高性能32位內核與基于微控制器存儲架構的集成

32 位 MCU 性能差異
本文引用地址:http://www.104case.com/article/170737.htm微控制器(MCU)領域如今仍由 8 位和 16 位器件控制,但隨著更高性能的 32 位處理器開始在 MCU 市場創造巨大收益,在系統設計方面,芯片架構師面臨著 PC 設計人員早在十年前便遇到的挑戰。盡管新內核在速度和性能方面都在不斷提高,一些關鍵支持技術卻沒有跟上發展的步伐,從而導致了嚴重的性能瓶頸。
很多 MCU 完全依賴于兩種類型的內部存儲器件。適量的 SRAM 可提供數據存儲所需的空間,而 NOR 閃存可提供指令及固定數據的空間。
在新 32 位內核的尺寸和運行速度方面,嵌入式 SRAM 技術正在保持同步。成熟的 SRAM 技術在 100MHz 的運行范圍更易于實現。對 MCU 所需的典型 RAM 容量來說,這個速度級別也更具成本效益。
但是標準的 NOR 閃存卻落在了基本 32 位內核時鐘速度之后,幾乎相差一個數量級。當前的嵌入式 NOR 閃存技術的存取時間基本為 50ns (20 MHz)。這在閃存器件和內核間轉移數據的能力方面造成了真正的瓶頸,因為很多時鐘周期可能浪費在等待閃存找回特定指令上。
標準MCU 執行模型——XIP (eXecute In Place)更加劇了處理器內核速度和閃存存取時間之間的性能差距。
大容量存儲中的應用容錯及 SRAM較高的成本是選擇直接從閃存執行的兩個主要原因。存儲在閃存內的程序基本不會被系統內的隨機錯誤破壞,如電源軌故障。利用閃存直接執行還無需為MCU器件提供足夠的 SRAM,來將應用從一個 ROM 或閃存器件復制至目標 RAM 執行空間。
消除差距
理想的情況是,改進閃存技術,以匹配32位內核的性能。雖然當前的技術有一定的局限,仍有一些有效的方法,可幫助架構師解決性能瓶頸問題。
簡單的指令預取緩沖器和指令高速緩存系統在32位MCU設計中的采用,將大大提高MCU的性能。下面將介紹系統架構師如何利用這些技術將16位的MCU架構升級至32位內核CPU。
在 MCU 設計中引入 32位內核
圖 1 介紹了將現有16位設計升級至基本32位內核的情況,顯示了新32 位內核及其基本外設集合之間的基本聯系。由于我們在討論將新的32位處理器內核集成至新的 MCU 設計,我們假設可采用新32位內核采用以下規范。
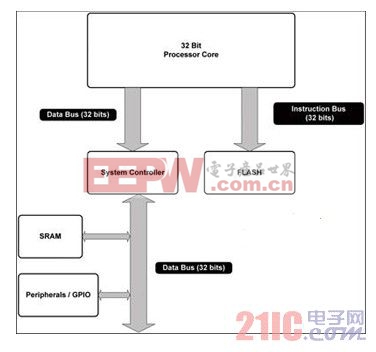
圖1 為現有設計引入32位內核
32 位內核——改良的哈佛架構
與很多 MCU 一樣,新的 32位 內核也采用改良的哈佛架構。因此,程序存儲和數據存儲空間是在兩個獨立的總線構架上執行。一個純哈佛設計可防止數據在程序存儲空間被讀取,該內核改良的哈佛架構設計仍可實現這樣的操作,同時,該32位內核設計還可實現程序指令在數據存儲空間的執行。
在標準總線周期內,程序和數據存儲器接口允許插入等待狀態,有助于響應速度緩慢的存儲或存儲映射器件。








評論