓練事先在PC機上進行,而Viterbi搜索則在DSP芯片上實時實現,整個系統為雙層結構,如圖2(b)所示。
訓練階段主要完成如下任務:給定一個HMM模型和一組觀察矢量集合,采用迭代算法調整模型參數,使得新模型和給定的觀察矢量集合的似然度最大。首先用初始模型估計觀察矢量由隱含層所有可能的狀態序列輸出的后驗概率,然后根據前一步的估計結果,利用最大似然準則估計新的HMM模型,所得到的參數用作下一次迭代。識別階段采用Viterbi搜索,所構建的識別網絡包括狀態號和狀態連接關系等信息。為了減少網絡搜索的內存占用量,采用每個詞條單獨建立網絡的方法,使得每個詞條的搜索過程可在內存中獨立進行[5]。
3.2 語音傳輸與中斷程序設計
受硬件條件限制,系統的多任務調度是由中斷服務機制完成的。除了Reset和非屏蔽中斷(NMI)外,還設置了兩個DMA通道中斷。其中DMA通道2負責將麥克風錄制的語音數據送至DSP內核進行運算處理;DMA通道3負責將回放語音數據傳送至揚聲器輸出。
在內存中,分別設有兩個128 W的接收緩沖區和發送緩沖區。以接收端為例,對于8 kHz采樣語音,每0.125 ms接收一個16 bits的采樣數據,存入其中一個接收緩沖區中。16 ms后,該接收緩沖區滿,由DMA控制器向CPU發出中斷請求,進行VAD、特征提取等操作。與此同時,另一個接收緩沖區繼續接收語音數據。這種數據傳輸方式又稱為Ping-Pong傳輸,接收和發送分別設置兩個緩沖區,利用等待時隙,當其中一個緩沖區數據傳輸完成,產生中斷時,另一緩沖區繼續工作。這種雙緩沖區傳輸方式可以明顯改善系統實時性能。
3.3 端點檢測
輸入到硬件平臺的語音信號前后經常含有大量靜音或噪聲。出于節省硬件資源的考慮,需要引入端點檢測算法。為了兼顧實時性能和硬件資源占用率,并防止語音切分過嚴而影響識別性能,采用基于循環緩沖技術的四階段語音實時檢測方法,將每幀語音能量與閾值相比較,同時依次存入長度為 的循環緩沖區并記錄當前位置。算法流程如圖3所示,其中 、 、 、 、 為事先設定的閾值,它們是通過大量測試得到的。當檢測到連續 幀語音能量高于閾值時,將循環緩沖區從當前位置斷開,倒退 幀作為語音起始點。

(a) 端點檢測基本流程
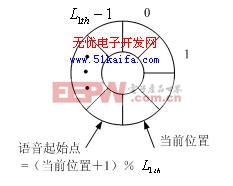
(b) 循環緩沖區設計
圖3 基于循環緩沖區的端點檢測流程
3.4 特定人識別系統的特征提取與DTW模板匹配
實驗表明,采用12維MFCC系數作為特征參數,既可以節省內存空間,又不會對識別率造成很大影響。每幀語音特征參數在內存數據空間中連續存放。采取動態時間規整(DTW)算法,其本質是一種寬度優先的模板匹配過程,即將待識別詞條的特征矢量序列與每個模板進行比較,找到一條總失真度最小的路徑作為識別結果[6]。DTW算法簡單,計算量小,占用內存小,可以解決語速不均勻的問題,適用于特定人小詞匯量的孤立詞識別系統。
3.5 非特定人識別系統的多級Viterbi搜索與硬件資源消耗分析
非特定人識別基線系統難于在片上實現的瓶頸在于識別時間過長。事實上,如果聲學模型構造合理,絕大多數錯誤結果的似然度往往與正確結果相差較遠。因此,本系統采用的基于Viterbi解碼的兩階段搜索策略,可以很大程度上緩解識別時間過長的問題。
第一階段為快速匹配階段。利用較為簡單的208個狀態的單音子聲學模型,給出匹配程度最高的前Nbest個候選詞條,送入第二階段。第一階段所占用的主要內存空間有:詞條的所有特征,在使用27維特征,最大有效語音長度為128幀情況下,需要6.8 KB;輸出分數矩陣,其大小由最大有效語音長度和模型數量決定,是內存開銷最主要的部分,在這里需要占用約62 KB的內存;所有詞條的對數似然度,200詞的情況下為0.8 KB。
第二階段為精確匹配階段,采用較復雜的358狀態雙音子模型,根據第一階段候選詞條構建新的識別網絡,進行搜索識別。為了節約內存占用量,設定第一階段候選詞條數量的上限為8,這樣,第二階段可能出現的有效狀態數量不會超過208個,從而可以使占用內存最大的輸出概率矩陣復用第一階段輸出概率矩陣所占用的那段內存,提高內存使用效率[7]。
4 實驗結果
錄音環境為辦公環境,8 kHz采樣,16 bit量化,每個詞條最大持續時間為2 s,端點檢測的循環緩沖區長度 =7 W。特定人識別系統的測試語音為本實驗室自錄的100個孤立詞人名詞表,識別結果如表1所示。非特定人識別系統的訓練集為863男生連續語音數據,測試語音為200詞的人名詞表。第一階段多候選識別結果如圖4所示。可見,雖然一候選的識別率不足94%,但隨著候選詞條數的增加,正確識別結果幾乎都包含在第一階段前幾選的識別結果中。本文選用的八候選策略的識別率可以達到99.5%。系統最終識別結果如表2所示,識別率僅從基線系統的98.5%下降到97.5%,而識別時間僅為基線系統的30%。
表1 特定人系統識別性能
識別率 | 98.00% | |
識別時間(倍實時) | 0.13 | |
內存空間占用 | 程序空間 | 39 KB |
數據空間 | 22 KB | |
表2 非特定人系統識別性能
基線系統 | 識別率 | 98.50% |
識別時間(倍實時) | 1.00 | |
本系統識別率 | 一階段多候選識別率 | 99.50% |
二階段第一選識別率 | 97.50% | |
識別時間(倍實時) | 0.34 | |
本系統內存空間占用 | 程序空間 | 29 KB |
數據空間 | 94 KB |
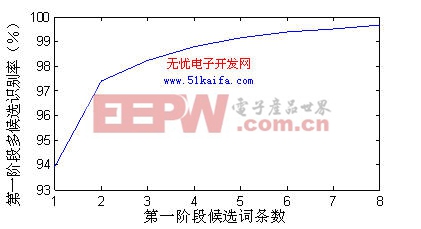
圖4 非特定人系統第一階段多候選識別率
5 結論
本文提出了一種基于定點DSP的特定人與非特定人語音識別片上系統的實現方法。通過降低特征維數,改進語音預處理與識別算法等手段,在保證識別性能的前提下,實現了硬件資源的高效率利用。在運算速度為288 MIPS,工作時鐘為144 MHz的條件下,特定人與非特定人識別系統識別率分別為98%與97.5%,識別時間分別為0.13倍實時和0.34倍實時。
本文的創新點在于:采用基于循環緩沖技術的四階段實時端點檢測算法,以及基于雙緩沖區的語音傳輸方式,在核心識別算法的處理中,選擇合適的特征維數,合理優化識別算法流程,在保證識別性能不受影響的前提下,有效改善了硬件資源占用率與系統實時性能。
參考文獻
[1] Zhu Xuan, Chen Yining, Liu Jia, et al. A Novel efficient decoding algorithm for CDHMM-based speech recognizer on chip [A]. Proceeding of ICASSP [C]. Hong Kong: IEEE Press, 2003, 293-296
[2] SPRS244F. TMS320VC5507 Fixed-Point Digital Signal Processor [S]. Texas: Texas Instruments, 2005
[3] MITSUBISHI LSIs M5M29GB/T320VP-80 BLOCK ERASE FLASH MEMORY [S]. 2001
[4] WM8973L Stereo CODEC for Portable Audio Applications [S]. Edinburgh: Wolfson microelectronics, 2004
[5] 朱璇,陳一寧,劉加,劉潤生. 語音識別片上系統中的多級搜索算法[J]. 電子學報,2004,32(1):150-153.
[6] 陳立萬. 基于語音識別系統中DTW算法改進技術研究[J]. 微計算機信息,2006,第5期,267-269
[7] 王瑞. 基于子詞模型的嵌入式語音識別引擎的設計和實現[D]. 北京:清華大學,2003






評論